Topik ini menjelaskan cara mengimpor data dari tabel partisi MaxCompute ke tabel partisi Hologres.
Prasyarat
Anda telah membeli dan mengaktifkan instans Hologres. Untuk informasi selengkapnya, lihat Purchase a Hologres instance.
Anda telah mengaktifkan MaxCompute dan membuat proyek MaxCompute. Untuk informasi selengkapnya, lihat Activate MaxCompute.
Anda telah mengaktifkan DataWorks dan membuat ruang kerja DataWorks. Untuk informasi selengkapnya, lihat Create a workspace.
Informasi latar belakang
Menggunakan tabel eksternal MaxCompute di Hologres merupakan metode umum untuk mengimpor data. Dalam operasional sehari-hari, Anda sering perlu mengimpor data secara berkala. Anda dapat menggunakan DataWorks untuk menjadwalkan dan mengatur pekerjaan sehingga memungkinkan impor periodik dalam satu pekerjaan yang mencakup kedua skenario tersebut. Untuk informasi selengkapnya, lihat Contoh pekerjaan DataWorks.
Jika pekerjaan tersebut kompleks, gunakan asisten migrasi DataWorks. Impor file pekerjaan contoh ke dalam proyek Anda, lalu sesuaikan parameter atau skrip sesuai kebutuhan bisnis Anda. Untuk informasi selengkapnya, lihat Impor pekerjaan DataWorks menggunakan tool migrasi.
Catatan penting
Gunakan tabel temporary untuk memastikan atomicity. Bind tabel temporary ke tabel partisi hanya setelah impor selesai agar menghindari pembersihan manual jika impor gagal.
Saat memperbarui data di partisi anak, hapus tabel anak yang ada dan attach tabel temporary baru dalam satu transaksi untuk menjamin konsistensi transaksional.
Untuk mengimpor pekerjaan DataWorks menggunakan tool migrasi, penuhi persyaratan berikut:
Edisi DataWorks Anda harus Edisi Standar atau yang lebih baru. Untuk informasi selengkapnya, lihat Feature Details by Version.
Ruang kerja DataWorks Anda harus dilampirkan ke sumber data MaxCompute dan Hologres. Untuk informasi selengkapnya, lihat Configure a workspace.
Prosedur detail
Siapkan data MaxCompute
Login ke Konsol DataWorks. Di wilayah tujuan, pilih di panel navigasi sebelah kiri. Klik Go to Data Analytics. Lalu, di panel navigasi sebelah kiri, klik ikon
 untuk membuka halaman SQL Query.
untuk membuka halaman SQL Query.Di halaman SQL Query, masukkan pernyataan SQL berikut untuk membuat tabel partisi. Klik Run.
DROP TABLE IF EXISTS odps_sale_detail; -- Create a partitioned table named sale_detail. CREATE TABLE IF NOT EXISTS odps_sale_detail ( shop_name STRING ,customer_id STRING ,total_price DOUBLE ) PARTITIONED BY ( sale_date STRING ) ;Di halaman SQL Query, masukkan pernyataan SQL berikut untuk mengimpor data ke tabel partisi. Klik Run.
-- Add partition 20210815 to the source table ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210815') ; -- Insert data into the partition INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210815') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ; -- Add partition 20210816 to the source table ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210816') ; -- Insert data into the partition INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210816') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ; -- Add partition 20210817 to the source table ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210817') ; -- Insert data into the partition INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210817') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ; -- Add partition 20210818 to the source table ALTER TABLE odps_sale_detail ADD IF NOT EXISTS PARTITION(sale_date='20210818') ; -- Insert data into the partition INSERT OVERWRITE TABLE odps_sale_detail PARTITION(sale_date='20210818') VALUES ('s1','c1',100.1), ('s2','c2',100.2), ('s3','c3',100.3) ;
Buat tabel di Hologres
Buat tabel eksternal
-
Login ke database.
-
Di halaman pengembangan HoloWeb, klik Metadata Management.
-
Di halaman Metadata Management, klik ganda nama database yang Anda buat di pohon direktori sebelah kiri, lalu klik OK.
-
Buat tabel eksternal
Di halaman SQL Editor, klik ikon
 di pojok kiri atas untuk membuat kueri SQL baru.
di pojok kiri atas untuk membuat kueri SQL baru.Di halaman Ad-hoc Query yang baru, pilih Instance Name dan Database yang sudah ada. Di editor SQL, masukkan pernyataan berikut. Klik Run.
DROP FOREIGN TABLE IF EXISTS odps_sale_detail; -- Create a foreign table IMPORT FOREIGN SCHEMA maxcompute_project LIMIT to ( odps_sale_detail ) FROM SERVER odps_server INTO public OPTIONS(if_table_exist 'error',if_unsupported_type 'error');
-
Buat tabel partisi (tabel internal)
-
Login ke database.
-
Di halaman pengembangan HoloWeb, klik Metadata Management.
-
Di halaman Metadata Management, klik ganda nama database yang Anda buat di pohon direktori sebelah kiri, lalu klik OK.
-
Buat tabel partisi
Di halaman SQL Editor, klik ikon
di pojok kiri atas untuk membuat kueri SQL baru.Di halaman Ad-hoc Query yang baru, pilih Instance Name dan Database yang sudah ada. Di editor SQL, masukkan pernyataan berikut. Klik Run.
DROP TABLE IF EXISTS holo_sale_detail; -- Create a Hologres partitioned table (internal table) BEGIN ; CREATE TABLE IF NOT EXISTS holo_sale_detail ( shop_name TEXT ,customer_id TEXT ,total_price FLOAT8 ,sale_date TEXT ) PARTITION BY LIST(sale_date); COMMIT;
-
Impor data partisi ke tabel temporary Hologres
Di halaman Ad-hoc Query, masukkan pernyataan berikut di editor SQL. Klik Run.
Pernyataan SQL ini mengimpor partisi 20210816 dari tabel partisi odps_sale_detail di proyek hologres_test ke partisi 20210816 dari tabel partisi holo_sale_detail di Hologres.
CatatanMulai versi 2.1.17, Hologres mendukung Serverless Computing. Untuk impor offline skala besar, pekerjaan ETL besar, dan kueri tabel eksternal ber-volume tinggi, Serverless Computing menggunakan sumber daya serverless tambahan alih-alih sumber daya instans Anda. Hal ini meningkatkan stabilitas dan mengurangi error kehabisan memori (OOM). Anda hanya membayar untuk tugas yang dijalankan. Untuk informasi selengkapnya, lihat Serverless Computing. Untuk petunjuk penggunaan, lihat Serverless Computing User Guide.
-- Clean up potential temporary tables BEGIN ; DROP TABLE IF EXISTS holo_sale_detail_tmp_20210816; COMMIT ; -- Create a temporary table SET hg_experimental_enable_create_table_like_properties=on; BEGIN ; CALL HG_CREATE_TABLE_LIKE ('holo_sale_detail_tmp_20210816', 'select * from holo_sale_detail'); COMMIT; -- (Optional) Use Serverless Computing for large offline imports and ETL jobs SET hg_computing_resource = 'serverless'; -- Insert data into the temporary table INSERT INTO holo_sale_detail_tmp_20210816 SELECT * FROM public.odps_sale_detail WHERE sale_date='20210816'; -- Reset the setting so non-essential SQL statements do not use serverless resources. RESET hg_computing_resource;Attach tabel temporary ke tabel partisi Hologres
Di halaman Ad-hoc Query, masukkan pernyataan berikut di editor SQL. Klik Run.
Jika tabel anak lama ada, hapus terlebih dahulu, lalu attach tabel temporary ke tabel partisi Hologres.
Pernyataan SQL ini menghapus tabel anak holo_sale_detail_20210816 dan mengattach tabel temporary holo_sale_detail_tmp_20210816 ke partisi 20210816 dari tabel partisi holo_sale_detail.
-- Replace an existing child table BEGIN ; -- Drop the old child table DROP TABLE IF EXISTS holo_sale_detail_20210816; -- Rename the temporary table ALTER TABLE holo_sale_detail_tmp_20210816 RENAME TO holo_sale_detail_20210816; -- Attach the temporary table to the specified partitioned table ALTER TABLE holo_sale_detail ATTACH PARTITION holo_sale_detail_20210816 FOR VALUES IN ('20210816') ; COMMIT ;Jika tidak ada tabel anak lama, attach langsung tabel temporary ke tabel partisi Hologres.
Pernyataan SQL ini mengattach tabel temporary holo_sale_detail_tmp_20210816 ke partisi 20210816 dari tabel partisi holo_sale_detail.
BEGIN ; -- Rename the temporary table ALTER TABLE holo_sale_detail_tmp_20210816 RENAME TO holo_sale_detail_20210816; -- Attach the temporary table to the specified partitioned table ALTER TABLE holo_sale_detail ATTACH PARTITION holo_sale_detail_20210816 FOR VALUES IN ('20210816'); COMMIT ;
ANALYZE tabel partisi Hologres
Di halaman Ad-hoc Query, masukkan pernyataan berikut di editor SQL. Klik Run.
Pernyataan SQL ini menjalankan ANALYZE pada tabel partisi holo_sale_detail untuk memverifikasi rencana eksekusinya. Saat Anda menjalankan ANALYZE pada tabel partisi, cukup analisis tabel induknya saja.
-- Run ANALYZE on the parent table after importing large amounts of data ANALYZE holo_sale_detail;Bersihkan partisi anak yang kedaluwarsa (opsional)
Di lingkungan produksi, data memiliki siklus hidup. Bersihkan partisi yang kedaluwarsa sesuai kebutuhan.
Di halaman Ad-hoc Query, masukkan pernyataan berikut di editor SQL. Klik Run.
Pernyataan SQL ini membersihkan partisi 20210631.
DROP TABLE IF EXISTS holo_sale_detail_20210631;
Contoh pekerjaan DataWorks
Anda sering perlu menjalankan pernyataan SQL di atas secara terjadwal. Gunakan DataWorks untuk menjadwalkan dan mengatur pekerjaan. Satu pekerjaan terjadwal dapat mencakup kedua skenario tersebut. Baca konten berikut dengan cermat. Konten ini membantu Anda menyesuaikan parameter atau skrip saat Anda mengimpor pekerjaan DataWorks menggunakan tool migrasi. Alur kerja keseluruhan ditunjukkan di bawah ini.
Detail modul alur bisnis
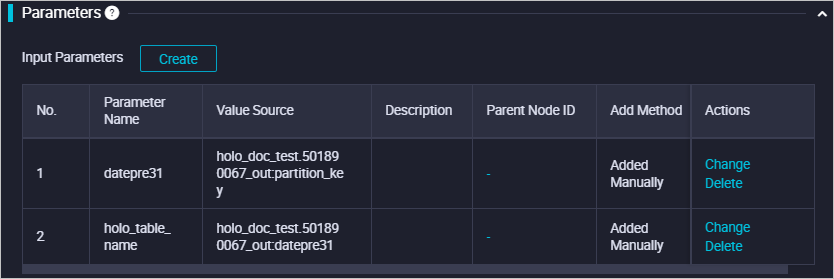
Parameter dasar
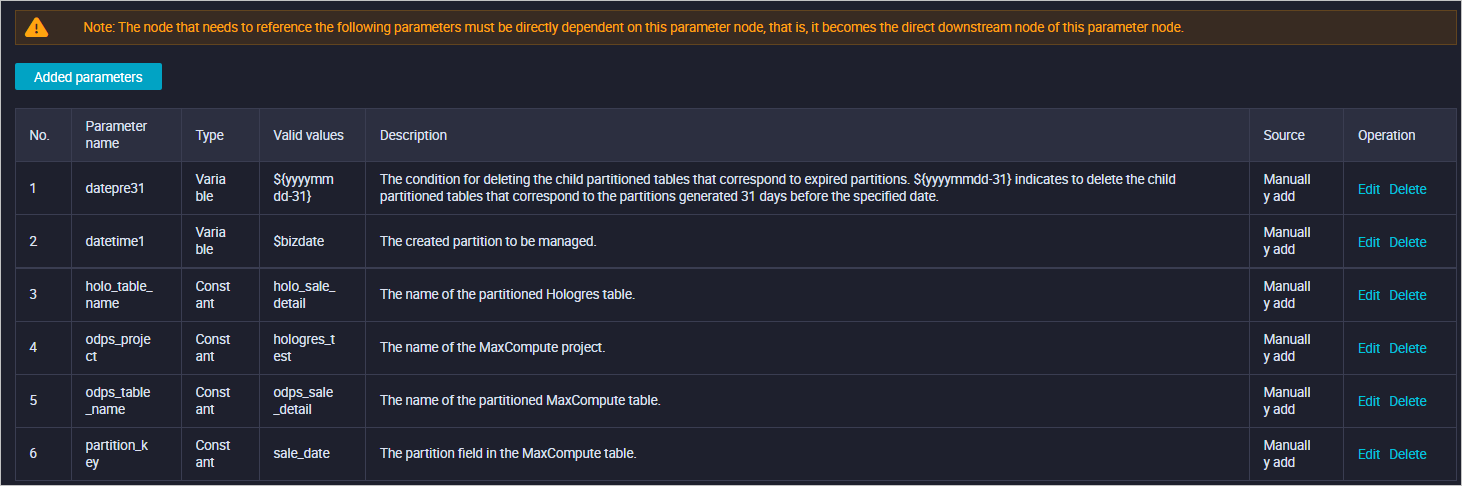
Parameter dasar mengelola semua parameter yang digunakan dalam alur kerja. Parameter utama meliputi:
ID
Nama parameter
Tipe
Nilai
Deskripsi
1
datepre31
Variable
${yyyymmdd-31}
Mengontrol pembersihan partisi kedaluwarsa. Membersihkan partisi dari 31 hari lalu.
2
datetime1
Variable
$bizdate
Mengontrol pembuatan partisi.
3
holo_table_name
Constant
holo_sale_detail
Nama tabel partisi Hologres.
4
odps_project
Constant
hologres_test
Nama proyek MaxCompute.
5
odps_table_name
Constant
odps_sale_detail
Nama tabel partisi MaxCompute.
6
partition_key
Constant
sale_date
Bidang partisi di MaxCompute.
Konfigurasi sistem ditunjukkan di bawah ini.
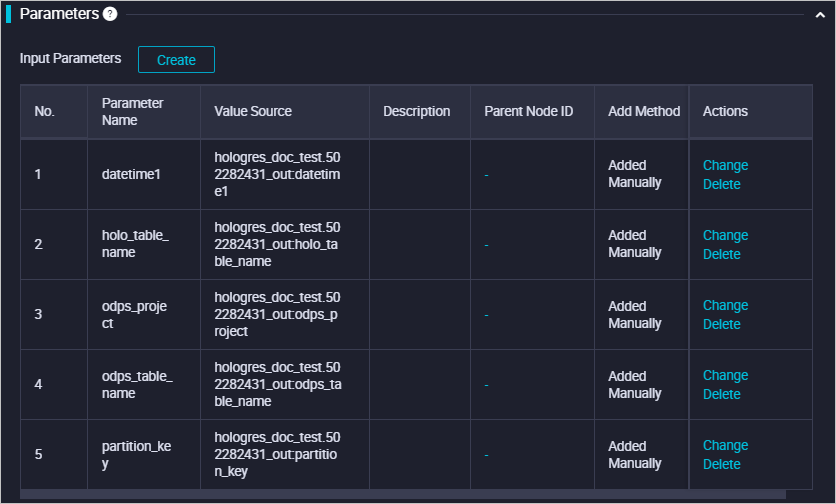
Tulis data partisi ke tabel temporary
Langkah ini merupakan modul SQL Hologres. Kodenya sebagai berikut.
CatatanMulai versi 2.1.17, Hologres mendukung Serverless Computing. Untuk impor offline skala besar, pekerjaan ETL besar, dan kueri tabel eksternal ber-volume tinggi, Serverless Computing menggunakan sumber daya serverless tambahan alih-alih sumber daya instans Anda. Hal ini meningkatkan stabilitas dan mengurangi error kehabisan memori (OOM). Anda hanya membayar untuk tugas yang dijalankan. Untuk informasi selengkapnya, lihat Serverless Computing. Untuk petunjuk penggunaan, lihat Serverless Computing User Guide.
-- Clean up potential temporary tables BEGIN ; DROP TABLE IF EXISTS ${holo_table_name}_tmp_${datetime1}; COMMIT ; -- Create a temporary table SET hg_experimental_enable_create_table_like_properties=on; BEGIN ; CALL HG_CREATE_TABLE_LIKE ('${holo_table_name}_tmp_${datetime1}', 'select * from ${holo_table_name}'); COMMIT; -- Insert data into the temporary table -- (Optional) Use Serverless Computing for large offline imports and ETL jobs SET hg_computing_resource = 'serverless'; INSERT INTO ${holo_table_name}_tmp_${datetime1} SELECT * FROM public.${odps_table_name} WHERE ${partition_key}='${datetime1}'; -- Reset the setting so non-essential SQL statements do not use serverless resources RESET hg_computing_resource;Bind parameter dasar ke modul ini di hulu untuk mengontrol variabel parameter. Konfigurasi sistem ditunjukkan di bawah ini.
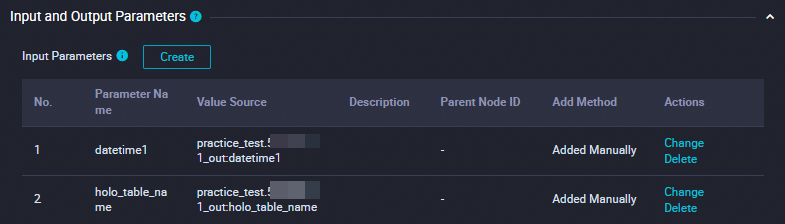
Ganti tabel anak
Langkah ini merupakan modul SQL Hologres yang mengganti tabel anak yang ada. Proses penggantian dibungkus dalam transaksi untuk memastikan konsistensi. Kodenya sebagai berikut.
-- Replace an existing child table BEGIN ; -- Drop the existing child table DROP TABLE IF EXISTS ${holo_table_name}_${datetime1}; -- Rename the temporary table ALTER TABLE ${holo_table_name}_tmp_${datetime1} RENAME TO ${holo_table_name}_${datetime1}; -- Attach the temporary table to the specified partitioned table ALTER TABLE ${holo_table_name} ATTACH PARTITION ${holo_table_name}_${datetime1} FOR VALUES IN ('${datetime1}'); COMMIT ;Bind parameter dasar ke modul ini di hulu untuk mengontrol variabel parameter. Konfigurasi sistem ditunjukkan di bawah ini.
Kumpulkan statistik untuk tabel partisi
Langkah ini merupakan modul SQL Hologres yang mengumpulkan statistik untuk tabel induk. Kodenya sebagai berikut.
-- Run ANALYZE on the parent table after importing large amounts of data ANALYZE ${holo_table_name};Bind parameter dasar ke modul ini di hulu untuk mengontrol variabel parameter. Konfigurasi sistem ditunjukkan di bawah ini.
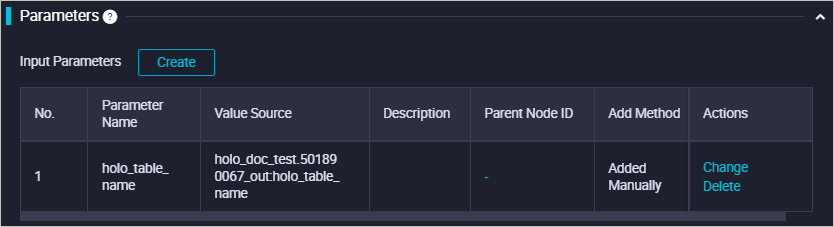
Bersihkan tabel anak yang kedaluwarsa
Di lingkungan produksi, data memiliki siklus hidup. Bersihkan partisi yang kedaluwarsa sesuai kebutuhan.
Sebagai contoh, simpan hanya partisi 31 hari terakhir di Hologres. Karena parameter datepre31=${yyyymmdd-31} telah ditetapkan sebelumnya, kode SQL untuk membersihkan tabel anak kedaluwarsa adalah sebagai berikut. Sebelum menghapus tabel anak partisi fisik, detach terlebih dahulu dari tabel induk (DETACH PARTITION). Jika tidak, tabel anak tetap terlampir ke tabel induk.
-- Clean up expired child tables: detach first, then drop BEGIN ; ALTER TABLE ${holo_table_name} DETACH PARTITION ${holo_table_name}_${datepre31}; DROP TABLE IF EXISTS ${holo_table_name}_${datepre31}; COMMIT ;Jadi jika $bizdate adalah 20200309, maka datepre31 adalah 20200207. Hal ini mencapai tujuan pembersihan partisi.
Bind juga parameter dasar ke modul ini di hulu untuk mengontrol variabel parameter. Konfigurasi sistem ditunjukkan di bawah ini.
Impor pekerjaan DataWorks menggunakan tool migrasi
Jika pekerjaan tersebut kompleks, gunakan asisten migrasi DataWorks. Impor file berikut ke dalam proyek Anda. Anda akan mendapatkan pekerjaan DataWorks seperti yang dijelaskan di atas, lalu sesuaikan parameter atau skrip sesuai kebutuhan bisnis Anda.
Unduh paket pekerjaan: Paket pekerjaan DataWorks.
Buka asisten migrasi DataWorks. Untuk informasi selengkapnya, lihat Open the migration assistant.
Di panel navigasi sebelah kiri asisten migrasi, klik .
Di halaman DataWorks Import, klik Create Import Task di pojok kanan atas.
Di kotak dialog Create Import Task, konfigurasikan parameter.

Parameter
Deskripsi
Import Name
Nama kustom. Nama impor hanya boleh berisi huruf, angka, garis bawah (_), dan titik (.).
Upload Method
Cara mengunggah file.
Local Upload: Gunakan metode ini jika ukuran file paket yang diekspor ≤ 30 MB.
OSS URL: Jika ukuran file paket yang diekspor > 30 MB, unggah ke OSS. Salin URL dari halaman detail file di konsol OSS. Tempel URL OSS ke ruang kerja DataWorks. Untuk langkah pengunggahan OSS, lihat Upload files in the console. Untuk cara mendapatkan URL unduh OSS, lihat Share files.
Remarks
Deskripsi singkat tentang tugas impor.
Klik OK. Buka halaman Import Task Settings. Konfigurasikan pemetaan.
Klik Start Import di pojok kiri bawah. Di kotak dialog Confirm, klik OK.
Setelah impor berhasil, pekerjaan periodik muncul di modul Pengembangan Data Anda.
Pernyataan DDL terkait juga muncul di alur kerja manual Anda.