Topik ini menjelaskan keunggulan utama Lindorm dibandingkan Apache HBase.
Kategori | Lindorm | Apache HBase | |
Fitur inti | HBase API | Didukung | Didukung |
Data model | Mendukung berbagai model data, termasuk wide column (HBase API), table (SQL-like API), dan queue. Hubungi kami untuk informasi lebih lanjut mengenai model lainnya. | Hanya mendukung model wide column. | |
Global secondary index | Menyediakan global secondary index bawaan yang menjamin kueri transparan berkinerja tinggi dan memungkinkan redundansi on-demand untuk kolom yang tidak diindeks. Untuk informasi selengkapnya, lihat secondary index. | Memerlukan konfigurasi kompleks komponen eksternal. | |
Full-text search | Terpasang dengan mesin pencarian Solr untuk menyediakan akses terpadu ke penyimpanan, kueri multidimensi, dan pengindeksan teks penuh untuk set data dalam skala besar. Untuk informasi selengkapnya, lihat full-text index service. | Tidak didukung | |
Kinerja | Throughput | Memberikan throughput per node hingga 7 kali lipat dibandingkan Apache HBase. Untuk informasi selengkapnya, lihat Hasil pengujian. | Tidak dioptimalkan |
Latency spike | Menurunkan latensi P99 menjadi sepersepuluh dari Apache HBase. Untuk informasi selengkapnya, lihat Hasil pengujian. | Tidak dioptimalkan | |
Biaya | Data compression | Menggunakan algoritma Zstandard (ZSTD) yang telah dioptimalkan secara mendalam, ditulis ulang dengan Java Native Access (JNA) untuk mencegah core dump. Algoritma ini menggunakan pengambilan sampel kamus (dictionary sampling) sehingga meningkatkan rasio kompresi hingga 50% dibandingkan Snappy dan mencapai rasio kompresi hingga 10:1. | Secara default menggunakan Snappy. Penggunaan ZSTD memerlukan Hadoop 3.0 dan berisiko menyebabkan core dump. |
Encoding | Menggunakan algoritma IndexableDelta, yang memberikan rasio kompresi sama dengan algoritma DIFF namun menggandakan kecepatan akses. | Merekomendasikan algoritma DIFF, yang memberikan akses acak lebih lambat. | |
Hot and cold data separation | Secara otomatis melakukan tiering data, menyimpan data dingin dengan kompresi tinggi pada media berbiaya rendah. Hal ini mengurangi biaya penyimpanan hingga 70% dan meningkatkan kinerja akses data panas sebesar 15%. Untuk informasi selengkapnya, lihat hot and cold data separation. | Tidak didukung | |
Storage media | Mendukung berbagai media penyimpanan, termasuk ultra disk, standard SSD, local HDD, dan local SSD. Juga mendukung cold storage pada Object Storage Service (OSS) serta disk berkapasitas optimal yang sangat hemat biaya (segera hadir). | Tidak tersedia | |
Keandalan | Active-standby redundancy | Menyediakan solusi matang untuk penerapan kluster ganda, dilengkapi failover otomatis dan pemrosesan permintaan konkuren. Anda juga dapat membuat konfigurasi hybrid active-standby bersama instans HBase yang dikelola sendiri. | Tidak dioptimalkan dan tidak mendukung failover. |
Backup and restoration | Mendukung pencadangan data lebih dari 100 TB ke Object Storage Service (OSS). Menyediakan kemampuan lanjutan seperti RTO kurang dari 30 menit terlepas dari ukuran data, backup sesuai permintaan, dan point-in-time recovery. Untuk informasi selengkapnya, lihat Aktifkan backup dan pemulihan. | Tidak didukung | |
MTTR | Mencapai kecepatan pemulihan 10 kali lebih cepat dibandingkan Apache HBase, sehingga secara signifikan mengurangi mean time to repair (MTTR). | Tidak dioptimalkan | |
Multitenancy | Authentication and ACL | Menyediakan autentikasi username dan password serta manajemen ACL. Untuk informasi selengkapnya, lihat Kelola pengguna dan ACL. | Konfigurasinya kompleks |
Resource isolation | Menyediakan isolasi resource fisik antar penyewa melalui resource groups. | Tidak didukung | |
O&M dan diagnostik | O&M tools | Menyediakan sistem manajemen kluster berbasis GUI untuk mengelola tabel, namespace, group, dan ACL. Untuk informasi selengkapnya, lihat sistem manajemen kluster. | HBase Shell |
Data query | Mendukung kueri data baik melalui HBase Shell maupun tool kueri SQL interaktif dalam sistem manajemen kluster berbasis GUI. Untuk informasi selengkapnya, lihat Kueri data. | HBase Shell | |
Ekosistem | Data migration | Mendukung migrasi data online, otomatis, dan lintas versi dari berbagai versi HBase tanpa mengganggu aplikasi atau memerlukan perubahan kode. Untuk informasi selengkapnya, lihat Pengantar Lindorm Tunnel Service (LTS). | Hanya mendukung migrasi offline. |
MySQL data synchronization | Mendukung sinkronisasi penuh dan real-time data dari MySQL ke Lindorm. Untuk informasi selengkapnya, lihat Pengantar Lindorm Tunnel Service (LTS). | Memerlukan tool pihak ketiga dan tidak mendukung sinkronisasi inkremental online. | |
Spark analysis | Menawarkan integrasi terproduksi dengan Spark. Anda dapat menggunakan Spark SQL untuk menganalisis data Lindorm, melakukan pengarsipan inkremental dari Lindorm ke Spark (HDFS/OSS), serta mengembalikan hasil analisis offline ke Lindorm. | Tidak dioptimalkan. Integrasi data memerlukan upaya pengembangan yang signifikan. | |
MaxCompute | Menyediakan integrasi terproduksi. Untuk informasi selengkapnya, lihat Ekspor data lengkap ke MaxCompute. | Integrasi data memerlukan upaya pengembangan yang signifikan. | |
Log Service (SLS) | Mendukung impor data inkremental dari Log Service (SLS). Untuk informasi selengkapnya, lihat Pengantar Lindorm Tunnel Service (LTS). | Integrasi data memerlukan upaya pengembangan yang signifikan. | |
Kemampuan layanan | Service level agreement (SLA) | Termasuk jaminan service level agreement (SLA) dengan ketersediaan 99,9% untuk satu kluster dan 99,95% untuk penerapan kluster ganda berkeandalan tinggi. | Tidak tersedia |
O&M cost | Menyediakan layanan fully managed yang menghilangkan kompleksitas O&M database dan mengurangi beban operasional. | Tidak tersedia | |
Tim teknis | Didukung oleh tim khusus yang mencakup beberapa anggota PMC dan committer komunitas Apache. | Tidak tersedia | |
Pengalaman praktis | Telah teruji dalam skala besar, mendukung Festival Belanja Global 11.11 Alibaba selama sembilan tahun berturut-turut di puluhan ribu server. | Tidak tersedia | |
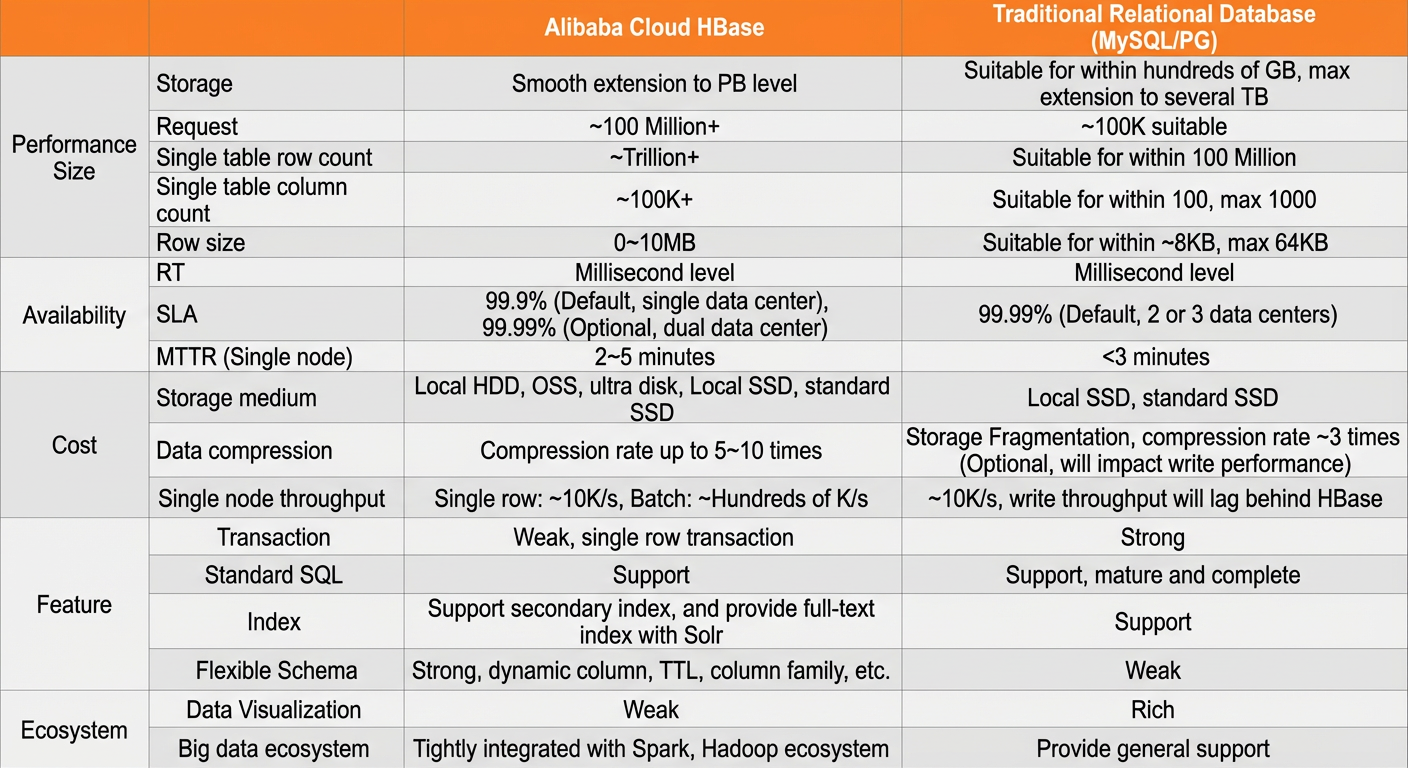
Perbandingan dengan database tradisional