Hologres mendukung global secondary index mulai dari versi 4.0 dan seterusnya. Fitur ini memungkinkan kueri titik yang efisien pada kolom non-primary key. Berbeda dengan indeks kunci primer, indeks sekunder tidak mengharuskan data bersifat unik, tetapi dapat secara signifikan meningkatkan performa kueri untuk kolom tertentu.
Prasyarat
Instans Hologres Anda harus menggunakan versi 4.0 atau lebih baru. Jika instans Anda menggunakan versi sebelumnya, lihat Upgrade an instance.
Batasan
Kolom global secondary index hanya mendukung tipe data TEXT, INTEGER, BIGINT, dan VARCHAR.
Anda tidak dapat memodifikasi indeks sekunder global.
Kolom indeks dan kolom INCLUDE tidak boleh mengandung kolom duplikat.
Tabel sumber harus memiliki primary key.
Tabel sumber tidak boleh memiliki parameter time_to_live_in_seconds yang diatur.
Global secondary index dapat memiliki maksimal 512 kolom, termasuk kolom indeks dan kolom INCLUDE.
Anda hanya dapat membuat global secondary index pada tabel internal standar. Global secondary index tidak didukung untuk tabel partisi fisik maupun logis.
Anda tidak dapat menghapus atau memodifikasi kolom pada tabel sumber jika kolom tersebut merupakan bagian dari global secondary index.
Anda tidak dapat memodifikasi Table Group atau melakukan resharding pada tabel sumber yang memiliki global secondary index.
Secara default, indeks sekunder global hanya mendukung penyimpanan Standard (hot storage).
Format penyimpanan (row store, column store, atau row-column hybrid store) dari global secondary index mengikuti format tabel sumbernya. Rinciannya sebagai berikut:
Jika tabel sumber menggunakan row store, global secondary index-nya juga menggunakan row store secara default.
Jika tabel sumber menggunakan column store, global secondary index-nya juga menggunakan column store secara default.
Jika tabel sumber menggunakan row-column hybrid store, global secondary index-nya juga menggunakan row-column hybrid store secara default.
Buat indeks sekunder global
Sintaksis
CREATE GLOBAL INDEX [ IF NOT EXISTS ] nama_indeks ON [nama_skema.]nama_tabel (nama_kolom_indeks [, ...]) [ INCLUDE (nama_kolom_include[, ...]) ]Parameter
Parameter
Diperlukan
Deskripsi
index_name
Ya
Nama indeks sekunder global.
schema_name
Tidak
Nama skema dari tabel sumber. Jika Anda tidak menentukan parameter ini, nama skema default akan digunakan.
table_name
Ya
Nama tabel sumber.
index_column_name
Ya
Kolom indeks untuk global secondary index. Kami merekomendasikan mengatur kolom ini sebagai kolom filter yang digunakan untuk kueri titik pada non-primary key.
include_column_name
Tidak
Kolom yang akan disertakan dalam indeks sekunder global.
Catatan Penggunaan
Setelah Anda mengirimkan pernyataan SQL untuk membuat indeks, sistem akan mulai membangunnya. Pernyataan
CREATE GLOBAL INDEXtidak selesai hingga indeks selesai dibangun dan terlihat.Pembuatan indeks memengaruhi performa penulisan karena melibatkan penulisan beberapa salinan data. Dampak terhadap performa penulisan meningkat seiring dengan volume data tabel sumber dan jumlah kolom dalam indeks.
Anda tidak dapat menentukan skema saat membuat global secondary index. Indeks akan dibuat dalam skema yang sama dengan tabel sumber.
Untuk menggunakan global secondary index, kueri harus sepenuhnya dilayani oleh indeks tersebut. Artinya, semua kolom dalam kueri harus berupa kolom indeks atau kolom INCLUDE.
Hapus indeks sekunder global
Sintaksis
DROP INDEX [schema_name.]index_nameParameter
Nama Parameter
Diperlukan
Deskripsi
schema_name
Tidak
Nama skema indeks sekunder global. Jika Anda tidak menentukan parameter ini, skema default akan digunakan.
index_name
Ya
Nama indeks sekunder global.
Lihat global secondary index
Lihat semua global secondary index dalam database saat ini
SELECT n.nspname AS table_namespace, t.relname AS table_name, i.relname AS index_name FROM pg_class t JOIN pg_index ix ON t.oid = ix.indrelid JOIN pg_class i ON i.oid = ix.indexrelid JOIN pg_am am ON am.oid = i.relam JOIN pg_namespace n ON n.oid = t.relnamespace WHERE t.relkind = 'r' -- Kueri hanya tabel standar AND am.amname = 'globalindex'Lihat penyimpanan yang digunakan oleh indeks sekunder global
Pada kode berikut,
global_index_namemenentukan nama global secondary index.SELECT pg_relation_size('schema_name.global_index_name');Lihat kolom yang disertakan dalam indeks sekunder global
SELECT pg_catalog.pg_get_indexdef('global_index_name'::regclass, 0, true);
Contoh
Misalkan sebuah aplikasi pesanan sering melakukan kueri data berdasarkan prioritas pesanan tertentu. Contoh berikut menggunakan tabel orders.
Nama bidang | Type | Makna |
O_ORDERKEY | BIGINT | Nomor pesanan (kunci primer). |
O_CUSTKEY | INT | ID pelanggan (kunci asing terkait dengan tabel CUSTOMER). |
O_ORDERSTATUS | CHAR(1) | Status pesanan ('F' = Selesai, 'O' = Terbuka, 'P' = Diproses). |
O_TOTALPRICE | DECIMAL(15,2) | Total jumlah pesanan. |
O_ORDERDATE | DATE | Tanggal pembuatan pesanan. |
O_ORDERPRIORITY | TEXT | Prioritas pesanan ('1-URGENT', '2-HIGH', dll.). |
O_CLERK | TEXT | ID karyawan yang memproses pesanan. |
O_SHIPPRIORITY | INT | Prioritas pengiriman (nilai lebih tinggi berarti prioritas lebih tinggi). |
O_COMMENT | TEXT | Informasi komentar pesanan. |
Pernyataan SQL berikut membuat tabel contoh orders.
CREATE TABLE ORDERS
(
O_ORDERKEY BIGINT NOT NULL PRIMARY KEY,
O_CUSTKEY INT NOT NULL,
O_ORDERSTATUS CHAR(1) NOT NULL,
O_TOTALPRICE DECIMAL(15,2) NOT NULL,
O_ORDERDATE DATE NOT NULL,
O_ORDERPRIORITY TEXT NOT NULL,
O_CLERK TEXT NOT NULL,
O_SHIPPRIORITY INT NOT NULL,
O_COMMENT TEXT NOT NULL
) WITH (
orientation='row,column',
segment_key='O_ORDERDATE',
distribution_key='O_ORDERKEY',
bitmap_columns='O_ORDERSTATUS,O_ORDERPRIORITY,O_CLERK,O_SHIPPRIORITY',
dictionary_encoding_columns='o_comment:off,o_orderpriority,o_clerk'
);
COMMENT ON TABLE ORDERS IS 'Tabel pesanan utama yang mencatat informasi dasar dan status pesanan';
COMMENT ON COLUMN ORDERS.O_ORDERKEY IS 'Nomor pesanan (primary key)';
COMMENT ON COLUMN ORDERS.O_CUSTKEY IS 'ID pelanggan (foreign key yang terkait dengan tabel CUSTOMER)';
COMMENT ON COLUMN ORDERS.O_ORDERSTATUS IS 'Status pesanan (''F'' = Selesai, ''O'' = Terbuka, ''P'' = Diproses)';
COMMENT ON COLUMN ORDERS.O_TOTALPRICE IS 'Total jumlah pesanan';
COMMENT ON COLUMN ORDERS.O_ORDERDATE IS 'Tanggal pembuatan pesanan';
COMMENT ON COLUMN ORDERS.O_ORDERPRIORITY IS 'Prioritas pesanan (''1-URGENT'', ''2-HIGH'', dll.)';
COMMENT ON COLUMN ORDERS.O_CLERK IS 'ID karyawan yang memproses pesanan';
COMMENT ON COLUMN ORDERS.O_SHIPPRIORITY IS 'Prioritas pengiriman (nilai lebih tinggi berarti prioritas lebih tinggi)';
COMMENT ON COLUMN ORDERS.O_COMMENT IS 'Informasi komentar pesanan';Pernyataan SQL berikut digunakan untuk kueri frekuensi tinggi terhadap data dengan prioritas pesanan tertentu:
SELECT O_ORDERKEY, O_CUSTKEY, O_ORDERSTATUS, O_TOTALPRICE, O_ORDERDATE, O_ORDERPRIORITY, O_CLERK, O_SHIPPRIORITY, O_COMMENT FROM ORDERS WHERE O_ORDERPRIORITY='1-URGENT'Anda dapat menggunakan
EXPLAINuntuk memeriksa rencana eksekusi pernyataan SQL tersebut:EXPLAIN SELECT O_ORDERKEY, O_CUSTKEY, O_ORDERSTATUS, O_TOTALPRICE, O_ORDERDATE, O_ORDERPRIORITY, O_CLERK, O_SHIPPRIORITY, O_COMMENT FROM ORDERS WHERE O_ORDERPRIORITY='1-URGENT'Hasil berikut dikembalikan:
QUERY PLAN Gather (cost=0.00..1.00 rows=1 width=53) -> Local Gather (cost=0.00..1.00 rows=1 width=53) -> Index Scan using Clustering_index on orders (cost=0.00..1.00 rows=1 width=53) Bitmap Filter: (o_orderpriority = '1-URGENT'::text) Query Queue: init_warehouse.default_queue Optimizer: HQO version 4.0.0Tambahkan indeks pada kolom
O_ORDERPRIORITYuntuk mencapai kueri yang lebih efisien.Rencana eksekusi yang dikembalikan menunjukkan bahwa kueri menggunakan Bitmap Index, yang hanya memberikan peningkatan performa terbatas. Untuk mencapai jumlah kueri per detik (QPS) yang lebih tinggi, Anda dapat menambahkan global secondary index pada kolom
O_ORDERPRIORITYdari tabelorders.CREATE GLOBAL INDEX idx_orders ON orders(O_ORDERPRIORITY) INCLUDE ( O_CUSTKEY, O_ORDERSTATUS, O_TOTALPRICE, O_ORDERDATE, O_CLERK, O_SHIPPRIORITY, O_COMMENT );Setelah menambahkan indeks, jalankan pernyataan
EXPLAINlagi untuk memeriksa rencana eksekusi:QUERY PLAN Local Gather (cost=0.00..1.76 rows=3035601 width=99) -> Index Scan using Clustering_index on idx_orders (cost=0.00..1.54 rows=3035601 width=99) Shard Prune: Eagerly Shards selected: 1 out of 20 Cluster Filter: (o_orderpriority = '1-URGENT'::text) Query Queue: init_warehouse.default_queue Optimizer: HQO version 4.0.0Rencana eksekusi sekarang menunjukkan bahwa objek
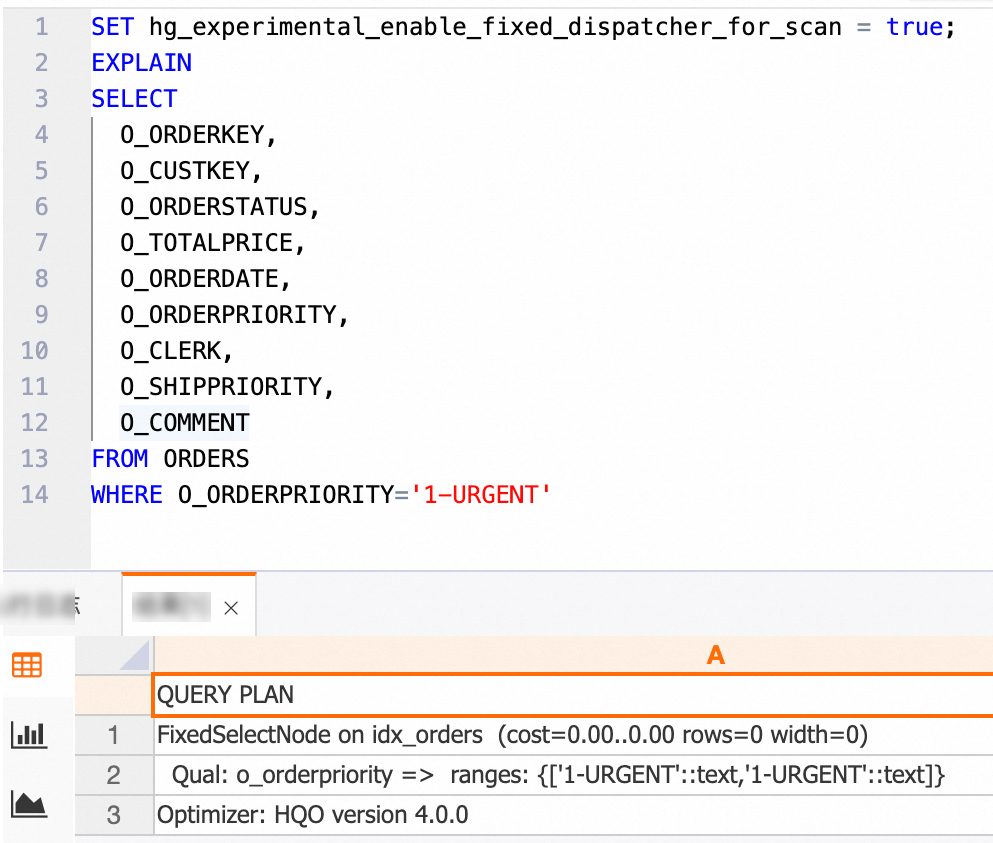
Index Scan using Clustering_index onadalah global secondary indexidx_orders. Rencana ini juga menggunakan shard clipping. Kombinasi ini secara efektif dapat meningkatkan QPS.Anda dapat menggunakan Fixed Plan untuk meningkatkan QPS lebih lanjut.
SET hg_experimental_enable_fixed_dispatcher_for_scan = true;Lihat rencana eksekusi. Anda dapat melihat bahwa kueri titik dioptimalkan menggunakan Fixed Plan.