Dokumen ini menyediakan metrik peringatan utama, konfigurasi yang direkomendasikan, serta contoh operasi dan pemeliharaan (O&M) untuk Realtime Compute for Apache Flink. Panduan ini dapat membantu Anda memantau kinerja sistem dan mendiagnosis kesalahan secara lebih efektif.
Prasyarat
Untuk informasi selengkapnya, lihat Configure monitoring and alerting. Pilih metode konfigurasi yang sesuai dengan layanan pemantauan yang digunakan oleh ruang kerja Anda.
Pemantauan multi-metrik di ARMS memerlukan custom PromQL. Jika Anda membutuhkan konfigurasi yang lebih sederhana, Anda tetap dapat menggunakan Cloud Monitor untuk mengonfigurasi peringatan.
Konfigurasi aturan peringatan yang direkomendasikan
|
Scenario |
Combined metric/Event name |
Rule configuration |
Level |
Action |
|
Job status event |
= FAILED (event alerting) |
P0 |
1. Periksa apakah kebijakan restart salah dikonfigurasi. Kami merekomendasikan penggunaan konfigurasi default. 2. Tentukan apakah penyebabnya adalah kebijakan restart atau JobManager atau TaskManager yang tidak normal. 3. Pulihkan pekerjaan dari snapshot terbaru atau checkpoint yang berhasil. |
|
|
Overview/Number of error recoveries per minute for the job |
≥ 1 for 1 consecutive period |
P0 |
1. Identifikasi masalahnya.
2. Pulihkan pekerjaan dari snapshot terbaru atau checkpoint yang berhasil. |
|
|
Number of successful checkpoints (5 min cumulative) |
≤ 0 for 1 consecutive period |
P0 |
1. Untuk informasi selengkapnya, lihat System checkpoints untuk memecahkan akar penyebab kegagalan. 2. Identifikasi masalahnya.
3. Perbarui konfigurasi secara dinamis atau pulihkan pekerjaan dari checkpoint terakhir yang berhasil. |
|
|
Overview/Business latency && Records in from source per second |
Maximum latency ≥ 180000 Input records ≥ 0 for 3 consecutive periods |
P1 |
1. Untuk informasi selengkapnya, lihat Metric description untuk menyelidiki penyebab latensi.
2. Ambil tindakan berdasarkan penyebabnya.
|
|
|
Overview/Records in from source per second && Source Raw Data Timestamp |
Input records ≤ 0 (business-dependent) Maximum idle time ≥ 60000 for 5 consecutive periods |
P1 |
1. Periksa taskmanager.log, flame graphs, dan metrik layanan hulu untuk memastikan apakah masalahnya disebabkan oleh tidak adanya data hulu, throttling, error, atau stack thread yang macet. 2. Ambil tindakan berdasarkan penyebabnya.
|
|
|
Overview/Records out to sink per second |
≤ 0 for 5 consecutive periods |
P1 |
1. Pastikan apakah data mencapai operator sink.
2. Pastikan apakah sink dapat menulis ke sistem eksternal.
3. Sebagai langkah sementara, aktifkan dual-write ke sistem backup storage. |
|
|
CPU/ CPU utilization of a single TM |
≥ 85 % for 10 consecutive periods |
P2 |
1. Gunakan flame graphs atau UI Flink untuk menemukan operator hot spot.
2. Tingkatkan tingkat paralelisme untuk operator bottleneck, atau alokasikan lebih banyak core CPU ke TaskManager. |
|
|
TM heap memory used |
≥ 90 % for 10 consecutive periods |
P2 |
1. Periksa log GC untuk mengidentifikasi masalahnya.
2. Ambil tindakan berdasarkan penyebabnya: Tambah ukuran heap atau tingkatkan tingkat paralelisme untuk mengurangi volume data per slot. |
Job availability
Job failure alert
Development console (ARMS)
-
Login ke Konsol Realtime Compute for Apache Flink. Di kolom Actions ruang kerja Anda, klik Console.
-
Di halaman , klik pekerjaan target.
-
Klik tab Alert Configuration.
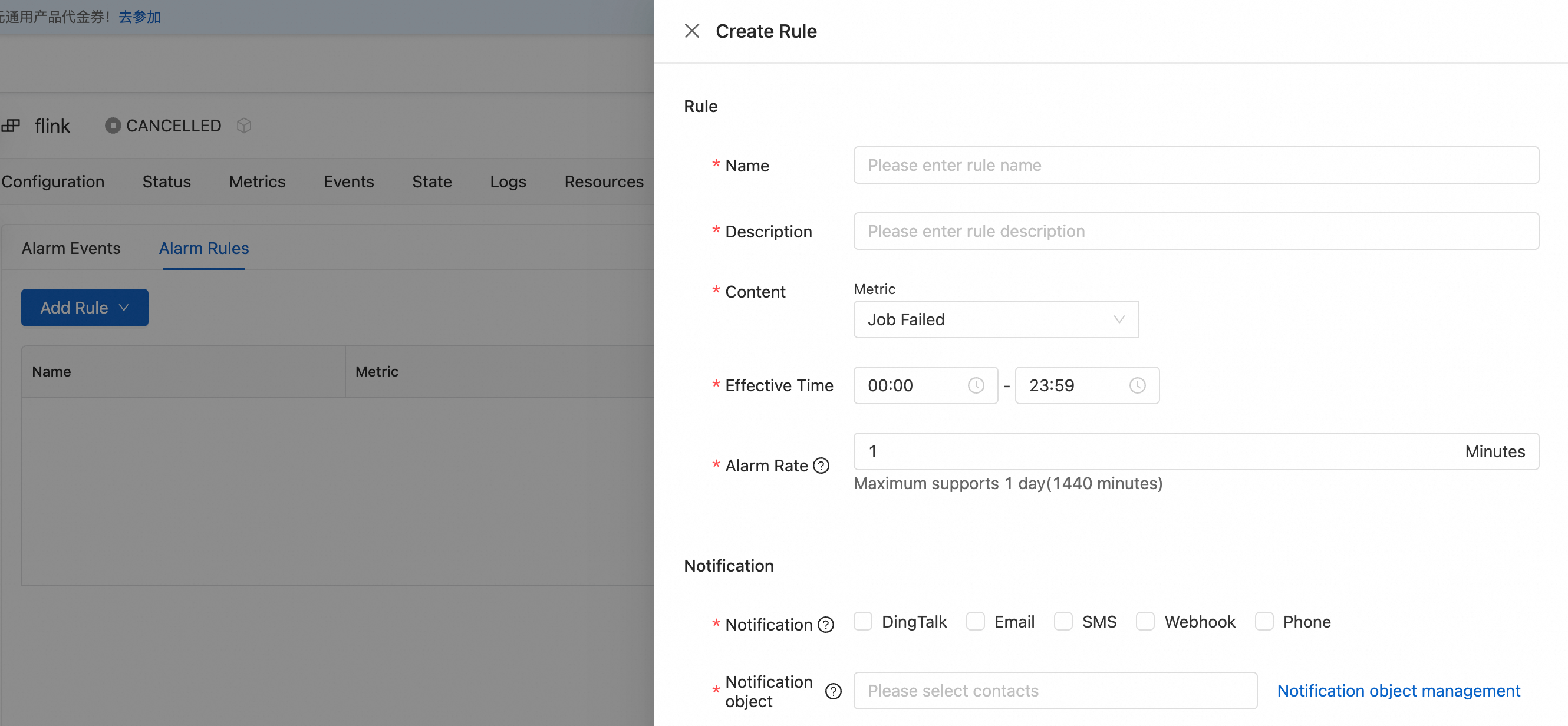
Cloud Monitor
-
Login ke Konsol Cloud Monitor.
-
Di panel navigasi sebelah kiri, pilih .
-
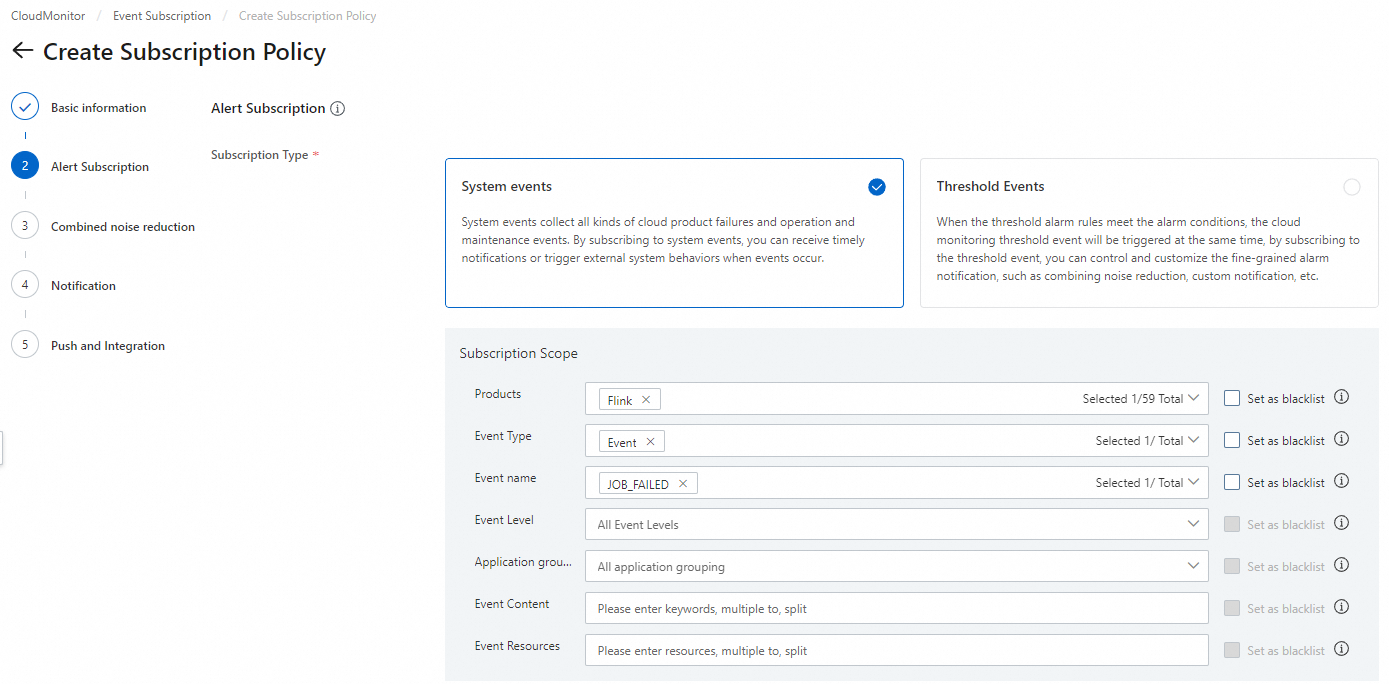
Di tab Subscription Policy, klik Create Subscription Policy.
-
Di halaman Create Subscription Policy, konfigurasikan parameter. Untuk informasi selengkapnya, lihat Manage event subscriptions (Recommended).
Job stability
Prevent frequent JobManager restarts
-
Metric:
Number of error recoveries per minute for the job -
Rule: Kirim peringatan jika pekerjaan melakukan restart dalam waktu 1 menit.
-
Recommended configuration:
-
Number of error recoveries per minute for the jobNilai metrik >= 1
-
Periode: 1 menit
-
Notifikasi: Panggilan telepon, pesan teks, email, dan WebHook (Critical)
-
Ensure checkpoint success rate
-
Metric:
Number of completed checkpoints per minute -
Rule: Kirim peringatan jika tidak ada checkpoint yang selesai dalam 5 menit.
-
Recommended configuration:
-
Number of completed checkpoints per minute -
Nilai metrik <= 0
-
Periode: 5 menit
-
Notifikasi: Panggilan telepon, pesan teks, email, dan WebHook (Critical)
-
Data timeliness
Ensure SLA for latency
-
Metrics:
-
Business latency -
Records in from source per second
-
-
Rule: Hasilkan peringatan jika data sedang diterima dan latensi bisnis melebihi 5 menit. Anda dapat menyesuaikan ambang batas dan tingkat peringatan sesuai kebutuhan.
-
Recommended configuration:
-
Business latencyMaksimum >= 300000
-
Records in from source per secondNilai metrik > 0
-
Periode: 5 menit
-
Upstream data stream interruption detection
-
Metrics:
-
Records in from source per second -
Age of unprocessed source data
-
-
Rule: Peringatan dipicu jika terdapat data masuk dan latensi layanan melebihi 5 menit (ambang batas dan tingkat peringatan dapat dikonfigurasi).
-
Recommended configuration:
-
Records in from source per secondNilai metrik <= 0
-
Age of unprocessed data at the sourceMaksimum > 60000
-
Periode: 5 menit
-
No downstream data output detection
-
Metric:
Records out to sink per second -
Rule: Hasilkan peringatan jika tidak ada output data selama lebih dari 5 menit. Anda dapat menyesuaikan ambang batas dan tingkat peringatan sesuai kebutuhan.
-
Recommended configuration:
-
Records out to sink per secondNilai metrik <= 0
-
Periode: 5 menit
-
Resource performance bottlenecks
CPU performance bottlenecks
-
Metric:
Single TM CPU utilization -
Rule: Peringatan jika penggunaan CPU melebihi 85% selama lebih dari 10 menit.
-
Recommended configuration:
-
CPU utilization of a single TMMaksimum >= 85
-
Periode: 10 menit
-
Memory performance bottlenecks
-
Metric: TM heap memory usage
-
Rule: Peringatan jika penggunaan memori heap melebihi 90% selama lebih dari 10 menit.
-
Recommended configuration:
-
TM heap memory usageMaksimum >= Ambang batas (90%)
Tentukan ambang batas ini berdasarkan penggunaan memori heap yang terlihat di halaman . Misalnya, jika penggunaannya adalah 194 MB / 413 MB, atur ambang batas menjadi 372 MB (90% dari 413 MB).
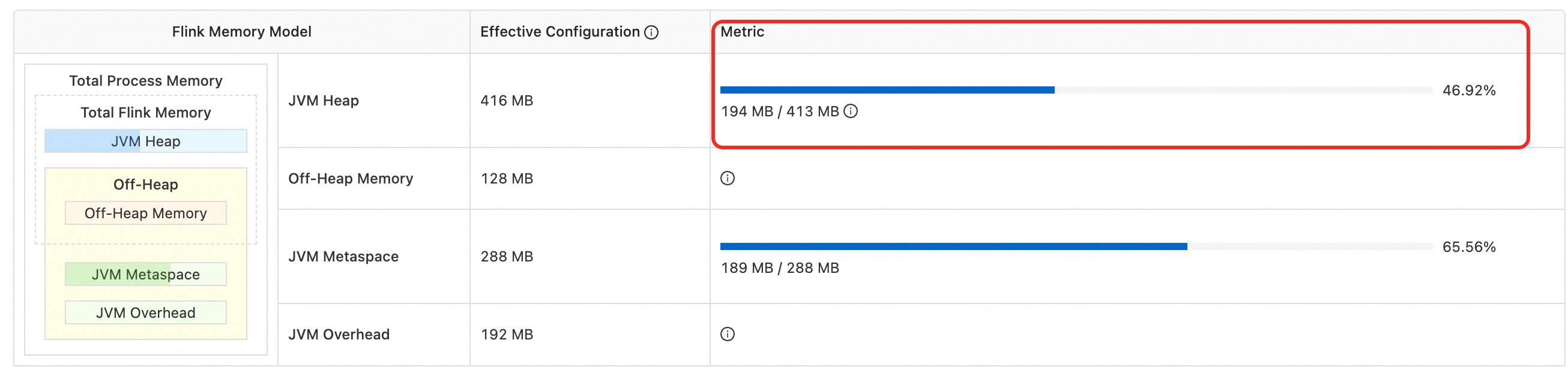
-
Periode: 10 menit
-