Hologres V2.0 dan versi yang lebih baru mendukung Runtime Filter. Dalam skenario penggabungan beberapa tabel, fitur ini secara otomatis mengoptimalkan penyaringan selama proses penggabungan untuk meningkatkan kinerja kueri. Topik ini menjelaskan cara menggunakan Runtime Filter di Hologres.
Informasi latar belakang
Skenario
Hologres V2.0 dan versi yang lebih baru mendukung Runtime Filter. Fitur ini biasanya digunakan dalam skenario hash join yang melibatkan dua atau lebih tabel, terutama saat menggabungkan tabel besar dengan tabel kecil. Tidak diperlukan konfigurasi manual—pengoptimal dan mesin eksekusi secara otomatis mengoptimalkan penyaringan selama eksekusi kueri, sehingga mengurangi beban I/O dan meningkatkan kinerja kueri penggabungan.
Cara kerja
Untuk memahami cara kerja Runtime Filter, Anda harus terlebih dahulu memahami proses penggabungan. Berikut adalah contoh pernyataan SQL untuk menggabungkan dua tabel:
select * from test1 join test2 on test1.x = test2.x;Rencana eksekusi yang sesuai ditampilkan di bawah ini.

Seperti yang ditunjukkan dalam rencana eksekusi, ketika kedua tabel digabungkan, sebuah tabel hash dibuat dari tabel test2. Kemudian, data dari tabel test1 dicocokkan dengan tabel hash tersebut, dan hasilnya dikembalikan. Proses penggabungan ini melibatkan dua istilah kunci:
Build side: Saat dua tabel atau subkueri digabungkan menggunakan hash join, data dari salah satu tabel atau subkueri digunakan untuk membuat tabel hash. Sisi ini disebut build side dan sesuai dengan node Hash dalam rencana eksekusi.
Probe side: Sisi lain dari hash join membaca data dan mencocokkannya dengan tabel hash dari build side. Sisi ini disebut probe side.
Secara umum, jika rencana eksekusi benar, tabel yang lebih kecil berada di sisi build side dan tabel yang lebih besar berada di sisi probe side.
Runtime Filter menggunakan distribusi data dari sisi build side untuk menghasilkan filter ringan yang dikirim ke sisi probe side guna memangkas datanya. Proses ini mengurangi volume data dari sisi probe side yang terlibat dalam hash join dan ditransmisikan melalui jaringan, sehingga meningkatkan kinerja hash join.
Oleh karena itu, Runtime Filter paling efektif untuk penggabungan antara tabel besar dan tabel kecil dengan perbedaan volume data yang signifikan, memberikan peningkatan kinerja yang lebih besar dibandingkan penggabungan standar.
Batasan dan kondisi pemicu
Batasan
Hanya Hologres V2.0 dan versi yang lebih baru yang mendukung Runtime Filter.
Runtime Filter hanya dipicu jika kondisi penggabungan berisi satu bidang saja. Namun, mulai dari Hologres V2.1, Runtime Filter mendukung penggabungan pada beberapa bidang dan dipicu jika beberapa bidang penggabungan memenuhi kondisi tersebut.
Hanya Hologres V4.0 dan versi yang lebih baru yang mendukung TopN Runtime Filter, yang digunakan untuk meningkatkan kinerja dalam skenario yang melibatkan perhitungan TopN pada satu tabel.
Kondisi pemicu
Hologres menyediakan penggabungan berkinerja tinggi. Mesin secara otomatis memicu Runtime Filter jika pernyataan SQL memenuhi semua kondisi berikut:
Volume data pada sisi probe adalah 100.000 baris atau lebih.
Rasio volume data yang dipindai:
sisi build / sisi probe <= 0,1. Semakin kecil rasio, semakin besar kemungkinan Runtime Filter akan dipicu.Rasio volume data yang digabungkan:
sisi build / sisi probe <= 0,1. Semakin kecil rasio, semakin besar kemungkinan Runtime Filter akan dipicu.
Jenis-jenis Runtime Filter
Runtime Filter dapat dikategorikan berdasarkan dua dimensi berikut.
Berdasarkan apakah sisi probe side dari hash join memerlukan shuffle, filter dikategorikan sebagai Local atau Global.
Local: Didukung di Hologres V2.0 dan versi yang lebih baru. Ketika sisi probe side dari hash join tidak memerlukan shuffle, Runtime Filter Lokal dapat digunakan dalam salah satu dari tiga skenario berikut untuk data sisi build side:
Kunci penggabungan sisi build dan sisi probe memiliki distribusi data yang sama.
Data build side disiarkan ke probe side.
Data sisi build di-shuffle ke sisi probe berdasarkan distribusi data sisi probe.
Global: Didukung di Hologres V2.2 dan versi yang lebih baru. Ketika data sisi probe side memerlukan shuffle, Runtime Filter harus digabungkan terlebih dahulu sebelum dapat digunakan. Dalam kasus ini, diperlukan Runtime Filter Global.
Runtime Filter Lokal dapat mengurangi jumlah data yang dipindai dan data yang diproses oleh hash join. Runtime Filter Global menyaring data sebelum data sisi probe side di-shuffle, sehingga juga mengurangi lalu lintas jaringan. Anda tidak perlu menentukan jenis filternya—mesin akan memilih jenis yang sesuai secara otomatis.
Berdasarkan jenis filternya, filter dikategorikan sebagai Bloom Filter, In Filter, dan MinMAX Filter.
Bloom Filter: Didukung di Hologres V2.0 dan versi yang lebih baru. Filter Bloom dapat menghasilkan positif palsu, artinya beberapa data yang seharusnya disaring tidak tersaring. Namun, filter ini memiliki cakupan aplikasi yang luas dan tetap dapat memberikan efisiensi penyaringan yang tinggi serta meningkatkan kinerja kueri, bahkan dengan volume data besar di sisi build side.
In Filter: Didukung di Hologres V2.0 dan versi yang lebih baru. Filter In digunakan ketika Jumlah Nilai Unik (NDV) pada sisi build side kecil. Filter ini membuat HashSet dari data sisi build side dan mengirimkannya ke sisi probe side untuk penyaringan. Keuntungan utamanya adalah kemampuan menyaring data secara tepat dan kompatibilitasnya dengan indeks bitmap.
MinMAX Filter: Didukung di Hologres V2.0 dan versi yang lebih baru. Filter MinMAX mengambil nilai maksimum dan minimum dari data sisi build side dan mengirimkannya ke sisi probe side untuk penyaringan. Keuntungannya adalah kemampuannya langsung menyaring seluruh file atau batch data berdasarkan informasi metadata, sehingga mengurangi biaya I/O.
Anda tidak perlu menentukan jenis filternya—Hologres secara otomatis memilih dan menggunakan jenis filter yang sesuai berdasarkan kondisi penggabungan saat waktu proses.
Verifikasi Filter Runtime
Contoh-contoh berikut membantu Anda memahami Runtime Filter dengan lebih baik.
Contoh 1: Gunakan Runtime Filter Lokal untuk kondisi penggabungan dengan satu kolom
Kode sampel:
begin; create table test1(x int, y int); call set_table_property('test1', 'distribution_key', 'x'); create table test2(x int, y int); call set_table_property('test2', 'distribution_key', 'x'); end; insert into test1 select t, t from generate_series(1, 100000) t; insert into test2 select t, t from generate_series(1, 1000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;Rencana eksekusi:
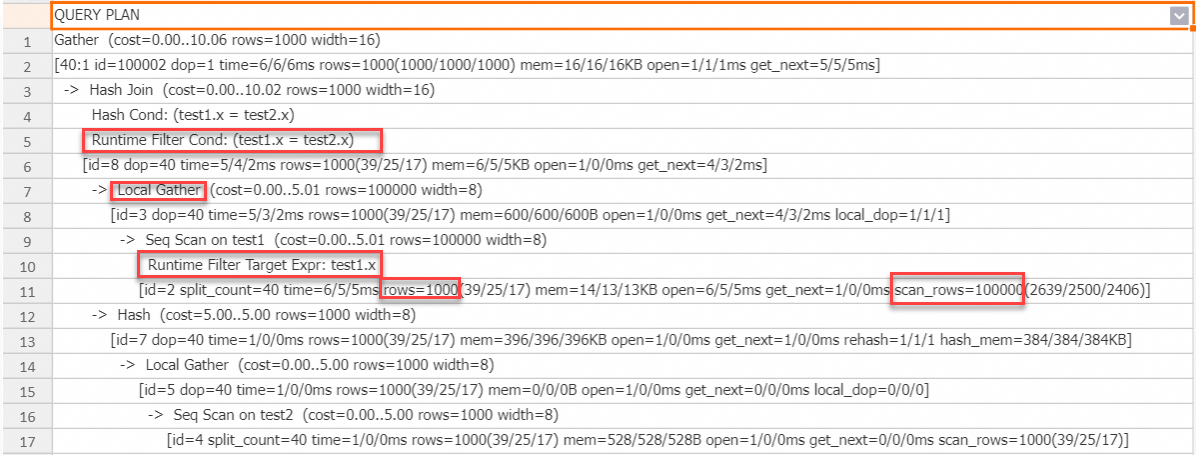
Tabel
test2memiliki 1.000 baris, dan tabeltest1memiliki 100.000 baris. Rasio volume data antara sisi build side dan sisi probe side adalah 0,01, dan rasio volume data yang digabungkan juga 0,01—keduanya kurang dari 0,1. Karena kondisi ini memenuhi syarat pemicu default, mesin secara otomatis menggunakan Runtime Filter.Tabel
test1pada sisi probe side memiliki nodeRuntime Filter Target Expr, yang menunjukkan bahwa Runtime Filter telah didorong ke sisi probe side.Pada sisi probe side, `scan_rows` merepresentasikan data yang dibaca dari penyimpanan, yaitu 100.000 baris. `rows` merepresentasikan jumlah baris dari operator pemindaian setelah disaring dengan Runtime Filter, yaitu 1.000 baris. Perbedaan antara kedua nilai ini menunjukkan efek penyaringan Runtime Filter.
Contoh 2: Gunakan Runtime Filter Lokal untuk kondisi penggabungan dengan beberapa kolom (didukung di Hologres V2.1)
Kode sampel:
drop table if exists test1, test2; begin; create table test1(x int, y int); create table test2(x int, y int); end; insert into test1 select t, t from generate_series(1, 1000000) t; insert into test2 select t, t from generate_series(1, 1000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x and test1.y = test2.y;Rencana eksekusi:
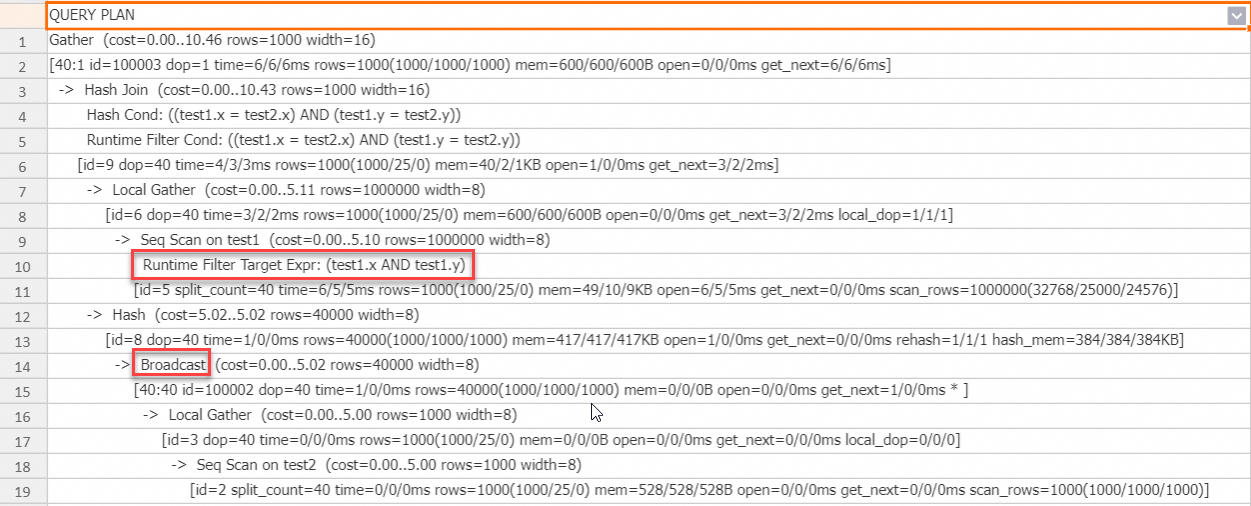
Kondisi penggabungan memiliki beberapa kolom, dan Runtime Filter juga dihasilkan untuk beberapa kolom.
Sisi build side disiarkan (broadcast), sehingga Runtime Filter Lokal dapat digunakan.
Contoh 3: Gunakan Runtime Filter Global untuk penggabungan shuffle (didukung di Hologres V2.2)
Kode sampel:
SET hg_experimental_enable_result_cache = OFF; drop table if exists test1, test2; begin; create table test1(x int, y int); create table test2(x int, y int); end; insert into test1 select t, t from generate_series(1, 100000) t; insert into test2 select t, t from generate_series(1, 1000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;Rencana eksekusi:
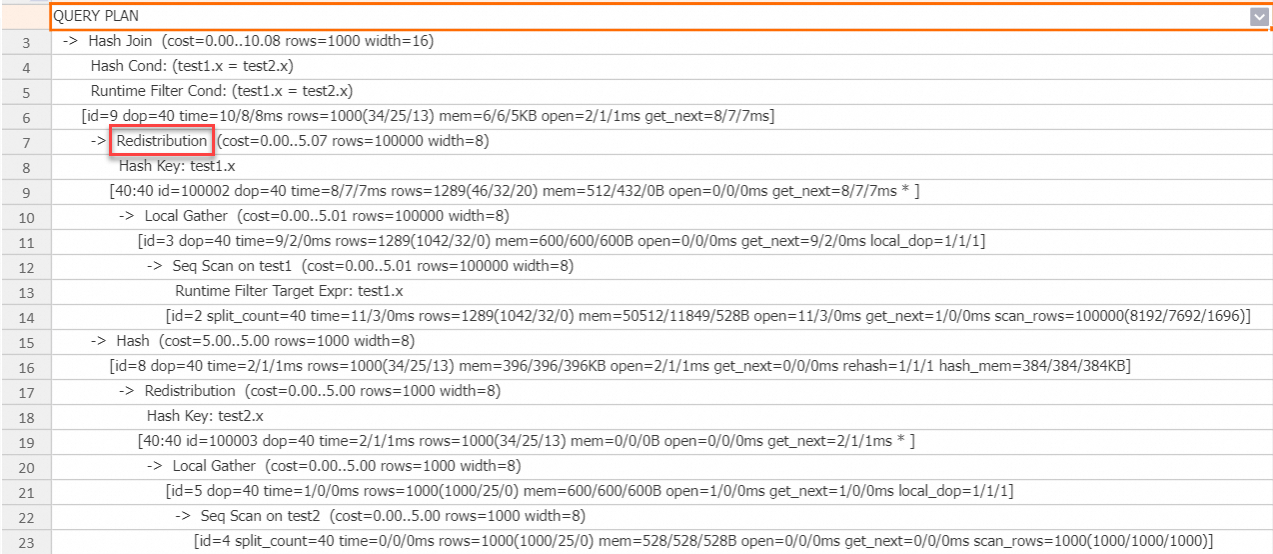
Rencana eksekusi menunjukkan bahwa data sisi probe side di-shuffle ke operator Hash Join. Mesin secara otomatis menggunakan Runtime Filter Global untuk mempercepat kueri.
Contoh 4: Gabungkan filter In dengan indeks bitmap (didukung di Hologres V2.2)
Kode sampel:
set hg_experimental_enable_result_cache=off; drop table if exists test1, test2; begin; create table test1(x text, y text); call set_table_property('test1', 'distribution_key', 'x'); call set_table_property('test1', 'bitmap_columns', 'x'); call set_table_property('test1', 'dictionary_encoding_columns', ''); create table test2(x text, y text); call set_table_property('test2', 'distribution_key', 'x'); end; insert into test1 select t::text, t::text from generate_series(1, 10000000) t; insert into test2 select t::text, t::text from generate_series(1, 50) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;Rencana eksekusi:
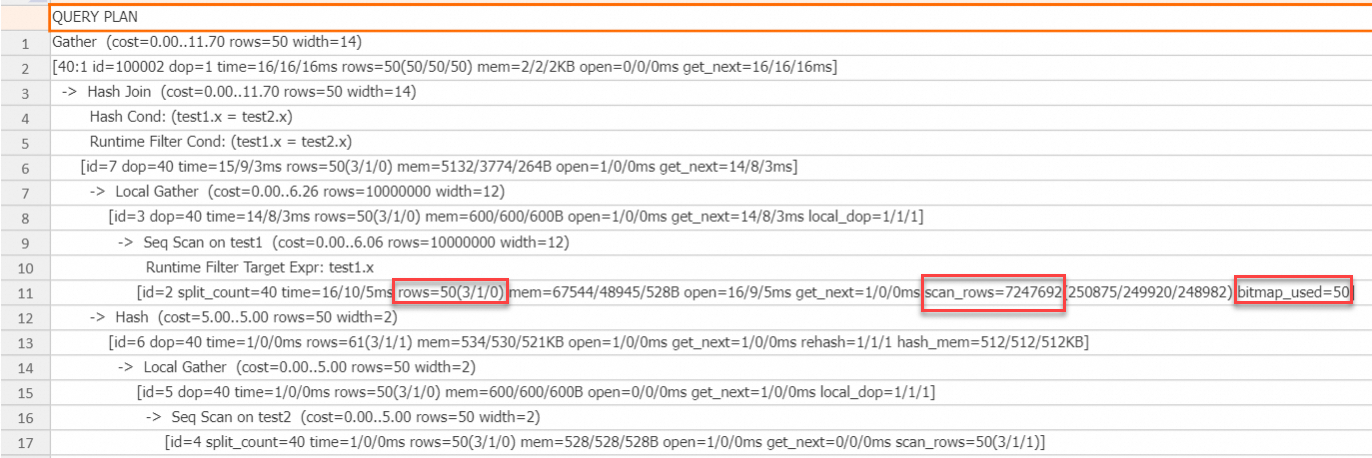
Rencana eksekusi menunjukkan bahwa bitmap digunakan pada operator pemindaian sisi probe side. Filter In memberikan penyaringan yang tepat, sehingga mengurangi keluaran hanya menjadi 50 baris. Nilai `scan_rows` lebih dari 7 juta, yang lebih sedikit daripada 10 juta baris aslinya. Pengurangan ini terjadi karena filter In dapat didorong ke mesin penyimpanan, yang mengurangi biaya I/O. Menggabungkan Runtime Filter tipe In dengan bitmap sangat efektif, terutama ketika kunci gabungan bertipe STRING.
Contoh 5: Kurangi I/O dengan filter MinMax (didukung di Hologres V2.2)
Kode sampel:
set hg_experimental_enable_result_cache=off; drop table if exists test1, test2; begin; create table test1(x int, y int); call set_table_property('test1', 'distribution_key', 'x'); create table test2(x int, y int); call set_table_property('test2', 'distribution_key', 'x'); end; insert into test1 select t::int, t::int from generate_series(1, 10000000) t; insert into test2 select t::int, t::int from generate_series(1, 100000) t; analyze test1; analyze test2; explain analyze select * from test1 join test2 on test1.x = test2.x;Rencana eksekusi:

Rencana eksekusi menunjukkan bahwa operator pemindaian pada sisi probe side hanya membaca sedikit lebih dari 320.000 baris dari mesin penyimpanan—jauh lebih sedikit daripada 10 juta baris aslinya. Pengurangan ini terjadi karena Runtime Filter didorong ke mesin penyimpanan, yang menggunakan metadata blok data untuk menyaring seluruh blok, sehingga secara signifikan mengurangi biaya I/O. Metode ini sangat efektif ketika kunci gabungan bertipe numerik dan rentang nilai sisi build side lebih kecil daripada sisi probe side.
Contoh 6: TopN Runtime Filter (didukung di Hologres V4.0)
Di Hologres, data diproses secara streaming, blok demi blok. Oleh karena itu, ketika pernyataan SQL mencakup operator topN, Hologres tidak memproses semua hasil sekaligus, melainkan menghasilkan filter dinamis untuk melakukan pra-penyaringan data.
Sebagai contoh, tinjau pernyataan SQL berikut:
select o_orderkey from orders order by o_orderdate limit 5;Rencana eksekusi untuk pernyataan SQL ini adalah sebagai berikut:
QUERY PLAN
Limit (cost=0.00..116554.70 rows=0 width=8)
-> Sort (cost=0.00..116554.70 rows=100 width=12)
Sort Key: o_orderdate
[id=6 dop=1 time=317/317/317ms rows=5(5/5/5) mem=1/1/1KB open=317/317/317ms get_next=0/0/0ms]
-> Gather (cost=0.00..116554.25 rows=100 width=12)
[20:1 id=100002 dop=1 time=317/317/317ms rows=100(100/100/100) mem=6/6/6KB open=0/0/0ms get_next=317/317/317ms * ]
-> Limit (cost=0.00..116554.25 rows=0 width=12)
-> Sort (cost=0.00..116554.25 rows=150000000 width=12)
Sort Key: o_orderdate
Runtime Filter Sort Column: o_orderdate
[id=3 dop=20 time=318/282/258ms rows=100(5/5/5) mem=96/96/96KB open=318/282/258ms get_next=1/0/0ms]
-> Local Gather (cost=0.00..9.59 rows=150000000 width=12)
[id=2 dop=20 time=316/280/256ms rows=1372205(68691/68610/68498) mem=0/0/0B open=0/0/0ms get_next=316/280/256ms local_dop=1/1/1 * ]
-> Seq Scan on orders (cost=0.00..8.24 rows=150000000 width=12)
Runtime Filter Target Expr: o_orderdate
[id=1 split_count=20 time=286/249/222ms rows=1372205(68691/68610/68498) mem=179/179/179KB open=0/0/0ms get_next=286/249/222ms physical_reads=27074(1426/1353/1294) scan_rows=144867963(7324934/7243398/7172304)]
Query id:[1001003033996040311]
QE version: 2.0
Query Queue: init_warehouse.default_queue
======================cost======================
Total cost:[343] ms
Optimizer cost:[13] ms
Build execution plan cost:[0] ms
Init execution plan cost:[6] ms
Start query cost:[6] ms
- Queue cost: [0] ms
- Wait schema cost:[0] ms
- Lock query cost:[0] ms
- Create dataset reader cost:[0] ms
- Create split reader cost:[0] ms
Get result cost:[318] ms
- Get the first block cost:[318] ms
====================resource====================
Memory: total 7 MB. Worker stats: max 3 MB, avg 3 MB, min 3 MB, max memory worker id: 189*****.
CPU time: total 5167 ms. Worker stats: max 2610 ms, avg 2583 ms, min 2557 ms, max CPU time worker id: 189*****.
DAG CPU time stats: max 5165 ms, avg 2582 ms, min 0 ms, cnt 2, max CPU time dag id: 1.
Fragment CPU time stats: max 5137 ms, avg 1721 ms, min 0 ms, cnt 3, max CPU time fragment id: 2.
Ec wait time: total 90 ms. Worker stats: max 46 ms, max(max) 2 ms, avg 45 ms, min 44 ms, max ec wait time worker id: 189*****, max(max) ec wait time worker id: 189*****.
Physical read bytes: total 799 MB. Worker stats: max 400 MB, avg 399 MB, min 399 MB, max physical read bytes worker id: 189*****.
Read bytes: total 898 MB. Worker stats: max 450 MB, avg 449 MB, min 448 MB, max read bytes worker id: 189*****.
DAG instance count: total 3. Worker stats: max 2, avg 1, min 1, max DAG instance count worker id: 189*****.
Fragment instance count: total 41. Worker stats: max 21, avg 20, min 20, max fragment instance count worker id: 189*****.Tanpa TopN Filter, node Scan membaca setiap blok data dari tabel `orders` dan meneruskannya ke node TopN. Node TopN menggunakan heap sort untuk mempertahankan 5 baris teratas yang ditemukan sejauh ini.
Sebagai ilustrasi:
Setiap blok data berisi sekitar 8.192 baris. Setelah memproses blok pertama, node TopN mengidentifikasi tanggal o_orderdate peringkat kelima dalam blok tersebut. Misalkan tanggal ini adalah 1995-01-01.
Ketika node Scan membaca blok kedua, node tersebut menggunakan 1995-01-01 sebagai kondisi filter. Node tersebut hanya mengirimkan baris-baris di mana o_orderdate ≤ 1995-01-01 ke node TopN. Ambang batas diperbarui secara dinamis. Jika tanggal o_orderdate peringkat kelima dalam blok kedua lebih kecil daripada ambang batas saat ini, node TopN memperbarui ambang batas dengan nilai baru yang lebih kecil tersebut.
Anda dapat menggunakan perintah EXPLAIN untuk melihat TopN Runtime Filter yang dihasilkan oleh pengoptimal.
-> Limit (cost=0.00..116554.25 rows=0 width=12)
-> Sort (cost=0.00..116554.25 rows=150000000 width=12)
Sort Key: o_orderdate
Runtime Filter Sort Column: o_orderdate
[id=3 dop=20 time=318/282/258ms rows=100(5/5/5) mem=96/96/96KB open=318/282/258ms get_next=1/0/0ms]Seperti yang ditunjukkan dalam contoh, node TopN menampilkan Runtime Filter Sort Column. Ini menunjukkan bahwa node TopN akan menghasilkan TopN Runtime Filter.