Topik ini membandingkan kinerja kompresi data Lindorm terhadap HBase, MySQL, dan MongoDB open source menggunakan empat set data dunia nyata: pesanan, Internet of Vehicles (IoV), log, dan perilaku pengguna.
Lingkungan pengujian
Lindorm adalah layanan database hyper-converged multi-model yang secara default menggunakan algoritma kompresi zstd dan mendukung kompresi berbasis kamus, yang meningkatkan rasio kompresi dengan mengoptimalkan pengambilan sampel kamus selama pengkodean data.
Tabel berikut menunjukkan versi database dan konfigurasi kompresi yang digunakan dalam pengujian ini.
| Database | Versi | Kompresi default | Catatan |
|---|---|---|---|
| Lindorm | Terbaru | zstd (dioptimalkan) | Kompresi berbasis kamus tersedia |
| Open source HBase | 2.3.4 | Snappy | zstd didukung pada versi Hadoop yang lebih baru tetapi rentan terhadap masalah stabilitas dan core dump; sebagian besar penerapan menggunakan Snappy |
| Open source MySQL | 8.0 | Tidak ada (dinonaktifkan) | zlib tersedia tetapi secara signifikan menurunkan kinerja kueri saat diaktifkan |
| Open source MongoDB | 5.0 | Snappy | zstd tersedia sebagai alternatif |
Pengujian ini hanya mengikuti sebagian spesifikasi benchmark TPC. Hasilnya tidak setara atau tidak dapat dibandingkan dengan hasil pengujian yang sepenuhnya mengikuti spesifikasi benchmark TPC.
Setiap skenario menguji dan membandingkan konfigurasi berikut:
Lindorm dengan zstd (default)
Lindorm dengan kompresi berbasis kamus diaktifkan
Open source HBase dengan Snappy
Open source MySQL dengan kompresi dinonaktifkan
Open source MongoDB dengan Snappy
Open source MongoDB dengan zstd
Kapan menggunakan kompresi berbasis kamus
zstd vs. kompresi berbasis kamus:
| Algoritma | Manfaat | Paling cocok untuk |
|---|---|---|
| zstd (default) | Pengurangan penyimpanan signifikan tanpa konfigurasi tambahan | Semua tipe data |
| Kompresi berbasis kamus | Pengurangan lebih lanjut dibandingkan zstd, dengan biaya langkah pelatihan kamus selama ingesti data | Set data dengan repetisi tinggi antar baris |
Data yang paling diuntungkan oleh kompresi berbasis kamus: set data dengan struktur repetitif antar baris, seperti entri log, bidang telemetri IoV, dan catatan event perilaku.
Untuk hasil konsolidasi di semua skenario, lihat Ringkasan.
Pesanan
Set data
Skenario ini menggunakan set data benchmark TPC-H, yang ditetapkan oleh Transaction Processing Performance Council (TPC) untuk mengevaluasi kinerja kueri analitis.
Unduh tool TPC-H: TPC-H_Tools_v3.0.0.zip
Buat 10 GB data uji:
# Unzip dan build generator data
unzip TPC-H_Tools_v3.0.0.zip
cd TPC-H_Tools_v3.0.0/dbgen
cp makefile.suite makefile
# Edit makefile: atur bidang berikut
# CC = gcc
# DATABASE = ORACLE
# MACHINE = LINUX
# WORKLOAD = TPCH
make
# Buat 10 GB data uji
./dbgen -s 10Perintah ini menghasilkan delapan file .tbl. Pengujian ini menggunakan ORDERS.tbl: 15 juta baris, 1,76 GB.
| Bidang | Tipe |
|---|---|
| O_ORDERKEY | INT |
| O_CUSTKEY | INT |
| O_ORDERSTATUS | CHAR(1) |
| O_TOTALPRICE | DECIMAL(15,2) |
| O_ORDERDATE | DATE |
| O_ORDERPRIORITY | CHAR(15) |
| O_CLERK | CHAR(15) |
| O_SHIPPRIORITY | INT |
| O_COMMENT | VARCHAR(79) |
Buat tabel uji
HBase
create 'ORDERS', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE ORDERS (
O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL
);MongoDB
db.createCollection("ORDERS")Lindorm
-- lindorm-cli
CREATE TABLE ORDERS (
O_ORDERKEY INTEGER NOT NULL,
O_CUSTKEY INTEGER NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY CHAR(15) NOT NULL,
O_CLERK CHAR(15) NOT NULL,
O_SHIPPRIORITY INTEGER NOT NULL,
O_COMMENT VARCHAR(79) NOT NULL,
PRIMARY KEY(O_ORDERKEY)
);Hasil kompresi
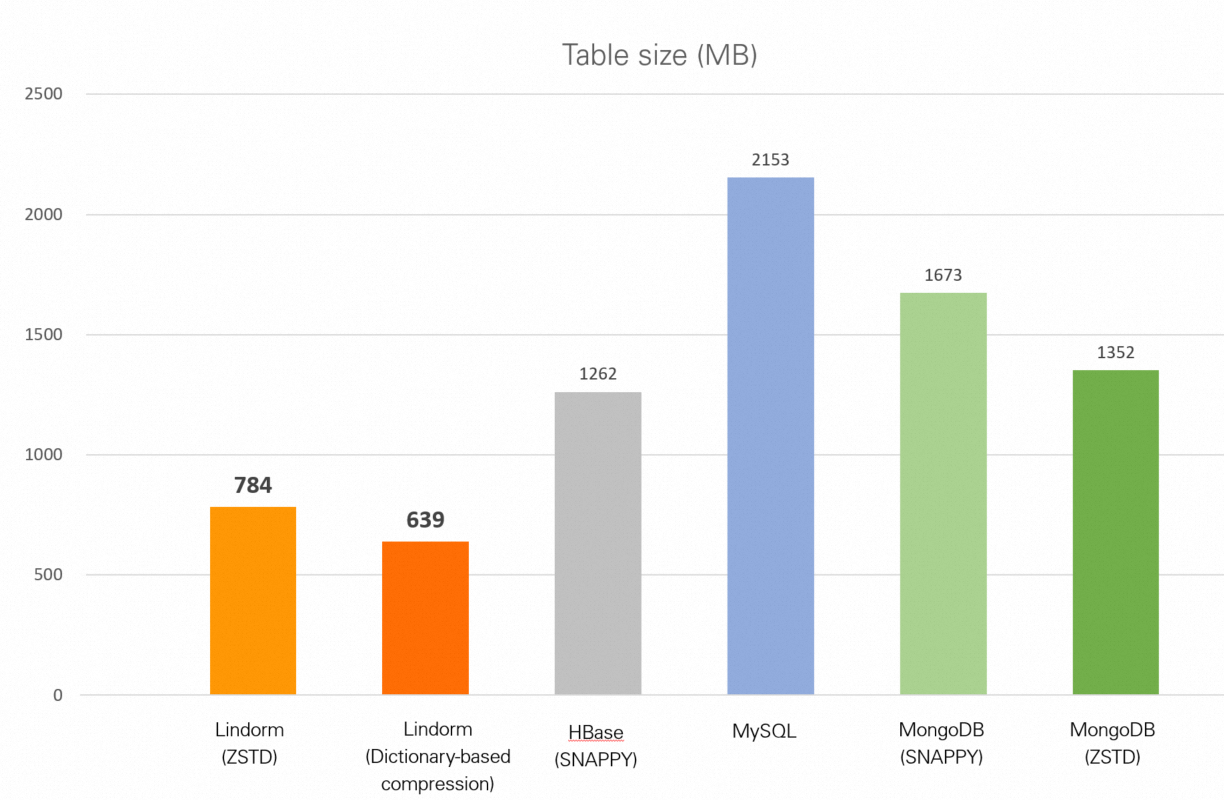
| Database | Ukuran tabel |
|---|---|
| Lindorm (zstd) | 784 MB |
| Lindorm (kompresi berbasis kamus) | 639 MB |
| HBase (Snappy) | 1,23 GB |
| MySQL (tanpa kompresi) | 2,10 GB |
| MongoDB (Snappy) | 1,63 GB |
| MongoDB (zstd) | 1,32 GB |
IoV
Set data
Skenario ini menggunakan set data NGSIM (Next Generation Simulation), yang dikumpulkan oleh U.S. Federal Highway Administration dari lintasan kendaraan di U.S. Route 101. NGSIM banyak digunakan dalam penelitian perilaku mengemudi, analisis arus lalu lintas, prediksi lintasan kendaraan, dan perencanaan keputusan kendaraan otonom.
Unduh NGSIM_Data.csv: 11,85 juta baris, 1,54 GB, 25 kolom per baris.
Buat tabel uji
HBase
create 'NGSIM', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE NGSIM (
ID INTEGER NOT NULL,
Vehicle_ID INTEGER NOT NULL,
Frame_ID INTEGER NOT NULL,
Total_Frames INTEGER NOT NULL,
Global_Time BIGINT NOT NULL,
Local_X DECIMAL(10,3) NOT NULL,
Local_Y DECIMAL(10,3) NOT NULL,
Global_X DECIMAL(15,3) NOT NULL,
Global_Y DECIMAL(15,3) NOT NULL,
v_length DECIMAL(10,3) NOT NULL,
v_Width DECIMAL(10,3) NOT NULL,
v_Class INTEGER NOT NULL,
v_Vel DECIMAL(10,3) NOT NULL,
v_Acc DECIMAL(10,3) NOT NULL,
Lane_ID INTEGER NOT NULL,
O_Zone CHAR(10),
D_Zone CHAR(10),
Int_ID CHAR(10),
Section_ID CHAR(10),
Direction CHAR(10),
Movement CHAR(10),
Preceding INTEGER NOT NULL,
Following INTEGER NOT NULL,
Space_Headway DECIMAL(10,3) NOT NULL,
Time_Headway DECIMAL(10,3) NOT NULL,
Location CHAR(10) NOT NULL,
PRIMARY KEY(ID)
);MongoDB
db.createCollection("NGSIM")Lindorm
-- lindorm-cli
CREATE TABLE NGSIM (
ID INTEGER NOT NULL,
Vehicle_ID INTEGER NOT NULL,
Frame_ID INTEGER NOT NULL,
Total_Frames INTEGER NOT NULL,
Global_Time BIGINT NOT NULL,
Local_X DECIMAL(10,3) NOT NULL,
Local_Y DECIMAL(10,3) NOT NULL,
Global_X DECIMAL(15,3) NOT NULL,
Global_Y DECIMAL(15,3) NOT NULL,
v_length DECIMAL(10,3) NOT NULL,
v_Width DECIMAL(10,3) NOT NULL,
v_Class INTEGER NOT NULL,
v_Vel DECIMAL(10,3) NOT NULL,
v_Acc DECIMAL(10,3) NOT NULL,
Lane_ID INTEGER NOT NULL,
O_Zone CHAR(10),
D_Zone CHAR(10),
Int_ID CHAR(10),
Section_ID CHAR(10),
Direction CHAR(10),
Movement CHAR(10),
Preceding INTEGER NOT NULL,
Following INTEGER NOT NULL,
Space_Headway DECIMAL(10,3) NOT NULL,
Time_Headway DECIMAL(10,3) NOT NULL,
Location CHAR(10) NOT NULL,
PRIMARY KEY(ID)
);Hasil kompresi
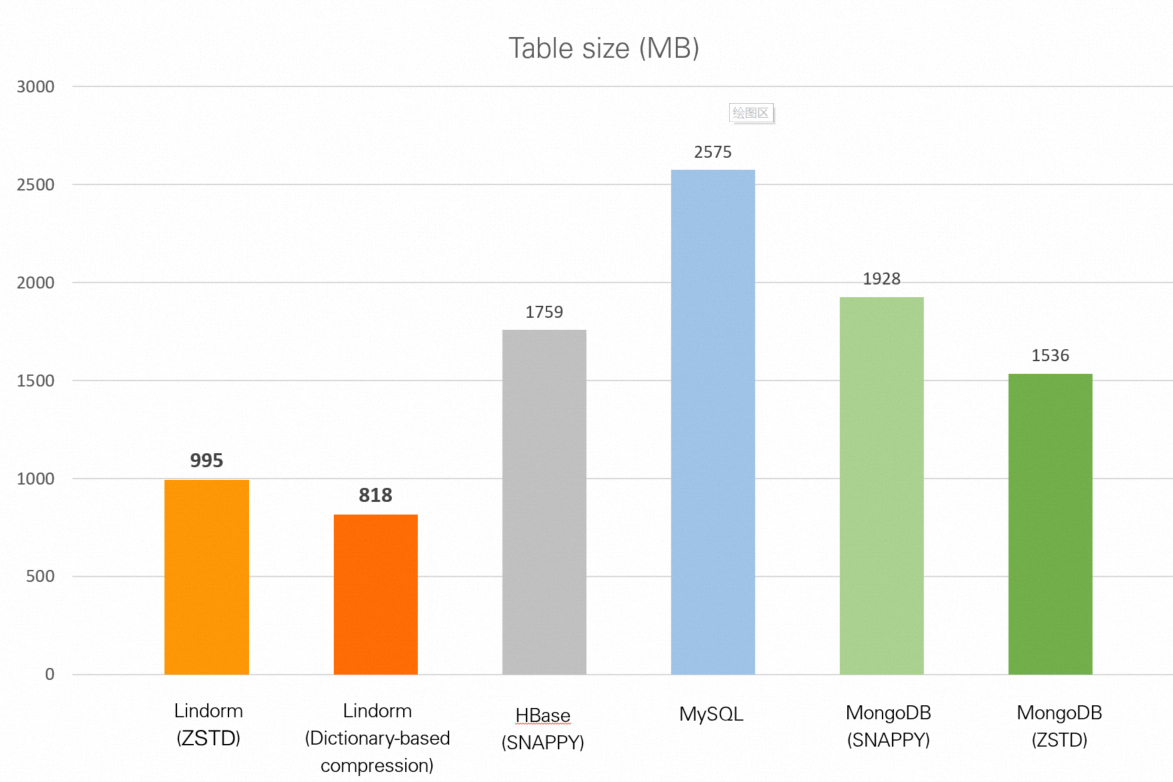
| Database | Ukuran tabel |
|---|---|
| Lindorm (zstd) | 995 MB |
| Lindorm (kompresi berbasis kamus) | 818 MB |
| HBase (Snappy) | 1,72 GB |
| MySQL (tanpa kompresi) | 2,51 GB |
| MongoDB (Snappy) | 1,88 GB |
| MongoDB (zstd) | 1,50 GB |
Log
Set data
Skenario ini menggunakan set data Online Shopping Store - Web Server Logs (Zaker, Farzin, 2019, Harvard Dataverse, V1).
Unduh access.log: 10,36 juta baris, 3,51 GB. Setiap baris merupakan satu entri log. Contoh:
54.36.149.41 - - [22/Jan/2019:03:56:14 +0330] "GET /filter/27|13%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,27|%DA%A9%D9%85%D8%AA%D8%B1%20%D8%A7%D8%B2%205%20%D9%85%DA%AF%D8%A7%D9%BE%DB%8C%DA%A9%D8%B3%D9%84,p53 HTTP/1.1" 200 30577 "-" "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)" "-"Data log bersifat repetitif secara struktural antar baris, sehingga skenario ini menunjukkan peningkatan kompresi tertinggi dari kompresi berbasis kamus.
Buat tabel uji
HBase
create 'ACCESS_LOG', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE ACCESS_LOG (
ID INTEGER NOT NULL,
CONTENT VARCHAR(10000),
PRIMARY KEY(ID)
);MongoDB
db.createCollection("ACCESS_LOG")Lindorm
-- lindorm-cli
CREATE TABLE ACCESS_LOG (
ID INTEGER NOT NULL,
CONTENT VARCHAR(10000),
PRIMARY KEY(ID)
);Hasil kompresi
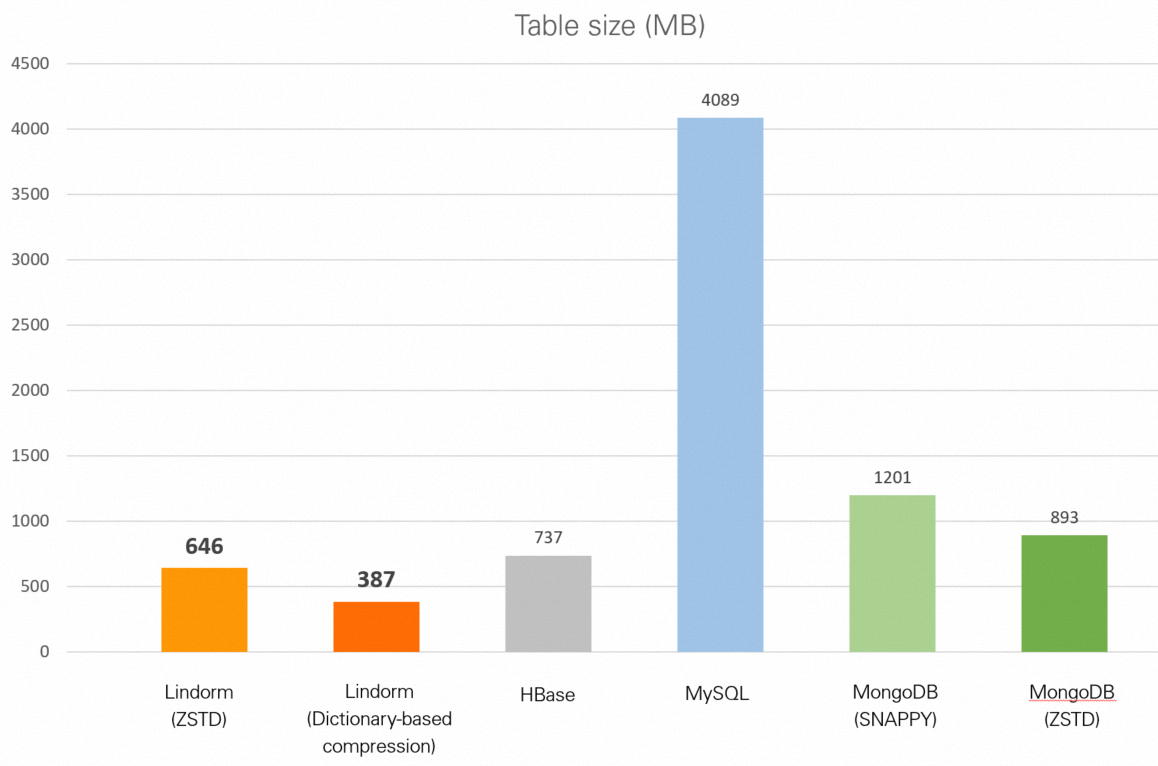
| Database | Ukuran tabel |
|---|---|
| Lindorm (zstd) | 646 MB |
| Lindorm (kompresi berbasis kamus) | 387 MB |
| HBase (Snappy) | 737 MB |
| MySQL (tanpa kompresi) | 3,99 GB |
| MongoDB (Snappy) | 1,17 GB |
| MongoDB (zstd) | 893 MB |
Perilaku pengguna
Set data
Skenario ini menggunakan set data Shop Info and User Behavior data from IJCAI-15 dari Alibaba Cloud Tianchi.
Unduh data_format1.zip dan gunakan user_log_format1.csv: 54,92 juta baris, 1,91 GB.
| Kolom | Nilai contoh |
|---|---|
| user_id | 328862 |
| item_id | 323294, 844400, 575153 |
| cat_id | 833, 1271 |
| seller_id | 2882 |
| brand_id | 2661 |
| time_stamp | 829 |
| action_type | 0 |
Buat tabel uji
HBase
create 'USER_LOG', {NAME => 'f', DATA_BLOCK_ENCODING => 'DIFF', COMPRESSION => 'SNAPPY', BLOCKSIZE => '32768}MySQL
CREATE TABLE USER_LOG (
ID INTEGER NOT NULL,
USER_ID INTEGER NOT NULL,
ITEM_ID INTEGER NOT NULL,
CAT_ID INTEGER NOT NULL,
SELLER_ID INTEGER NOT NULL,
BRAND_ID INTEGER,
TIME_STAMP CHAR(4) NOT NULL,
ACTION_TYPE CHAR(1) NOT NULL,
PRIMARY KEY(ID)
);MongoDB
db.createCollection("USER_LOG")Lindorm
-- lindorm-cli
CREATE TABLE USER_LOG (
ID INTEGER NOT NULL,
USER_ID INTEGER NOT NULL,
ITEM_ID INTEGER NOT NULL,
CAT_ID INTEGER NOT NULL,
SELLER_ID INTEGER NOT NULL,
BRAND_ID INTEGER,
TIME_STAMP CHAR(4) NOT NULL,
ACTION_TYPE CHAR(1) NOT NULL,
PRIMARY KEY(ID)
);Hasil kompresi
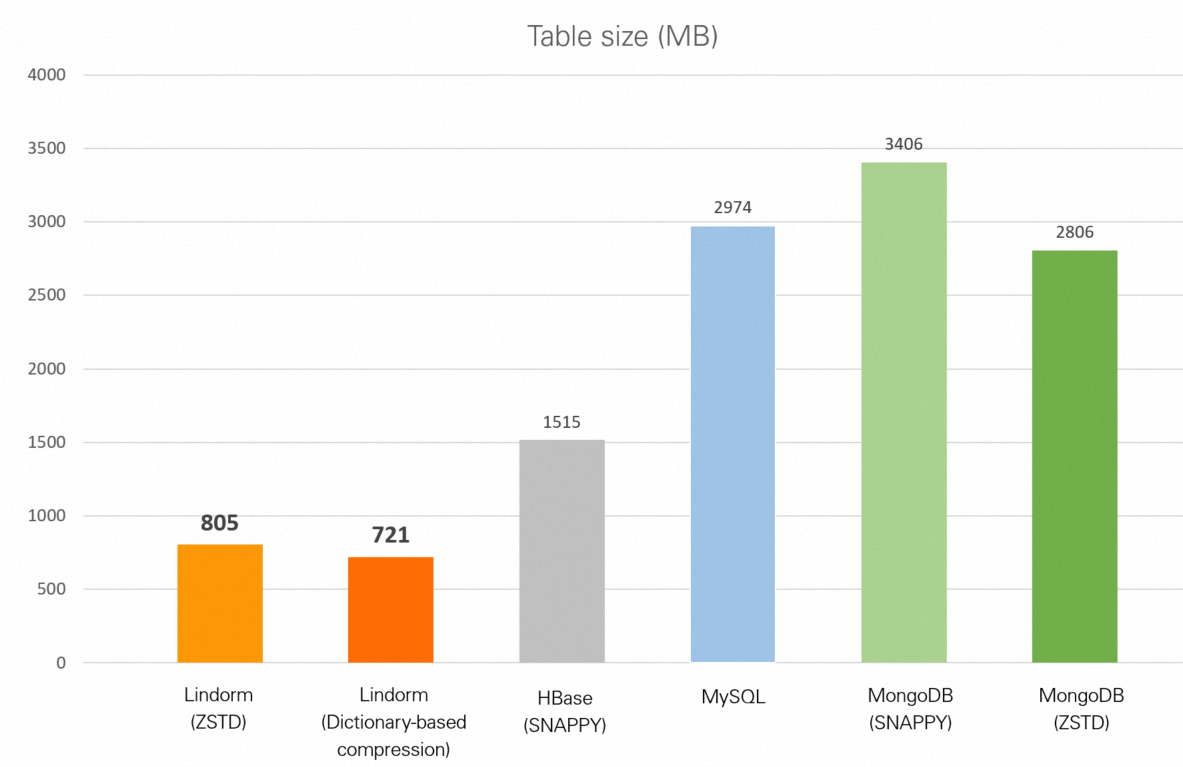
| Database | Ukuran tabel |
|---|---|
| Lindorm (zstd) | 805 MB |
| Lindorm (kompresi berbasis kamus) | 721 MB |
| HBase (Snappy) | 1,48 GB |
| MySQL (tanpa kompresi) | 2,90 GB |
| MongoDB (Snappy) | 3,33 GB |
| MongoDB (zstd) | 2,74 GB |
Ringkasan
Lindorm mencapai rasio kompresi lebih tinggi daripada database open source bahkan tanpa mengaktifkan kompresi berbasis kamus. Dengan kompresi berbasis kamus, Lindorm mencapai rasio kompresi tertinggi di keempat skenario. Dibandingkan dengan konfigurasi default masing-masing database open source, Lindorm dengan kompresi berbasis kamus mengurangi ukuran data tersimpan sebesar:
1–2x lebih cepat daripada HBase sumber terbuka (Snappy)
2–4x lebih tinggi daripada MongoDB sumber terbuka (Snappy atau zstd)
3–10x lebih baik daripada open source MySQL (tidak dikompresi)
Tabel berikut mengkonsolidasikan semua hasil pengujian.
| Dataset | Ukuran asli | Lindorm (zstd) | Lindorm (kamus) | HBase (Snappy) | MySQL | MongoDB (Snappy) | MongoDB (zstd) |
|---|---|---|---|---|---|---|---|
| Data pesanan (TPC-H) | 1,76 GB | 784 MB | 639 MB | 1,23 GB | 2,10 GB | 1,63 GB | 1,32 GB |
| Data IoV (NGSIM) | 1,54 GB | 995 MB | 818 MB | 1,72 GB | 2,51 GB | 1,88 GB | 1,50 GB |
| Data log (server web) | 3,51 GB | 646 MB | 387 MB | 737 MB | 3,99 GB | 1,17 GB | 893 MB |
| Perilaku pengguna (IJCAI-15) | 1,91 GB | 805 MB | 721 MB | 1,48 GB | 2,90 GB | 3,33 GB | 2,74 GB |
Memilih antara zstd dan kompresi berbasis kamus: zstd diaktifkan secara default dan mengurangi biaya penyimpanan untuk semua tipe data tanpa konfigurasi tambahan. Kompresi berbasis kamus memberikan pengurangan lebih lanjut—paling signifikan untuk data log (387 MB vs. 646 MB) dan paling kecil untuk data IoV yang banyak mengandung angka—dengan biaya langkah pelatihan kamus selama ingesti data.