Topik ini menjawab pertanyaan umum mengenai pemantauan, peringatan, dan log untuk Realtime Compute for Apache Flink.
-
Bagaimana cara memeriksa jenis layanan pemantauan yang digunakan oleh ruang kerja?
-
Apa saja keterbatasan peringatan CloudMonitor dibandingkan ARMS?
-
Bagaimana cara mengonfigurasi atau menambahkan kontak peringatan?
-
Bagaimana cara menonaktifkan Prometheus Service yang diaktifkan secara otomatis?
-
Bagaimana cara mengonfigurasi pemantauan dan peringatan untuk restart pekerjaan Flink?
-
Bagaimana cara mengatur parameter tingkat log untuk satu kelas?
-
Pekerjaan gagal dimulai setelah mengonfigurasi log untuk SLS
-
Bagaimana cara melihat, mencari, dan menganalisis log operasional Flink historis?
-
Bagaimana cara mengatasi masalah di mana log dari metode non-statis tidak ditampilkan ke SLS?
Bagaimana cara memeriksa jenis layanan pemantauan yang digunakan oleh ruang kerja?
Jenis layanan pemantauan dipilih saat Anda membuat ruang kerja dan tidak dapat diubah setelahnya. Untuk memeriksa jenis yang digunakan oleh ruang kerja Anda, buka Operation Center > Job O&M dan klik nama pekerjaan. Jika tab Alert Configuration muncul, berarti ruang kerja menggunakan layanan Prometheus Service bayar sesuai penggunaan, yang merupakan bagian dari Application Real-Time Monitoring Service (ARMS). Jika tab tersebut tidak tersedia, berarti ruang kerja menggunakan layanan CloudMonitor gratis. Untuk petunjuk konfigurasi masing-masing jenis layanan, lihat Pemantauan dan peringatan pekerjaan.

Apa saja keterbatasan peringatan CloudMonitor dibandingkan ARMS?
CloudMonitor memiliki tiga keterbatasan dibandingkan ARMS:
-
Sintaks analisis kueri tidak didukung.
-
Kurva pada granularitas subtask tidak tersedia. Dalam skenario dengan beberapa sumber dan subtask, hal ini menyulitkan pelacakan cepat terhadap masalah latensi setelah pengelompokan.
-
Metrik dari instrumenasi kustom dalam kode pengguna tidak dapat dilihat, sehingga menyulitkan troubleshooting.
Bagaimana cara mengonfigurasi atau menambahkan kontak peringatan?
Saat menggunakan peringatan konsol CloudMonitor atau ARMS, tambahkan atau konfigurasikan kontak di konsol yang sesuai. Untuk detailnya, lihat Konfigurasi pemantauan dan peringatan.
Jika ruang kerja Anda menggunakan ARMS dan Anda mengonfigurasi peringatan metrik atau kegagalan pekerjaan untuk satu pekerjaan langsung di Konsol pengembangan Realtime Compute for Apache Flink, ikuti langkah-langkah berikut untuk menambahkan atau mengonfigurasi kontak peringatan.
-
Akses halaman konfigurasi peringatan.
-
Masuk ke Konsol manajemen Realtime Compute for Apache Flink. Di kolom Operation ruang kerja target, klik Console.
-
Di halaman Operation Center > Job O&M, klik nama pekerjaan target.
-
Klik tab Alert Configuration.
-
-
Di tab Alert Rules, pilih Add Alert Rule > Custom Rule untuk membuka panel pembuatan aturan.
-
Konfigurasi atau tambahkan kontak peringatan.
-
Tambahkan: Klik Notification Recipient Management di sebelah parameter Notification Recipient untuk menambahkan kontak, robot DingTalk, dan lainnya. Untuk informasi tentang mengonfigurasi peringatan untuk robot DingTalk, webhook, dan robot Lark, lihat bagian FAQ dalam panduan peringatan. Setelah menambahkan kontak, jika Anda menggunakan panggilan telepon untuk peringatan, pastikan nomor telepon penerima telah diverifikasi. Jika tidak, peringatan tidak akan dikirimkan. Jika label Unverified muncul di kolom Phone untuk kontak target di tab Contacts, klik label tersebut untuk menyelesaikan verifikasi.

-
Konfigurasi: Untuk parameter Notification Recipient, pilih kontak peringatan yang diinginkan. Jika kontak tidak terdaftar, tambahkan dengan mengikuti langkah-langkah di atas.
-
Bagaimana cara menonaktifkan Prometheus Service yang diaktifkan secara otomatis?
Jika Anda memilih layanan Prometheus Service bayar sesuai penggunaan saat membuat ruang kerja, ARMS akan diaktifkan secara otomatis. Untuk berhenti menggunakannya, uninstall instans Prometheus dari konsol Prometheus.
Penting
Menguninstall instans Prometheus untuk suatu ruang kerja akan menghentikan pengumpulan data pemantauan untuk ruang kerja tersebut dan mengakibatkan hilangnya kurva data pemantauan pekerjaan. Jika suatu pekerjaan mengalami anomali, Anda tidak dapat melacak waktu awal terjadinya anomali atau menerima peringatan pemantauan. Lakukan dengan hati-hati.
-
Masuk ke Konsol Prometheus.
-
Di panel navigasi kiri, klik Instance List.
-
Dari daftar drop-down Tag Filtering, pilih ID atau nama ruang kerja target.
-
Temukan instans dengan Instance Type yang diatur ke Prometheus for Flink Serverless dan klik Uninstall di kolom Operation.
-
Di kotak dialog, klik Confirm.
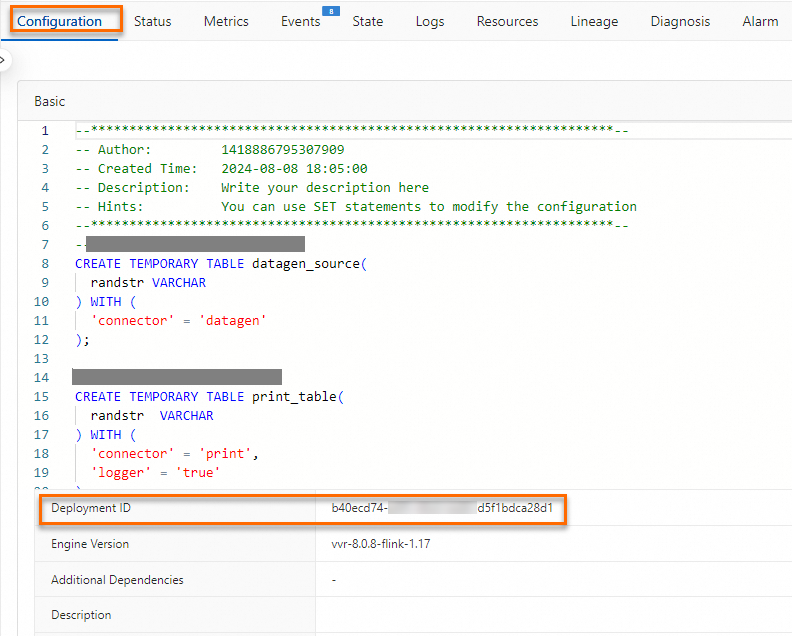
Bagaimana cara menemukan pekerjaan yang memicu peringatan?
Peristiwa peringatan berisi JobID dan Deployment ID. Karena JobID berubah setelah failover pekerjaan, gunakan Deployment ID untuk mengidentifikasi pekerjaan spesifik yang melaporkan kesalahan.
Lihat Deployment ID di salah satu lokasi berikut:
-
Di Konsol pengembangan Realtime Compute for Apache Flink, di tab Deployment Details, temukan Deployment ID di bagian Basic Configuration.
-
Di URL pekerjaan.

Bagaimana cara mengonfigurasi pemantauan dan peringatan untuk restart pekerjaan Flink?
Konsol pengembangan Realtime Compute for Apache Flink mengonfigurasi aturan peringatan berdasarkan metrik Flink. Oleh karena itu, setelah failover pekerjaan, kurva metrik tidak ditampilkan dan peringatan tidak dapat dipicu. Untuk memberi peringatan saat pekerjaan direstart, konfigurasikan aturan kustom di ARMS berdasarkan laju pertumbuhan instan dari metrik flink_jobmanager_job_numRestarts. Hal ini memungkinkan pemberian peringatan untuk peristiwa failover job manager (JM).
-
Masuk ke Konsol manajemen Realtime Compute for Apache Flink.
-
Di kolom Operation ruang kerja target, klik More > Monitoring Metrics Configuration untuk membuka konsol ARMS.
-
Di halaman Alert Rules, klik Create Prometheus Alert Rule.
-
Atur Detection Type ke Custom PromQL dan pilih instans peringatan.
-
Masukkan ekspresi Prometheus Query Language (PromQL) kustom. Contohnya:
irate(flink_jobmanager_job_numRestarts{jobId=~"$jobId",deploymentId=~"$deploymentId"}[1m])>0Ekspresi ini mengkueri metrik
flink_jobmanager_job_numRestartsselama 1 menit terakhir dan memicu peringatan jika laju perubahan instan lebih besar dari 0. -
Klik Finish.
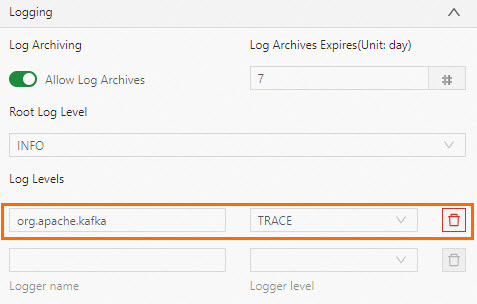
Bagaimana cara mengatur parameter tingkat log untuk satu kelas?
Konfigurasikan parameter tingkat log per kelas di Log Levels, bukan di Other Configuration. Misalnya, untuk mengatur tingkat log konektor Kafka, tambahkan parameter berikut ke Log Levels:
-
log4j.logger.org.apache.kafka.clients.consumer=trace(untuk tabel sumber) -
log4j.logger.org.apache.kafka.clients.producer=trace(untuk tabel sink)
Bagaimana cara mengaktifkan parameter log GC?
Di halaman Operation Center > Job O&M, klik nama pekerjaan target. Di tab Deployment Details, di bawah Parameter Settings, tambahkan konfigurasi berikut ke Other Configuration dan simpan untuk menerapkan.
env.java.opts: >-
-XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:/flink/log/gc.log
-XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=2 -XX:GCLogFileSize=50M
Pekerjaan gagal dimulai setelah mengonfigurasi log untuk SLS
Setelah mengonfigurasi pekerjaan untuk mengeluarkan log ke Simple Log Service (SLS), pekerjaan gagal dengan pesan Job startup failed. Please retry. dan error berikut:
Unknown ApiException {exceptionType=com.ververica.platform.appmanager.controller.domain.TemplatesRenderException, exceptionMessage=Failed to render {userConfiguredLoggers={}, jobId=3fd090ea-81fc-4983-ace1-0e0e7b******, rootLoggerLogLevel=INFO, clusterName=f7dba7ec27****, deploymentId=41529785-ab12-405b-82a8-1b1d73******, namespace=flinktest-default, priorityClassName=flink-p5, deploymentName=test}}
029999 202312121531-8SHEUBJUJUError ini terjadi ketika variabel template Twig — seperti namespace atau deploymentId — tidak sengaja dimodifikasi selama konfigurasi log.
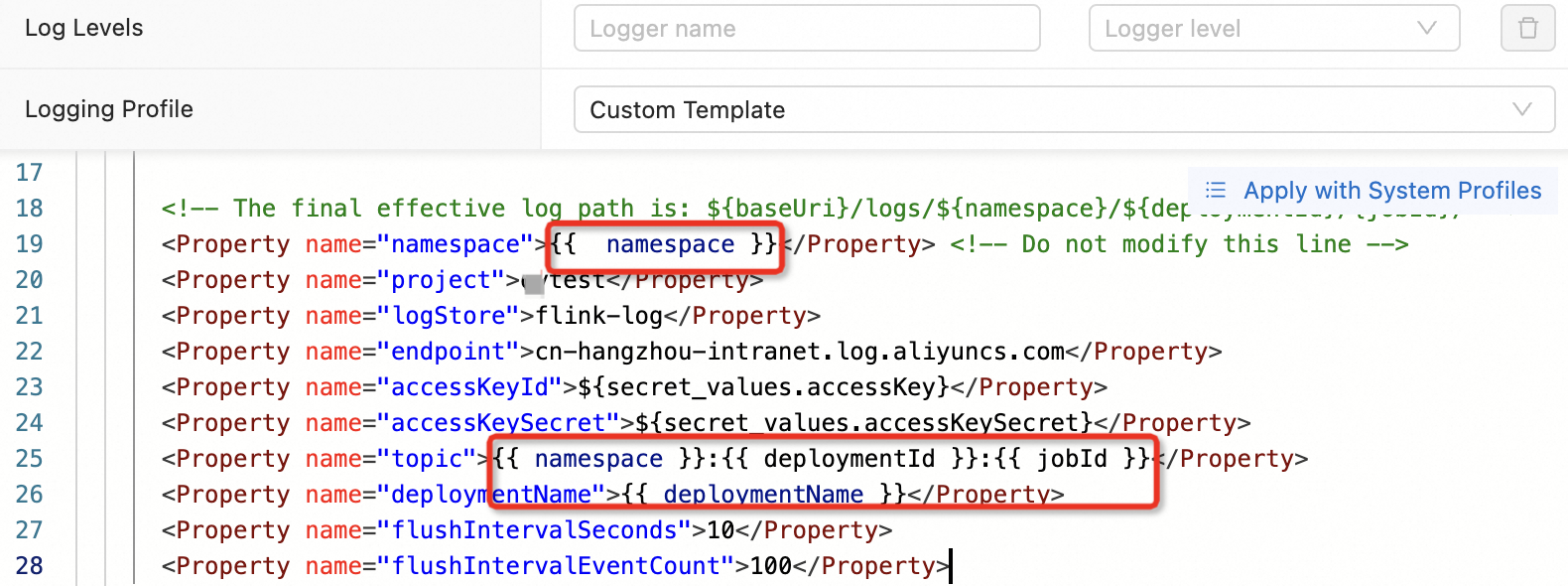
Untuk memperbaikinya, konfigurasi ulang pengaturan log dengan mengikuti Konfigurasi output log pekerjaan. Jangan modifikasi variabel Twig dalam templat konfigurasi log.
Bagaimana cara melihat, mencari, dan menganalisis log operasional Flink historis?
Realtime Compute for Apache Flink menyediakan dua cara untuk mengakses log operasional historis.
-
Di konsol pengembangan: Di tab Deployment Details, fitur Log Archiving diaktifkan secara default dengan periode retensi 7 hari. 5 MB log operasional terbaru disimpan. Sesuaikan Log Archive Retention Period sesuai kebutuhan.

-
Di penyimpanan eksternal: Konfigurasikan pekerjaan untuk mengirim log ke Object Storage Service (OSS), SLS, atau Kafka, dan atur tingkat log untuk output. Untuk detailnya, lihat Konfigurasi output log pekerjaan.
Bagaimana cara mengatasi masalah di mana log dari metode non-statis tidak ditampilkan ke SLS?
Karena logika implementasi SLS Logger Appender, log dari metode non-statis tidak ditampilkan ke SLS.
Perbaiki dengan mendeklarasikan logger menggunakan pola statis standar:
private static final Logger LOG = LoggerFactory.getLogger(xxx.class);Data ditulis dengan benar, tetapi ikhtisar status pekerjaan Flink menunjukkan 0 data. Apa yang harus saya lakukan?
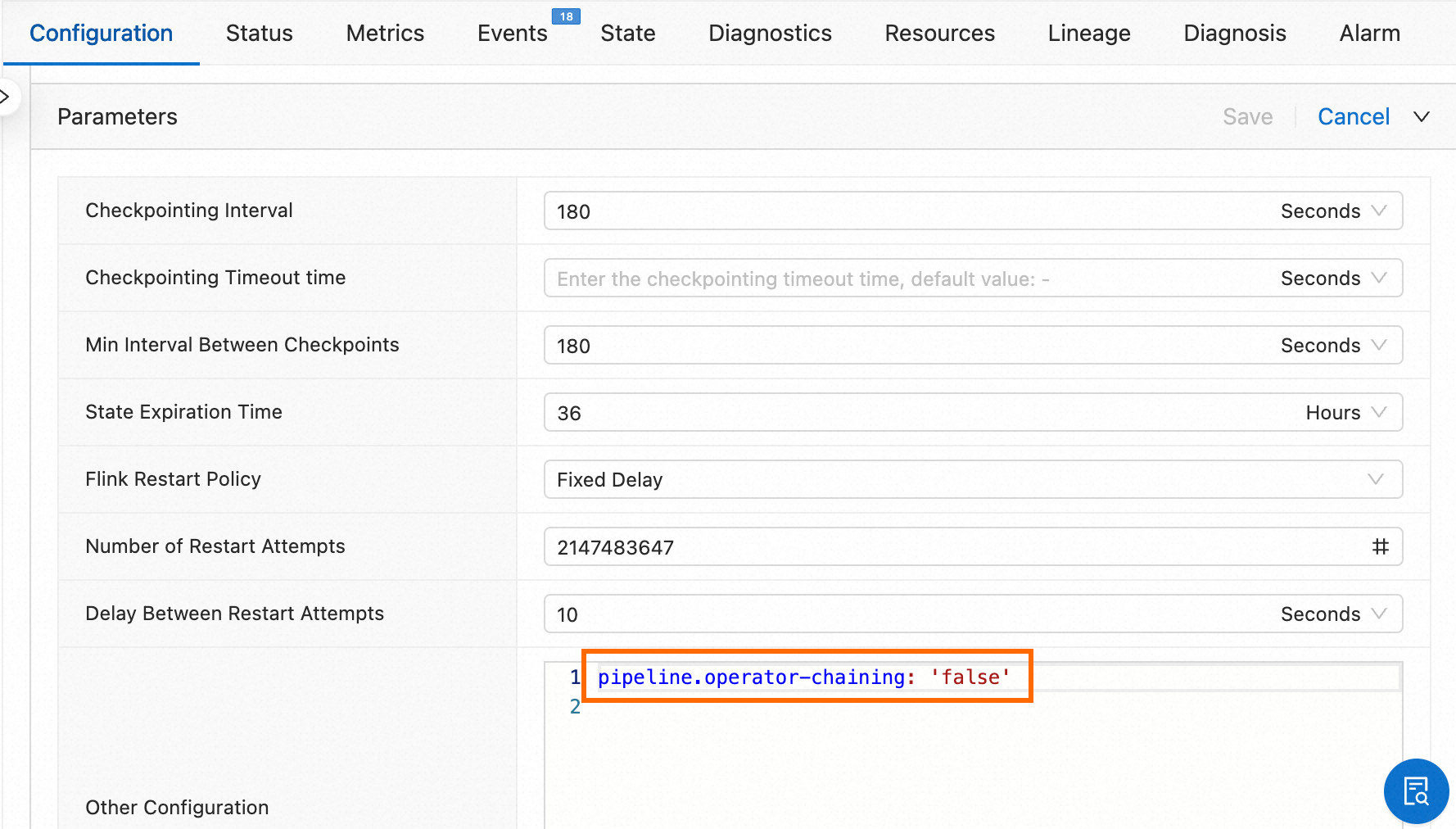
Hal ini terjadi ketika pekerjaan hanya memiliki satu node, dengan sumber hanya memiliki output dan sink hanya memiliki input. Dalam topologi ini, Flink tidak menampilkan volume data di graf topologi.
Untuk melihat trafik data di graf topologi, pisahkan operator sumber dan sink menjadi operator independen. Tambahkan parameter berikut ke Other Configuration di bawah Parameter Settings di tab Deployment Details:
pipeline.operator-chaining: 'false'Buka Operation Center > Job O&M, klik nama pekerjaan, lalu temukan Other Configuration di bawah Parameter Settings di tab Deployment Details.
Apa yang harus saya lakukan jika pekerjaan DataStream tidak memiliki delay, tetapi kurva output menunjukkan adanya delay?
Jika metrik CurrentEmitEventTimeLag dan CurrentFetchEventTimeLag menunjukkan delay sekitar 52 tahun, berarti pekerjaan menggunakan konektor Kafka komunitas, bukan konektor bawaan Flink. Konektor komunitas tidak mengimplementasikan logika pelaporan metrik untuk kurva ini, sehingga nilainya tampak abnormal.
Beralihlah ke dependensi konektor bawaan Flink. Temukan versi yang tepat di Maven Repository.
Apa yang harus saya lakukan jika NullPointerException dilemparkan di log Task Manager (TM) pekerjaan DataStream tanpa stack trace yang lengkap?
JVM menghilangkan stack trace untuk exception yang sering dilemparkan sebagai optimisasi performa. Tambahkan flag berikut ke Other Configuration di bawah Parameter Settings di tab Deployment Details untuk menonaktifkan perilaku ini:
env.java.opts: "-XX:-OmitStackTraceInFastThrow"Buka Operation Center > Job O&M, klik nama pekerjaan, lalu temukan Other Configuration di bawah Parameter Settings di tab Deployment Details.
Metrik currentFetchEventTimeLag menunjukkan nilai yang sangat tinggi setelah pekerjaan direstart dengan konektor Hologres
-
Gejala
Setelah pekerjaan Flink yang menggunakan konektor Hologres direstart atau dilanjutkan dari checkpoint, metrik
currentFetchEventTimeLagsempat melonjak ke nilai yang sangat tinggi (jam bahkan hari), lalu perlahan kembali normal. -
Penyebab
Metrik
currentFetchEventTimeLagdihitung sebagaiSystem.currentTimeMillis() - record.getBinlogTimestamp() / 1000. Metrik ini memiliki karakteristik berikut:-
Merupakan nilai snapshot sesaat yang tidak dipertahankan bersama checkpoint. Setelah pekerjaan direstart, nilainya diatur ulang ke 0.
-
Hanya diperbarui saat catatan data aktual dikonsumsi. Catatan heartbeat tidak memicu pembaruan.
Setelah pekerjaan direstart, konektor Hologres melanjutkan konsumsi binlog dari posisi checkpoint terakhir. Operasi internal Hologres — seperti compaction, perubahan skema, dan pemeliharaan partisi — dapat menghasilkan catatan binlog historis dengan timestamp lebih awal. Saat catatan historis ini dikonsumsi, selisih besar antara waktu sistem saat ini dan timestamp catatan menyebabkan lonjakan metrik. Metrik kembali normal setelah semua data historis dikonsumsi dan pekerjaan menyusul data real-time.
-
-
Solusi
Anomali metrik ini merupakan perilaku yang diketahui dari konektor Hologres saat pekerjaan direstart dan tidak memengaruhi kebenaran pemrosesan data. Verifikasi bahwa besarnya lonjakan metrik sesuai dengan waktu idle pekerjaan. Metrik akan kembali ke level normal setelah pekerjaan selesai mengonsumsi data historis dan menyusul data real-time.