Hologres menggunakan arsitektur Storage Disaggregation. Halaman ini menjelaskan desain arsitektur dan peran setiap komponen.
Model arsitektur penyimpanan-komputasi
Tiga model arsitektur penyimpanan-komputasi umum digunakan dalam sistem terdistribusi.
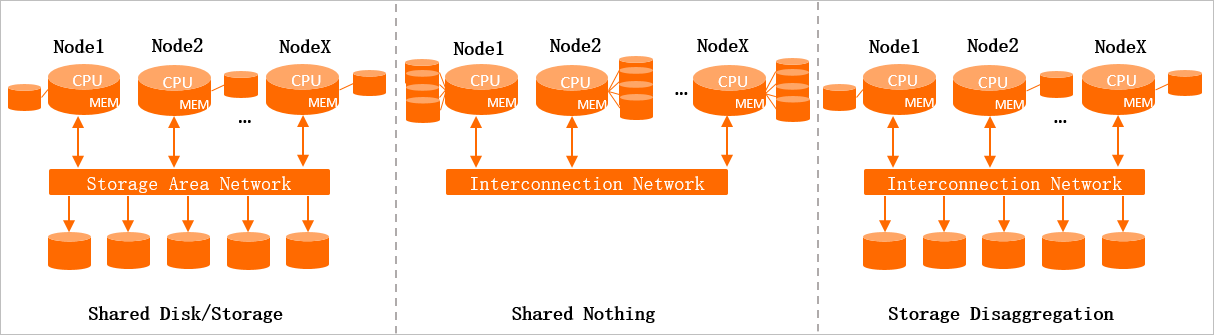
Shared Disk / Shared Storage
Kluster penyimpanan terdistribusi dibagi oleh semua node pekerja. Setiap node pekerja mengakses data seolah-olah data tersebut lokal. Kluster penyimpanan mudah diskalakan, tetapi node pekerja memerlukan koordinasi terdistribusi untuk menjaga konsistensi, yang membatasi jumlah maksimum node pekerja.
Shared Nothing
Setiap node pekerja memasang penyimpanan lokalnya sendiri dan memproses data dari satu shard. Node pekerja saling berkomunikasi, dan sebuah node ringkasan khusus melakukan agregasi hasil. Arsitektur ini dapat diskalakan secara horizontal, tetapi memiliki kekurangan: setelah failover, node yang pulih harus memuat ulang data sebelum melayani permintaan, dan setiap skala keluar memicu penyeimbangan ulang data di seluruh node—proses yang memakan waktu.
Storage Disaggregation
Kluster penyimpanan terdistribusi dibagi bersama, tetapi setiap node komputasi memproses data dari shard khusus—mirip dengan Shared Nothing—dan mempertahankan cache lokal. Arsitektur ini menawarkan:
Konsistensi data tanpa kerumitan: Hanya satu node pekerja yang menulis ke satu shard pada satu waktu, sehingga menghilangkan kebutuhan akan koordinasi kompleks.
Penskalaan fleksibel: Sumber daya komputasi dan penyimpanan dapat diskalakan secara independen. Saat puncak trafik, Anda hanya perlu memperluas kapasitas lapisan komputasi tanpa memicu penyeimbangan ulang data.
Pemulihan failover cepat: Setelah terjadi kegagalan, node baru menarik data dari penyimpanan terdistribusi secara asinkron dan segera melanjutkan layanan.
Hologres menggunakan arsitektur Storage Disaggregation, yang menggabungkan kesederhanaan manajemen penyimpanan bersama dengan performa dan skalabilitas komputasi berbasis shard. Penyimpanan dasarnya adalah Pangu, sistem file terdistribusi milik Alibaba, yang berperan serupa dengan Hadoop Distributed File System (HDFS).
Komponen dalam arsitektur Hologres
Gambar berikut menunjukkan arsitektur Hologres.
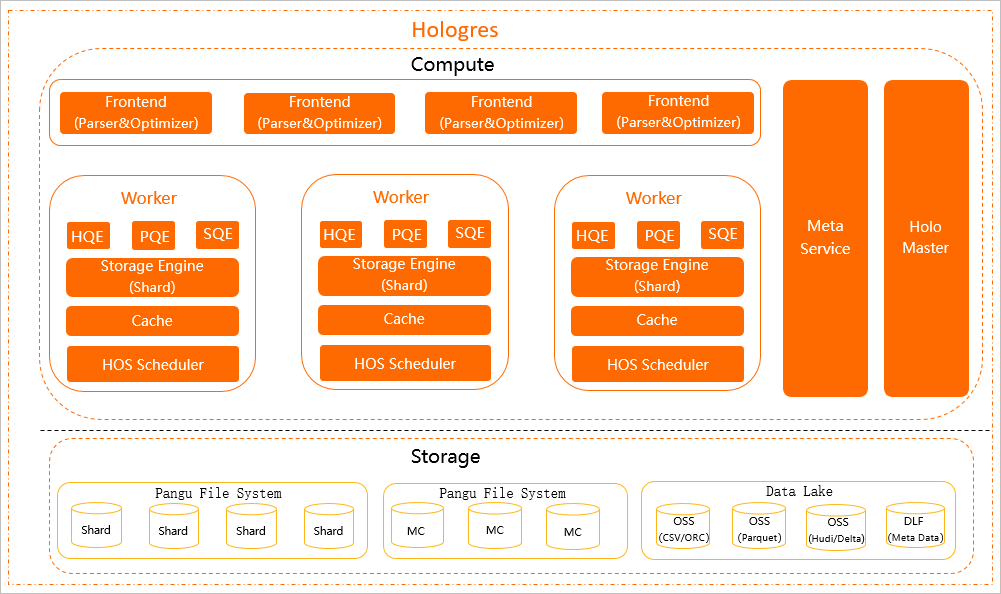
Lapisan komputasi
Frontend (FE)
FE melakukan autentikasi, mengurai, dan mengoptimalkan pernyataan SQL. Sebuah instans Hologres menjalankan beberapa FE. Hologres kompatibel dengan PostgreSQL 11, sehingga Anda dapat menggunakan sintaks standar PostgreSQL dan terhubung dengan alat pengembangan serta alat Business Intelligence (BI) yang kompatibel dengan PostgreSQL tanpa konfigurasi tambahan.
HoloWorker
HoloWorker menjadwalkan dan mengeksekusi kueri pengguna. Setiap HoloWorker berisi Query Engine (QE), Storage Engine (SE), Cache, dan HOS Scheduler.
*Query Engine (QE)*
HoloWorker mendukung tiga mesin kueri, masing-masing melayani workload yang berbeda:
| Mesin | Tujuan | Karakteristik utama |
|---|---|---|
| Hologres Query Engine (HQE) | Mesin utama untuk kueri analitis | Arsitektur MPP yang dapat diskalakan dengan operator vektorisasi; memaksimalkan pemanfaatan CPU untuk performa kueri tinggi |
| PostgreSQL Query Engine (PQE) | Lapisan kompatibilitas PostgreSQL | Mendukung PostGIS dan UDF yang ditulis dalam PL/Java, PL/SQL, atau PL/Python; menangani operasi yang belum didukung oleh HQE |
| Seahawks Query Engine (SQE) | Integrasi MaxCompute | Terhubung ke MaxCompute tanpa migrasi data; mendukung tabel hash, tabel terkluster berbasis rentang, dan analisis interaktif data batch skala PB |
Tujuan jangka panjangnya adalah mengintegrasikan seluruh fungsionalitas PQE ke dalam HQE.
*Storage Engine (SE)*
SE mengelola data dan menangani semua operasi membuat, membaca, memperbarui, dan menghapus (CRUD).
*Cache*
Komponen Cache menyimpan hasil kueri untuk meningkatkan performa kueri.
*HOS Scheduler*
HOS Scheduler menyediakan kemampuan penjadwalan ringan.
Meta Service
Meta Service mengelola metadata—termasuk struktur tabel dan distribusi data di seluruh SE—dan menyediakannya kepada FE.
Holo Master
Hologres berjalan secara native di Kubernetes. Jika sebuah node pekerja gagal, Kubernetes menyediakan pengganti dalam waktu singkat, sehingga menjaga ketersediaan tingkat node. Holo Master memantau kesehatan komponen di dalam setiap node pekerja dan memulai ulang komponen apa pun yang berada dalam kondisi tidak normal, sehingga mengurangi gangguan layanan.
Lapisan penyimpanan
Data Hologres disimpan di Pangu, sistem file terdistribusi milik Alibaba. Lapisan penyimpanan juga terintegrasi dengan sumber data eksternal:
MaxCompute: Hologres membaca data MaxCompute yang disimpan di Pangu. Pangu memungkinkan akses timbal balik yang efisien antara Hologres dan MaxCompute tanpa perpindahan data.
Object Storage Service (OSS) dan Data Lake Formation (DLF): Hologres melakukan kueri terhadap data di OSS dan DLF untuk mempercepat analisis di data lake. Format yang didukung mencakup CSV, ORC, Parquet, Hudi, Delta, dan Meta Data. Hologres juga dapat menulis data ke OSS untuk mengurangi biaya penyimpanan.