Cloud Monitor adalah solusi pemantauan tingkat enterprise terpadu yang menyediakan pemantauan menyeluruh dalam satu tempat. Hologres telah terintegrasi dengan fitur pemantauan layanan cloud dari Cloud Monitor, memungkinkan Anda memahami secara komprehensif penggunaan sumber daya, status layanan, dan kesehatan instans Hologres. Dengan integrasi ini, Anda dapat menerima peringatan anomali secara tepat waktu dan segera meresponsnya guna memastikan aplikasi berjalan lancar. Topik ini menjelaskan cara menggunakan Cloud Monitor untuk memantau metrik dan mengatur peringatan pada instans Hologres.
Prasyarat
Anda telah membeli instans Hologres.
Rekomendasi penggunaan
Cloud Monitor kini menampilkan metrik berdasarkan tipe instans Hologres. Tipe yang didukung mencakup Hologres (Read-only Secondary Instance), Hologres (Lakehouse Acceleration), Hologres (General-purpose), dan Hologres (Compute Group). Setiap tipe instans memiliki metrik spesifik untuk membantu Anda memantau dan menangani anomali layanan secara lebih efektif. Untuk pengalaman pemantauan yang optimal, alihkan dari tampilan pemantauan umum Hologres ke tampilan yang sesuai dengan tipe instans spesifik Anda.
Metrik Cloud Monitor
Untuk informasi lebih lanjut mengenai metrik instans Hologres yang didukung oleh Cloud Monitor, lihat Metrik pemantauan di konsol Hologres.
Lihat metrik pemantauan
Anda dapat masuk ke konsol Cloud Monitor untuk melihat metrik tersebut.
-
Masuk ke Cloud Monitor console.
-
Pada panel navigasi kiri, klik Cloud Service Monitoring.
-
Di area Big Data Computing, klik tipe instans target: **Hologres (Read-only Secondary Instance)**, **Hologres (Lakehouse Acceleration)**, **Hologres (General-purpose)**, atau **Hologres (Compute Group)**. Hal ini akan membuka dasbor pemantauan Hologres.
-
Klik ikon
 di samping wilayah dan pilih wilayah tujuan.
di samping wilayah dan pilih wilayah tujuan. -
Klik Instance ID target atau klik Monitoring Chart pada kolom Actions untuk melihat status metrik instans.
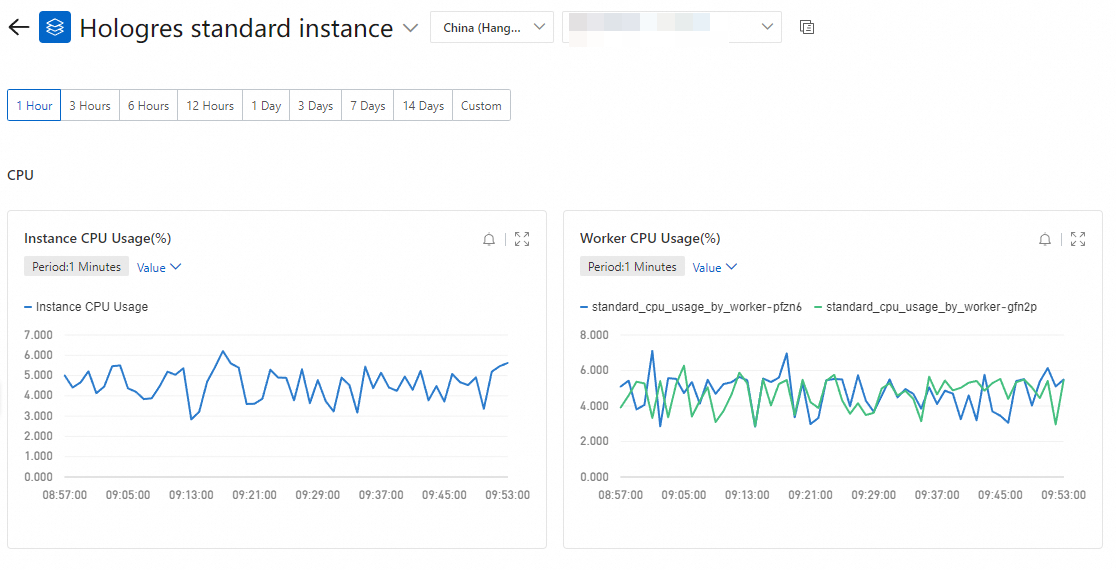 Catatan
CatatanAnda dapat menentukan rentang waktu kustom untuk melihat metrik instans. Data pemantauan disimpan maksimal selama 30 hari.
Praktik terbaik untuk pemantauan dan peringatan
Peringatan satu-klik
Hologres mendukung fitur one-click alerting di Cloud Monitor. Fitur ini menetapkan aturan peringatan default untuk semua instans dan membuat aturan peringatan untuk metrik seperti penggunaan CPU, penggunaan disk, penggunaan memori, dan jumlah koneksi. Aturan ini berlaku untuk semua instans Hologres di bawah Akun Alibaba Cloud Anda, sehingga membantu Anda mendeteksi masalah secara cepat dengan memicu peringatan anomali untuk metrik umum dan penting. Aturan peringatan default adalah sebagai berikut:
-
Jika rata-rata penggunaan koneksi (Info) lebih besar dari atau sama dengan 95% selama tiga pemeriksaan berturut-turut, peringatan dikirim ke alert contact of the Alibaba Cloud account.
-
Jika rata-rata penggunaan penyimpanan (Warn) melebihi 90% selama tiga pemeriksaan berturut-turut, peringatan akan dikirim ke alert contact of the Alibaba Cloud account.
-
Jika rata-rata penggunaan memori (Warn) lebih besar dari atau sama dengan 90% selama tiga pemeriksaan berturut-turut, peringatan dikirim ke alert contact of the Alibaba Cloud account.
-
Jika rata-rata penggunaan CPU (Info) lebih besar dari atau sama dengan 99% selama tiga pemeriksaan berturut-turut, peringatan dikirim ke alert contact of the Alibaba Cloud account.
Secara default, interval pemeriksaan peringatan adalah 5 menit. Interval ini dapat dikustomisasi.
Buat aturan peringatan
Selain peringatan satu-klik default, Anda dapat mengatur peringatan untuk metrik pemantauan tambahan sesuai kebutuhan bisnis Anda. Langkah-langkahnya sebagai berikut:
-
Masuk ke Cloud Monitor console.
-
Pada panel navigasi kiri, pilih .
-
Pada halaman Alert Rules, klik Create Alert Rule dan konfigurasikan informasi peringatan sesuai petunjuk. Untuk informasi lebih lanjut, lihat Create an alert rule.
Praktik terbaik untuk pengaturan peringatan
Pengaturan peringatan yang direkomendasikan untuk berbagai metrik pemantauan Hologres adalah sebagai berikut:
Penggunaan CPU instans (%)
Metrik ini menunjukkan apakah terdapat bottleneck sumber daya di Hologres dan apakah sumber daya Anda dimanfaatkan secara optimal. Peringatan yang direkomendasikan:
-
Aturan Peringatan:
-
Critical: "Penggunaan CPU instans lebih besar dari atau sama dengan 99% selama 60 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini secara efektif memantau penggunaan sumber daya kluster. Jika penggunaan tetap tinggi dalam waktu lama, Anda harus melakukan scale out kluster.
-
Warning: "Penggunaan CPU instans lebih besar dari atau sama dengan 99% selama 10 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini membantu Anda segera mengamati apakah penggunaan CPU mencapai batas maksimum akibat perubahan pada layanan Anda.
-
-
Jangan mengonfigurasi peringatan yang dipicu hanya karena penggunaan CPU instans mencapai 100% sekali saja. Lonjakan singkat ke penggunaan CPU 100% tidak menandakan overload sistem atau anomali. Hal ini justru merepresentasikan pemanfaatan sumber daya yang efisien.
-
Jangan menetapkan ambang batas peringatan CPU terlalu rendah. Bahkan saat tidak ada tugas yang berjalan, komponen sistem mungkin aktif dan mengonsumsi sebagian sumber daya.
Penggunaan CPU node pekerja (%)
Metrik ini menunjukkan apakah terdapat bottleneck sumber daya pada setiap node pekerja di Hologres dan apakah sumber daya dimanfaatkan secara optimal. Peringatan yang direkomendasikan:
-
Aturan peringatan
-
Critical: "Penggunaan CPU node pekerja lebih besar dari atau sama dengan 99% selama 60 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini secara efektif memantau penggunaan sumber daya setiap node pekerja. Jika penggunaan tetap tinggi dalam waktu lama, Anda harus melakukan scale out kluster.
-
Warning: "Penggunaan CPU node pekerja lebih besar dari atau sama dengan 99% selama 10 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini membantu Anda segera mengamati apakah penggunaan CPU mencapai batas maksimum akibat perubahan pada layanan Anda.
-
-
Jangan mengonfigurasi peringatan yang dipicu hanya karena penggunaan CPU node pekerja mencapai 100% sekali saja. Lonjakan singkat ke penggunaan CPU 100% tidak menandakan overload sistem atau anomali. Hal ini justru merepresentasikan pemanfaatan sumber daya yang efisien.
-
Jangan menetapkan ambang batas peringatan CPU terlalu rendah. Bahkan saat tidak ada tugas yang berjalan, komponen sistem mungkin aktif dan mengonsumsi sebagian sumber daya.
Penggunaan memori instans (%)
Metrik ini mencerminkan penggunaan memori instans. Peringatan yang direkomendasikan:
-
Aturan peringatan
-
Critical: "Penggunaan memori instans lebih besar dari atau sama dengan 99% selama 60 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini secara efektif memantau penggunaan memori kluster. Jika penggunaan tetap tinggi dalam waktu lama, Anda harus melakukan scale out kluster.
-
Warning: "Penggunaan memori instans lebih besar dari atau sama dengan 99% selama 10 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini membantu Anda segera mengamati apakah penggunaan memori mencapai batas maksimum akibat perubahan pada layanan Anda.
-
-
Jangan menetapkan ambang batas peringatan memori terlalu rendah. Memori digunakan tidak hanya untuk menjalankan kueri, tetapi juga untuk metadata dan cache. Sejumlah memori tertentu dikonsumsi bahkan saat instans dalam keadaan idle.
Penggunaan memori node pekerja (%)
Metrik ini mencerminkan penggunaan memori node pekerja. Peringatan yang direkomendasikan:
-
Aturan peringatan
-
Critical: "Penggunaan memori node pekerja lebih besar dari atau sama dengan 99% selama 60 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini secara efektif memantau penggunaan memori kluster. Jika penggunaan tetap tinggi dalam waktu lama, Anda harus melakukan scale out kluster.
-
Warning: "Penggunaan memori node pekerja lebih besar dari atau sama dengan 99% selama 10 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini membantu Anda segera mengamati apakah penggunaan memori mencapai batas maksimum akibat perubahan pada layanan Anda.
-
-
Jangan menetapkan ambang batas peringatan memori terlalu rendah. Memori digunakan tidak hanya untuk menjalankan kueri, tetapi juga untuk metadata dan cache. Sejumlah memori tertentu dikonsumsi bahkan saat instans dalam keadaan idle.
Penggunaan koneksi FE dengan penggunaan koneksi tertinggi (%)
Metrik ini mencerminkan penggunaan koneksi maksimum setiap node FE. Aturan peringatan yang direkomendasikan adalah sebagai berikut:
Warning: "Penggunaan koneksi FE dengan penggunaan koneksi tertinggi lebih besar dari atau sama dengan 95% selama 5 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini membantu Anda secara efektif memantau penggunaan koneksi kluster dan segera membersihkan koneksi idle.
Penggunaan WAL sender FE dengan penggunaan WAL sender tertinggi (%)
Metrik ini mencerminkan penggunaan WAL sender maksimum setiap node FE. Aturan peringatan yang direkomendasikan adalah sebagai berikut:
Warning: "Penggunaan WAL sender FE dengan penggunaan WAL sender tertinggi lebih besar dari atau sama dengan 95% selama 5 epoch berturut-turut (1 epoch = 1 menit)." Aturan ini membantu Anda secara efektif memantau penggunaan WAL sender kluster.
Durasi terlama kueri yang sedang berjalan di instans (milidetik)
Metrik ini membantu Anda secara efektif memantau apakah terdapat kueri berjalan lama di instans. Aturan peringatan yang direkomendasikan adalah sebagai berikut:
Warning: "Durasi terlama kueri yang sedang berjalan di instans lebih besar dari atau sama dengan 3.600.000 milidetik selama 10 epoch berturut-turut (1 epoch = 1 menit)."
Durasi terlama kueri yang sedang berjalan di Serverless Computing (milidetik)
Metrik ini membantu Anda secara efektif memantau eksekusi tugas di kluster serverless. Jika suatu tugas berjalan terlalu lama, Anda dapat segera membatalkannya. Aturan peringatan yang direkomendasikan adalah sebagai berikut:
Warning: "Durasi terlama kueri yang sedang berjalan di Serverless Computing lebih besar dari atau sama dengan 3.600.000 milidetik selama 10 epoch berturut-turut (1 epoch = 1 menit)."
QPS kueri gagal (jumlah)
Metrik ini mencerminkan jumlah kueri yang gagal di instans. Anda dapat mengatur peringatan untuk kueri gagal agar tetap mengetahui status eksekusi kueri. Aturan peringatan yang direkomendasikan adalah sebagai berikut:
Warning: "QPS kueri gagal lebih besar dari atau sama dengan 10 jumlah selama 10 epoch berturut-turut (1 epoch = 1 menit)." Jika terdapat banyak kueri gagal di instans Anda, periksa log kueri lambat untuk detail kegagalan dan lakukan tindakan yang sesuai.
Latensi replay FE (milidetik)
Metrik ini mencerminkan waktu replay setiap FE. Waktu replay yang lama menunjukkan replay lambat, yang mungkin disebabkan oleh FE yang hang. Hal ini dapat menyebabkan kueri menjadi stuck dan memerlukan perhatian segera. Peringatan yang direkomendasikan:
-
Aturan peringatan
Warning: "Latensi replay FE lebih besar dari atau sama dengan 300.000 milidetik selama 10 epoch berturut-turut (1 epoch = 1 menit)." Jika peringatan dipicu, Anda dapat membuka Active Queries di HoloWeb untuk memeriksa kueri berjalan lama dan mencoba membatalkannya.
-
Jangan menetapkan ambang batas latensi replay FE terlalu rendah. Replay FE terjadi setiap kali metadata dimodifikasi di instans. Biasanya, waktu replay FE dalam rentang detik merupakan hal yang normal.
Latensi sinkronisasi primary-secondary (milidetik)
Metrik ini hanya ditampilkan untuk instans secondary read-only dan mencerminkan latensi sinkronisasi primary-secondary. Aturan peringatan yang direkomendasikan adalah sebagai berikut:
Warning: "Latensi sinkronisasi primary-secondary lebih besar dari atau sama dengan 600.000 milidetik selama 10 epoch berturut-turut (1 epoch = 1 menit)."
Jumlah tabel tanpa statistik di setiap DB (jumlah)
Metrik ini mencerminkan kualitas Auto Analyze. Jika tabel tidak memiliki statistik dalam waktu lama, Anda dapat menjalankan perintah ANALYZE secara manual pada tabel tersebut. Untuk informasi lebih lanjut, lihat ANALYZE and AUTO ANALYZE. Peringatan yang direkomendasikan:
-
Aturan peringatan
Warning: "Jumlah tabel tanpa statistik di setiap DB lebih besar dari atau sama dengan 10 jumlah selama 60 epoch berturut-turut (1 epoch = 1 menit)."
-
Jangan menetapkan ambang batas terlalu rendah. Banyaknya tabel di instans juga dapat memperlambat eksekusi Auto Analyze.
Atasi masalah pemantauan umum
Jika metrik pemantauan berfluktuasi secara tidak terduga atau peringatan dipicu, Anda dapat merujuk ke FAQ tentang metrik pemantauan untuk mengatasi dan menyelesaikan masalah tersebut.
Akses metrik pemantauan menggunakan API
Selain melalui konsol Cloud Monitor, Cloud Monitor menyediakan cara lain untuk mengakses metrik pemantauan, seperti dasbor kustom dan API. Metode-metode ini memberikan akses yang lebih fleksibel terhadap data pemantauan.
-
Untuk mengakses Cloud Monitor menggunakan API, lihat Cloud service monitoring.
-
Untuk menggunakan dasbor kustom, lihat Manage custom dashboards.
-
Untuk mengakses pemantauan Hologres menggunakan ARMS, lihat Integration guide.
Berikan izin kepada pengguna RAM untuk melihat data Cloud Monitor
Secara default, pengguna Resource Access Management (RAM) tidak dapat melihat informasi metrik di Cloud Monitor. Anda harus memberikan izin yang diperlukan kepada pengguna RAM tersebut.
Gunakan Akun Alibaba Cloud Anda untuk masuk ke Resource Access Management (RAM) console dan berikan izin berikut kepada pengguna RAM. Untuk informasi lebih lanjut tentang cara memberikan izin, lihat Manage RAM user permissions.
Pilih izin sesuai kebutuhan.
|
Nama Izin |
Deskripsi fitur izin |
AliyunCloudMonitorFullAccess |
Izin untuk mengelola Cloud Monitor. |
AliyunCloudMonitorReadOnlyAccess |
Izin read-only untuk Cloud Monitor. |
AliyunCloudMonitorMetricDataReadOnlyAccess |
Izin untuk mengakses data metrik deret waktu di Cloud Monitor. |