Hologres adalah mesin gudang data real-time terdistribusi berkinerja tinggi dengan arsitektur pemisahan komputasi dan penyimpanan. Data disimpan dalam sistem penyimpanan dasar pada partisi data, yang juga dikenal sebagai shard. Topik ini menjelaskan konsep table group dan shard count di Hologres.
Table group dan shard
Di Hologres, data disimpan pada Apsara Distributed File System. Shard adalah partisi data. Table group merupakan konsep penyimpanan logis untuk mengelola shard-shard tersebut. Data suatu tabel disimpan pada sekelompok shard tetap yang ditetapkan saat tabel dibuat dan dikelola oleh table group. Saat data ditulis, data tersebut didistribusikan ke shard tertentu berdasarkan kunci distribusi.
Table group adalah konsep penyimpanan logis khas Hologres dan tidak ada di PostgreSQL. Table group berbeda dari tablespace di PostgreSQL. Tablespace mengidentifikasi lokasi penyimpanan objek basis data, mirip seperti direktori, sedangkan table group merepresentasikan sekelompok shard logis di lapisan bawah.
Gambar berikut menunjukkan tata letak sebuah table group.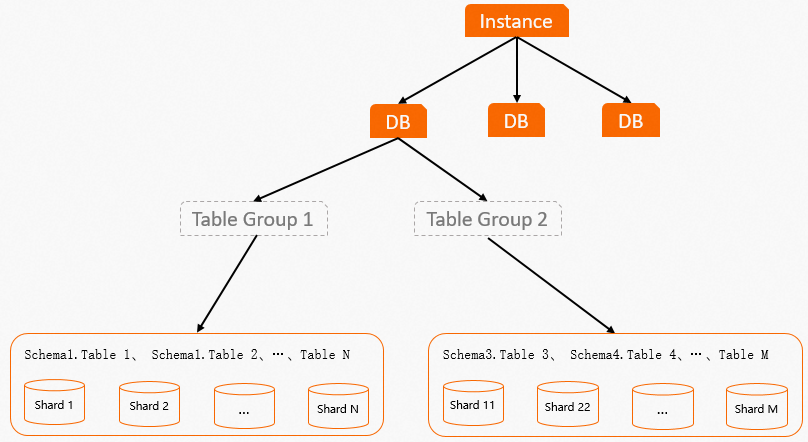 Gambar tersebut menggambarkan hubungan-hubungan berikut:
Gambar tersebut menggambarkan hubungan-hubungan berikut:
Perbedaan antara table group dan schema
Schema adalah konsep standar dalam basis data, sedangkan table group adalah konsep penyimpanan logis khas Hologres. Tabel-tabel dari schema berbeda dapat termasuk dalam table group yang sama, artinya mereka menggunakan kelompok shard dasar yang sama untuk penyimpanan data.
Hubungan antara table group dan database (DB)
Sebuah database (DB) dapat berisi satu atau beberapa table group, tetapi hanya satu yang dapat menjadi table group default. Saat Anda membuat DB, sistem juga membuat table group default. Anda dapat menambahkan lebih banyak table group atau mengubah table group default sesuai kebutuhan.
Perbedaan antara kelompok tabel
Sebuah DB dapat memiliki beberapa table group. Namun, shard-shard di table group yang berbeda tidak saling tumpang tindih. Setiap shard memiliki ID unik di tingkat instans.
Shard count
Jumlah shard dalam sebuah table group disebut shard count. Anda harus menentukan shard count saat membuat table group. Setelah table group dibuat, Anda tidak dapat mengubah shard count-nya. Untuk menyesuaikan shard count, Anda harus membuat table group baru dengan jumlah shard yang diinginkan.
Hubungan antara shard dan tabel
Shard menyimpan dan melayani kueri terhadap data tabel. Sistem mendistribusikan data ke berbagai shard berdasarkan kunci distribusi. Jika Anda tidak menetapkan kunci distribusi, data akan didistribusikan secara acak ke seluruh shard.
Sebuah table group dapat berisi beberapa tabel, yang kemudian didistribusikan pada kelompok shard yang sama. Namun, satu tabel hanya dapat termasuk dalam satu table group. Jika sebuah table group tidak berisi tabel apa pun, sistem akan menghapusnya secara otomatis.
Untuk memindahkan tabel ke table group yang berbeda, Anda harus membuat ulang tabel tersebut di table group baru atau menggunakan fungsi migrasi untuk memindahkan datanya.
Hubungan antara shard dan worker node
Di Hologres, storage engine (SE) bertanggung jawab mengelola dan memproses data. Untuk operasi Data Manipulation Language (DML), SE menyediakan antarmuka untuk akses CRUD (create, read, update, and delete) secara tunggal maupun batch. Query engine (QE) menggunakan antarmuka ini untuk mengakses data pada shard, sehingga memungkinkan penulisan dan pembacaan data berkinerja tinggi.
Gambar berikut menunjukkan tata letak worker node, SE, dan shard.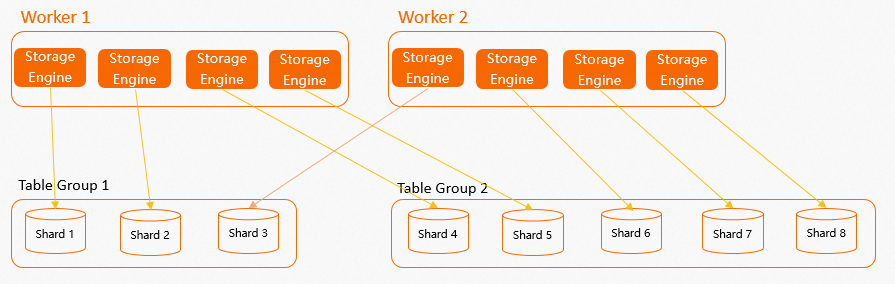 Gambar tersebut menunjukkan bahwa table group dan shard terkait dengan worker node selain distribusi data:
Gambar tersebut menunjukkan bahwa table group dan shard terkait dengan worker node selain distribusi data:
Setelah Anda membuat table group dan menetapkan shard count-nya, setiap worker node membuat beberapa SE internal. Setiap SE bertanggung jawab atas operasi baca dan tulis untuk satu shard. Jika Anda tidak secara eksplisit menetapkan table group dan shard count, Hologres akan membuat table group default dan menetapkan shard count default saat database dibuat. Untuk informasi lebih lanjut, lihat Instance management.
Sistem berusaha mendistribusikan SE secara merata di antara semua worker untuk memastikan alokasi sumber daya komputasi yang seimbang.
Sistem memastikan bahwa shard dalam satu table group didistribusikan ke beberapa worker. Hal ini mencegah skenario di mana seluruh shard dari satu table group diberikan ke satu worker saja, sehingga worker lain menganggur. Namun, jika jumlah shard dalam table group kecil sedangkan instans memiliki banyak worker, beberapa worker mungkin tidak mendapat alokasi shard dan tetap menganggur. Oleh karena itu, saat menentukan shard count, pertimbangkan kebutuhan bisnis Anda agar tercapai keseimbangan antara jumlah worker dan total jumlah shard dalam instans.
Gambar sebelumnya mengilustrasikan potensi masalah. Jika shard count suatu table group bukan kelipatan jumlah worker (misalnya,
Table Group 1memiliki tiga shard tetapi hanya dua worker), maka satu worker pasti mendapat lebih banyak SE daripada yang lain. Hal ini dapat menyebabkan ketimpangan sumber daya dan latensi ekor panjang (long-tail latency) selama komputasi. Oleh karena itu, Anda sebaiknya menetapkan shard count sebagai kelipatan jumlah worker. Seperti yang ditunjukkan pada gambar berikut, shard countTable Group 1danTable Group 2merupakan kelipatan jumlah worker, sehingga sumber daya komputasi dapat didistribusikan secara merata.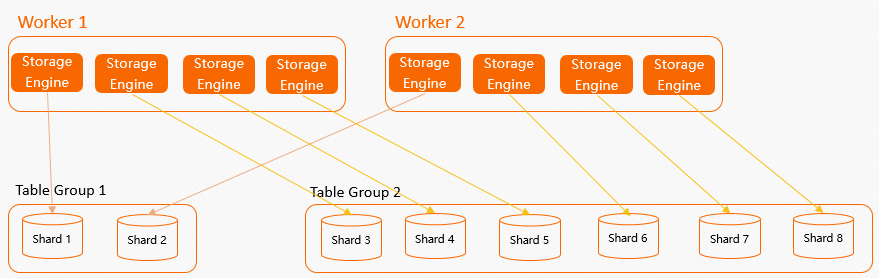
Dalam praktiknya, sebuah worker bisa mengalami failover karena alasan seperti error out-of-memory (OOM). Saat hal ini terjadi, shard yang berada di worker yang gagal tersebut secara otomatis dialihkan ke worker lain. Sistem memastikan shard tersebut didistribusikan semerata mungkin di antara worker yang tersisa. Sebagai contoh, pertimbangkan instans dengan 4 worker dan 8 shard dari 2 table group, di mana setiap worker memiliki 2 SE dan shard tersebar merata. Jika
Worker 4mengalami failover, dan diasumsikan bertanggung jawab atasShard 7danShard 8, makaShard 7danShard 8akan segera dialihkan ke tiga worker lainnya. Karena hanya dua shard yang perlu dialihkan, sistem secara acak memilih dua dari worker yang tersisa untuk penugasan tersebut guna menjaga keseimbangan jumlah SE di setiap worker.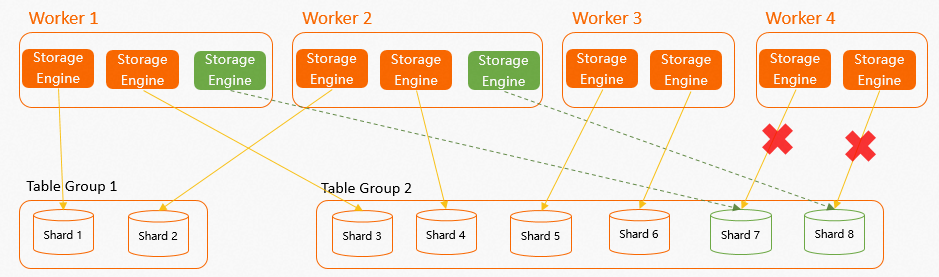
Ringkasan
Jumlah worker sangat berkaitan erat dengan shard count. Konfigurasi table group dan shard count yang tepat memungkinkan tingkat paralelisme yang lebih tinggi untuk penulisan data, kueri, dan analisis. Konfigurasi ini memaksimalkan pemanfaatan sumber daya komputasi serta meningkatkan efisiensi penyimpanan dan komputasi data. Sebaliknya, jika table group dan shard count tidak dikonfigurasi dengan baik, performa mungkin tidak sesuai harapan dan sulit dioptimalkan.
Dalam rentang tertentu, table group dengan lebih banyak shard dapat mencapai tingkat paralelisme yang lebih tinggi untuk penulisan data, kueri, dan analisis. Namun, peningkatan jumlah shard tidak selalu menguntungkan. Lebih banyak shard memerlukan komunikasi antarnode, sumber daya komputasi, dan memori yang lebih besar. Jika sumber daya tidak mencukupi atau kueri berskala kecil, jumlah shard yang tinggi justru dapat merugikan.
Shard count minimum adalah 1. Jika volume data sangat kecil, misalnya hanya ratusan atau ribuan baris, Anda sebaiknya menetapkan shard count ke 1. Shard count maksimum yang direkomendasikan untuk sebuah table group adalah jumlah total core komputasi dalam instans. Konfigurasi ini memastikan setiap shard memiliki setidaknya satu core untuk komputasi. Jika shard count melebihi jumlah core komputasi, beberapa shard tidak akan mendapat alokasi sumber daya CPU secara konsisten selama kueri. Hal ini dapat menyebabkan latensi ekor panjang dan overhead pergantian konteks (context-switching).
Menambah jumlah table group tidak selalu menguntungkan. Setiap shard, baik sedang digunakan maupun tidak, mengonsumsi memori untuk menyimpan metadata, informasi schema, dan data lainnya. Shard mengonsumsi lebih banyak memori lagi saat data ditulis ke tabel yang dikandungnya. Oleh karena itu, semakin banyak table group berarti semakin banyak total shard dalam instans, yang meningkatkan konsumsi memori. Selain itu, jika tabel-tabel memiliki hubungan khusus—misalnya memerlukan local join—mereka harus berada dalam table group yang sama.
Pada disk, penggunaan lebih banyak shard untuk tabel yang sama menghasilkan data yang lebih tersebar. Hal ini dapat menyebabkan jumlah file kecil yang lebih banyak. Jika Anda memiliki banyak tabel dan banyak shard, jumlah total file bisa menjadi sangat besar. Hal ini meningkatkan overhead selama kueri dan failover, yang berakibat pada I/O kueri yang lebih tinggi dan waktu pemulihan yang lebih lama.