Topik ini mencakup masalah umum terkait performa job.
-
Bagaimana cara mengatasi efisiensi rendah dan backpressure saat membaca seluruh tabel?
-
Apa arti indikator warna pada Durasi Status untuk subtask vertex di ikhtisar job?
-
Bagaimana cara mengoptimalkan job Flink SQL yang mengalami backpressure akibat hotspot data?
-
Bagaimana cara mendiagnosis ketidakstabilan laju konsumsi data hulu?
Bagaimana cara memisahkan node operator?
Di halaman , klik nama job target. Di tab Deployment Details, pada bagian Runtime Parameter Settings, tambahkan kode berikut di Other Settings, lalu simpan untuk menerapkan.
pipeline.operator-chaining: 'false'Apa saja teknik optimasi Group Aggregate?
-
Aktifkan MiniBatch (meningkatkan throughput)
MiniBatch menyimpan data masukan sebelum memicu pemrosesan. Hal ini mengurangi frekuensi akses State, meningkatkan throughput, dan menurunkan volume output.
MiniBatch memicu pemrosesan mikro-batch berdasarkan pesan event yang dimasukkan pada interval tertentu di sumber.
-
Skenario
Pemrosesan mikro-batch menukar latensi yang sedikit lebih tinggi dengan throughput yang jauh lebih tinggi. Jangan aktifkan jika Anda memerlukan latensi ultra-rendah. Untuk sebagian besar skenario agregasi, mengaktifkan MiniBatch secara signifikan meningkatkan performa sistem.
-
Cara mengaktifkan
MiniBatch dinonaktifkan secara default. Untuk mengaktifkannya, buka tab Deployment Details job target, lalu pada bagian Runtime Parameter Settings di bawah Other Settings, tambahkan kode berikut.
table.exec.mini-batch.enabled: true table.exec.mini-batch.allow-latency: 5sParameter tersebut dijelaskan dalam tabel berikut.
Parameter
Deskripsi
table.exec.mini-batch.enabled
Apakah mini-batch diaktifkan atau tidak.
table.exec.mini-batch.allow-latency
Interval waktu antara output batch.
-
-
Aktifkan LocalGlobal (mengatasi masalah hotspot data umum)
Mekanisme LocalGlobal menggunakan LocalAgg untuk melakukan pre-agregasi data yang miring, sehingga mengurangi tekanan hotspot pada GlobalAgg dan meningkatkan performa keseluruhan.
LocalGlobal membagi satu agregasi menjadi dua tahap: Local dan Global—mirip dengan fase Combine dan Reduce dalam MapReduce. Pada tahap pertama, node hulu menyimpan dan mengagregasi data secara lokal (localAgg), lalu menghasilkan akumulator inkremental. Pada tahap kedua, akumulator tersebut digabungkan (Merge) untuk menghasilkan hasil akhir (GlobalAgg).
-
Skenario
Meningkatkan performa untuk agregasi standar (seperti SUM, COUNT, MAX, MIN, dan AVG) serta mengatasi masalah hotspot data dalam skenario tersebut.
-
Batasan
LocalGlobal diaktifkan secara default, tetapi memiliki batasan berikut:
-
MiniBatch harus diaktifkan.
-
AggregateFunction Anda harus mengimplementasikan Merge.
-
-
Verifikasi apakah perubahan telah berlaku
Periksa apakah topologi yang dihasilkan berisi node bernama GlobalGroupAggregate atau LocalGroupAggregate.
-
-
Aktifkan PartialFinal (mengatasi masalah hotspot COUNT DISTINCT)
Untuk mengatasi hotspot COUNT DISTINCT, biasanya Anda harus menulis ulang kueri secara manual menjadi agregasi dua tahap (menambahkan lapisan pengacakan berbasis modulo). Realtime Compute for Apache Flink kini menyediakan pengacakan COUNT DISTINCT otomatis melalui optimasi PartialFinal—tanpa perlu penulisan ulang manual.
LocalGlobal bekerja baik untuk agregasi standar tetapi memberikan manfaat kecil untuk COUNT DISTINCT. Selama agregasi lokal, tingkat deduplikasi kunci unik tetap rendah, sehingga hotspot tetap terjadi di node global.
-
Skenario
Gunakan ketika COUNT DISTINCT gagal memenuhi persyaratan performa node agregasi.
Penting-
Jangan gunakan optimasi PartialFinal pada Flink SQL yang mencakup UDAF.
-
Hindari PartialFinal ketika volume data kecil—hal ini menimbulkan pengacakan jaringan yang tidak perlu dan membuang sumber daya.
-
-
Cara mengaktifkan
Fitur ini dinonaktifkan secara default. Untuk mengaktifkannya, pada tab Deployment Details job target, di bagian Runtime Parameter Settings, masukkan kode berikut di kolom Other Configurations.
table.optimizer.distinct-agg.split.enabled: true -
Verifikasi efektivitas perubahan
Periksa apakah topologi yang dihasilkan berubah dari satu tahap agregasi menjadi dua tahap.
-
-
Tulis ulang AGG WITH CASE WHEN menjadi sintaks AGG WITH FILTER (meningkatkan performa untuk skenario multiple COUNT DISTINCT)
Jika job Anda menghitung UV berdasarkan dimensi—seperti total UV, UV client mobile, dan UV PC—gunakan sintaks AGG WITH FILTER standar alih-alih CASE WHEN. Pengoptimal SQL Realtime Compute mengenali parameter Filter, sehingga beberapa operasi COUNT DISTINCT pada bidang yang sama dapat berbagi State dan mengurangi I/O State. Pengujian performa menunjukkan bahwa penulisan ulang ini dapat menggandakan performa.
-
Skenario
Keuntungan performa signifikan terjadi ketika menghitung beberapa hasil COUNT DISTINCT pada bidang yang sama di bawah kondisi berbeda.
-
Teks asli
COUNT(distinct visitor_id) as UV1 , COUNT(distinct case when is_wireless='y' then visitor_id else null end) as UV2 -
Sintaks yang dioptimalkan
COUNT(distinct visitor_id) as UV1 , COUNT(distinct visitor_id) filter (where is_wireless='y') as UV2
-
Apa saja teknik optimasi TopN?
-
Algoritma TopN
Jika input TopN adalah aliran append-only (misalnya, dari SLS), hanya tersedia satu algoritma: AppendRank. Jika input adalah aliran update (misalnya, setelah AGG atau JOIN), tersedia dua algoritma, diurutkan dari performa tertinggi ke terendah: UpdateFastRank dan RetractRank. Nama algoritma muncul pada label node topologi.
-
AppendRank: Hanya didukung untuk aliran append-only.
-
UpdateFastRank: Optimal untuk aliran update.
-
RetractRank: Algoritma fallback untuk aliran update. Performa lebih rendah. Dalam beberapa kasus, dapat dioptimalkan menjadi UpdateFastRank.
Untuk mengoptimalkan RetractRank menjadi UpdateFastRank, tiga kondisi berikut harus terpenuhi:
-
Aliran input harus merupakan aliran update.
-
Aliran input harus mencakup informasi Primary Key—misalnya, setelah agregasi GROUP BY.
-
Bidang pengurutan harus diperbarui secara monotonik dalam arah berlawanan dengan pengurutan. Misalnya, ORDER BY COUNT, COUNT_DISTINCT, atau SUM (nilai positif) DESC.
Untuk memastikan UpdateFastRank digunakan dengan ORDER BY SUM DESC, tambahkan kondisi filter yang menjamin total_fee bernilai positif.
insert into print_test SELECT cate_id, seller_id, stat_date, pay_ord_amt -- Abaikan rownum untuk mengurangi output tabel sink. FROM ( SELECT *, ROW_NUMBER () OVER ( PARTITION BY cate_id, stat_date -- Sertakan bidang waktu untuk mencegah korupsi data akibat State TTL. ORDER BY pay_ord_amt DESC ) as rownum -- Urutkan berdasarkan hasil sum hulu. FROM ( SELECT cate_id, seller_id, stat_date, -- Penting: Nyatakan semua input SUM sebagai positif, memastikan peningkatan monotonik. -- Hal ini memungkinkan TopN menggunakan algoritma teroptimalkan dan hanya mengambil 100 catatan teratas. sum (total_fee) filter ( where total_fee >= 0 ) as pay_ord_amt FROM random_test WHERE total_fee >= 0 GROUP BY cate_name, seller_id, stat_date, cate_id ) a ) WHERE rownum <= 100; -
-
Metode optimasi TopN
-
No Ranking Output Optimization
Jika output TopN Anda tidak perlu menampilkan nilai rownum, abaikan nilai tersebut dan lakukan pengurutan hanya sekali di antarmuka depan. Hal ini secara drastis mengurangi volume output tabel sink. Untuk detailnya, lihat Top-N.
-
Tingkatkan ukuran cache TopN
TopN menggunakan lapisan State Cache untuk meningkatkan efisiensi akses State. Tingkat hit cache dihitung sebagai berikut.
cache_hit = cache_size*parallelism/top_n/partition_key_numMisalnya, dengan Top100, ukuran cache 10.000, paralelisme 50, dan 100.000 kunci partisi, tingkat hit hanya 10000*50/100/100000=5%. Tingkat hit rendah menyebabkan sebagian besar permintaan mengakses State berbasis disk, menciptakan gangguan pada metrik state seek dan sangat menurunkan performa.
Ketika kardinalitas kunci partisi sangat tinggi, tingkatkan ukuran cache TopN dan memori heap sesuai kebutuhan. Untuk detailnya, lihat Konfigurasi pengaturan penyebaran job.
table.exec.rank.topn-cache-size: 200000Ukuran cache default adalah 10.000. Meningkatkannya menjadi 200.000 menaikkan tingkat hit teoretis menjadi
200000*50/100/100000 = 100%. -
Sertakan bidang berbasis waktu dalam PartitionBy
Untuk peringkat harian, sertakan bidang Day. Tanpa itu, State TTL dapat merusak hasil TopN akhir.
-
Apa solusi deduplikasi yang efisien?
Data sumber di Realtime Compute for Apache Flink terkadang mengandung duplikat. Pengguna sering meminta deduplikasi. Realtime Compute mendukung dua strategi: simpan baris pertama (Deduplicate Keep FirstRow) dan simpan baris terakhir (Deduplicate Keep LastRow).
-
Sintaks
SQL tidak memiliki sintaks deduplikasi langsung, sehingga kami menggunakan ROW_NUMBER OVER WINDOW untuk mengimplementasikannya. Deduplikasi pada dasarnya merupakan bentuk khusus dari TopN.
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY col1[, col2..] ORDER BY timeAttributeCol [asc|desc]) AS rownum FROM table_name) WHERE rownum = 1Parameter
Deskripsi
ROW_NUMBER()
Fungsi window yang memberikan nomor baris mulai dari 1.
PARTITION BY col1[, col2..]
Opsional. Kolom yang menentukan partisi (kunci deduplikasi).
ORDER BY timeAttributeCol [asc|desc])
Kolom yang digunakan untuk pengurutan. Harus berupa bidang atribut waktu (Proctime atau Rowtime). Gunakan urutan ascending untuk Keep FirstRow atau descending untuk Keep LastRow.
rownum
Hanya
rownum=1ataurownum<=1yang didukung.Seperti yang ditunjukkan di atas, deduplikasi memerlukan dua lapisan kueri:
-
Gunakan
ROW_NUMBER()untuk mengurutkan data berdasarkan atribut waktu dan memberikan peringkat.-
Jika bidang pengurutan adalah Proctime, Flink melakukan deduplikasi berdasarkan waktu sistem, menghasilkan hasil non-deterministik.
-
Jika bidang pengurutan adalah Rowtime, Flink melakukan deduplikasi berdasarkan Waktu bisnis, menghasilkan hasil deterministik.
-
-
Filter berdasarkan peringkat untuk menyimpan hanya baris pertama, sehingga mencapai deduplikasi.
Data dapat diurutkan secara ascending atau descending berdasarkan kolom waktu:
-
Deduplicate Keep FirstRow: Urutan ascending, simpan baris pertama.
-
Deduplicate Keep LastRow: Urutan descending, simpan baris pertama.
-
-
-
Deduplicate Keep FirstRow
Strategi ini menyimpan kemunculan pertama setiap kunci dan membuang duplikat berikutnya. Strategi ini hanya menyimpan data kunci di State, sehingga menawarkan performa lebih baik. Contoh:
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY b ORDER BY proctime) as rowNum FROM T ) WHERE rowNum = 1Contoh ini melakukan deduplikasi tabel T berdasarkan bidang b, menyimpan baris pertama berdasarkan waktu sistem. Di sini, proctime adalah bidang atribut Processing Time di tabel sumber T. Saat melakukan deduplikasi berdasarkan waktu sistem, Anda dapat menyederhanakan proctime menjadi pemanggilan fungsi proctime() dan menghilangkan deklarasi eksplisit bidang.
-
Deduplicate Keep LastRow
Strategi ini menyimpan kemunculan terakhir setiap kunci. Performanya sedikit lebih baik daripada LAST_VALUE. Contoh:
SELECT * FROM ( SELECT *, ROW_NUMBER() OVER (PARTITION BY b, d ORDER BY rowtime DESC) as rowNum FROM T ) WHERE rowNum = 1Contoh ini melakukan deduplikasi tabel T berdasarkan bidang b dan d, menyimpan baris terakhir berdasarkan Waktu bisnis. Di sini, rowtime adalah bidang atribut Event Time di tabel sumber T.
Apa yang perlu diperhatikan saat menggunakan fungsi bawaan?
-
Ganti user-defined function dengan fungsi bawaan
Realtime Compute terus mengoptimalkan fungsi bawaan. Lebih disarankan menggunakan fungsi bawaan daripada user-defined function. Optimasi utama meliputi:
-
Mengurangi overhead serialisasi dan deserialisasi.
-
Operasi langsung pada level byte.
-
-
Gunakan pemisah karakter tunggal dalam fungsi KEY VALUE
Signature KEY VALUE:
KEYVALUE(content, keyValueSplit, keySplit, keyName). Ketika keyValueSplit dan keySplit berupa karakter tunggal (seperti titik dua ":" atau koma ","), sistem menggunakan algoritma teroptimalkan untuk langsung menemukan keyName dalam data biner tanpa memecah seluruh konten—meningkatkan performa sekitar 30%. -
Catatan operasi LIKE
-
Untuk StartWith, gunakan
LIKE 'xxx%'. -
Untuk EndWith, gunakan
LIKE '%xxx'. -
Untuk Contains, gunakan
LIKE '%xxx%'. -
Untuk Equals, gunakan
LIKE 'xxx', setara denganstr = 'xxx'. -
Untuk mencocokkan underscore (_), lakukan escape:
LIKE '%seller/_id%' ESCAPE '/'. Underscore (_) adalah wildcard karakter tunggal dalam SQL. Tanpa escape,LIKE '%seller_id%'akan mencocokkanseller_id,seller#id,sellerxid, danseller1id, menghasilkan hasil yang salah.
-
-
Hindari fungsi ekspresi reguler (REGEXP)
Ekspresi reguler sangat mahal—seringkali 100× lebih lambat daripada operasi aritmetika dasar—dan dapat masuk ke loop tak hingga dalam kondisi tertentu, sehingga menghentikan job. Lihat Regex execution is too slow. Lebih disarankan menggunakan LIKE. Fungsi ekspresi reguler meliputi:
Bagaimana cara mengatasi efisiensi rendah dan backpressure saat membaca seluruh tabel?
Backpressure dapat berasal dari pemrosesan hilir yang lambat. Pertama, periksa adanya backpressure di hilir. Jika ada, atasi dengan salah satu cara berikut:
-
Tingkatkan konkurensi.
-
Aktifkan optimasi agregasi seperti minibatch (untuk node agregasi hilir).
Apa arti indikator warna pada Durasi Status untuk subtask vertex di ikhtisar job?
Di halaman Overview job, klik node operator dan pilih tab SubTasks untuk melihat lencana durasi berwarna di kolom Status Durations.
Status Durations menunjukkan waktu yang dihabiskan oleh subtask vertex di setiap fase. Arti warna adalah:
-
 : CREATED
: CREATED -
 : SCHEDULED
: SCHEDULED -
 : DEPLOYING
: DEPLOYING -
 : INITIALIZING
: INITIALIZING -
 : RUNNING
: RUNNING
Apa itu thread RMI TCP Connection, dan mengapa penggunaan CPU-nya jauh lebih tinggi dibanding thread lain?
Dalam daftar pemantauan thread yang diurutkan berdasarkan penggunaan CPU, thread RMI TCP Connection(62)-172.25.240.255 menunjukkan status RUNNABLE dengan penggunaan CPU 82,3%—jauh lebih tinggi dibanding thread kafkaRequestSource (penggunaan CPU 16,9%–26,4%, sebagian besar dalam status TIMED_WAITING).
Thread RMI TCP Connection termasuk dalam framework RMI (Remote Method Invocation) bawaan Java dan menangani pemanggilan metode remote. Penggunaan CPU berfluktuasi secara dinamis. Lonjakan jangka pendek tidak menunjukkan beban tinggi berkelanjutan. Amati penggunaan CPU dari waktu ke waktu. Analisis flame graph (di bawah) menunjukkan bahwa thread RMI hampir tidak mengonsumsi CPU.

Mengapa Low Watermark, Watermark, dan Task InputWatermark pada topologi yang sedang berjalan menunjukkan selisih waktu dari waktu saat ini?
-
Alasan 1: Watermark tabel sumber dideklarasikan dengan tipe
TIMESTAMP_LTZ (TIMESTAMP(p) WITH LOCAL TIME ZONE)menyebabkan selisih waktu.Contoh berikut membandingkan perilaku Watermark dengan tipe TIMESTAMP_LTZ versus TIMESTAMP.
-
Watermark tabel sumber menggunakan tipe TIMESTAMP_LTZ.
CREATE TEMPORARY TABLE s1 ( a INT, b INT, ts as CURRENT_TIMESTAMP,-- CURRENT_TIMESTAMP menghasilkan TIMESTAMP_LTZ. WATERMARK FOR ts AS ts - INTERVAL '5' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE t1 ( k INT, ts_ltz timestamp_ltz(3), cnt BIGINT ) WITH ('connector' = 'print'); -- Hasil output. INSERT INTO t1 SELECT b, window_start, COUNT(*) FROM TABLE( TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '5' SECOND)) GROUP BY b, window_start, window_end;CatatanSintaks Window lama menghasilkan hasil identik dengan
TVF Window (Table-Valued Function). Contoh sintaks lama:SELECT b, TUMBLE_END(ts, INTERVAL '5' SECOND), COUNT(*) FROM s1 GROUP BY TUMBLE(ts, INTERVAL '5' SECOND), b;Setelah menyebar dan menjalankan job di Konsol pengembangan Realtime Compute, amati selisih waktu 8 jam antara Watermark dan waktu saat ini (menggunakan UTC+8 sebagai acuan).
-
Watermark & Low Watermark
Di tab Watermarks UI pemantauan job Flink, SubTask 0 menunjukkan nilai Watermark
1706778525521, yang sesuai dengan Datetime of Watermark Timestamp02-01 09:08:45. Waktu mulai job adalah02-01 17:03:04—selisih sekitar 8 jam. Panel operator di sebelah kiri menunjukkan Low Watermark identik02-01 09:08:45. -
Task InputWatermark
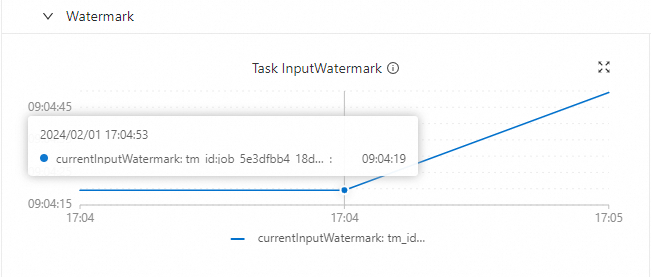
-
-
Watermark tabel sumber menggunakan tipe TIMESTAMP (TIMESTAMP(p) WITHOUT TIME ZONE).
CREATE TEMPORARY TABLE s1 ( a INT, b INT, -- Simulasikan TIMESTAMP tanpa zona waktu, dimulai dari 2024-01-31 01:00:00 dan bertambah per detik. ts as TIMESTAMPADD(SECOND, a, TIMESTAMP '2024-01-31 01:00:00'), WATERMARK FOR ts AS ts - INTERVAL '5' SECOND ) WITH ( 'connector'='datagen', 'rows-per-second'='1', 'fields.a.kind'='sequence','fields.a.start'='0','fields.a.end'='100000', 'fields.b.kind'='random','fields.b.min'='0','fields.b.max'='10' ); CREATE TEMPORARY TABLE t1 ( k INT, ts_ltz timestamp_ltz(3), cnt BIGINT ) WITH ('connector' = 'print'); -- Hasil output. INSERT INTO t1 SELECT b, window_start, COUNT(*) FROM TABLE( TUMBLE(TABLE s1, DESCRIPTOR(ts), INTERVAL '5' SECOND)) GROUP BY b, window_start, window_end;Setelah menyebar dan menjalankan di Konsol pengembangan Realtime Compute, Watermark sejajar dengan waktu saat ini (tepatnya, waktu data simulasi)—tidak ada selisih waktu.
-
Watermark & Low Watermark
Di detail task UI Web Flink, pilih operator (misalnya, GlobalWindowAggregate). Panel info operator di sebelah kiri menunjukkan Low Watermark (misalnya, 01-31 01:03:49). Beralih ke tab Watermarks di sebelah kanan untuk melihat nilai Watermark SubTask dan timestamp—kedua waktu tersebut cocok.
-
Task InputWatermark
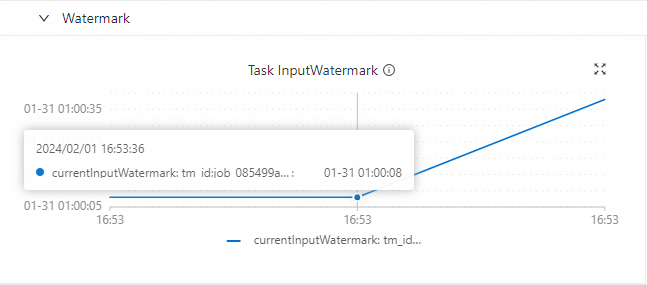
-
-
-
Alasan 2: Perbedaan zona waktu antara Konsol pengembangan Realtime Compute dan UI Apache Flink.
Konsol pengembangan Realtime Compute menampilkan waktu dalam UTC+0. UI Apache Flink menggunakan zona waktu lokal browser. Menggunakan UTC+8 (waktu Beijing) sebagai acuan, Konsol pengembangan Realtime Compute menunjukkan waktu 8 jam di belakang UI Apache Flink.
-
Konsol pengembangan Realtime Compute
Di topologi halaman Job O&M, waktu Watermark ditampilkan dalam UTC+0. Misalnya, ketika waktu event adalah waktu Beijing
2024/1/31 09:01:34 AM, konsol menunjukkan2024/1/31 01:01:34 AM.Metrik pemantauan terkait Watermark di konsol produk juga menggunakan UTC+0—8 jam di belakang waktu Beijing.
-
UI Apache Flink
Di UI Web Apache Flink, pilih node operator (misalnya,
GlobalWindowAggregate) dalam topologi job dan beralih ke tab Watermarks. Lihat nilai Watermark SubTask dan waktu event yang sesuai. Misalnya, Low Watermark1706662894000sesuai dengan Datetime of Watermark Timestamp2024/1/31 09:01:34 AM. Ini adalah waktu event, bukan waktu pemrosesan—sehingga perbedaan dari waktu sistem adalah hal yang normal.
-
Bagaimana cara mendiagnosis masalah backpressure pada job?
-
Di halaman Job O&M, klik nama job target untuk membuka tab Overview.
-
Periksa Busy dan BackPressure untuk menemukan backpressure.
Indikator Busy yang semakin merah berarti beban task lebih berat. Indikator BackPressure yang semakin gelap berarti dampak backpressure lebih kuat.
Misalnya, jika operator hulu Backpressured (max) 99%, operator tengah Busy (max) 100% (disorot merah), dan operator hilir Busy (max) hanya 7%, maka bottleneck berada di operator tengah—optimalkan operator tersebut.
-
Klik operator yang mengalami backpressure.
-
Di tab BackPressure, periksa status backpressure SubTask.
Jika Back Pressure Status berwarna hijau OK, dan tabel menunjukkan SubTasks 0–7 dengan Backpressured / Idle / Busy sebesar
0%, 0%, N/Aserta semua status OK, maka job tidak mengalami backpressure.
Bagaimana cara mendiagnosis masalah latensi job yang berlebihan?
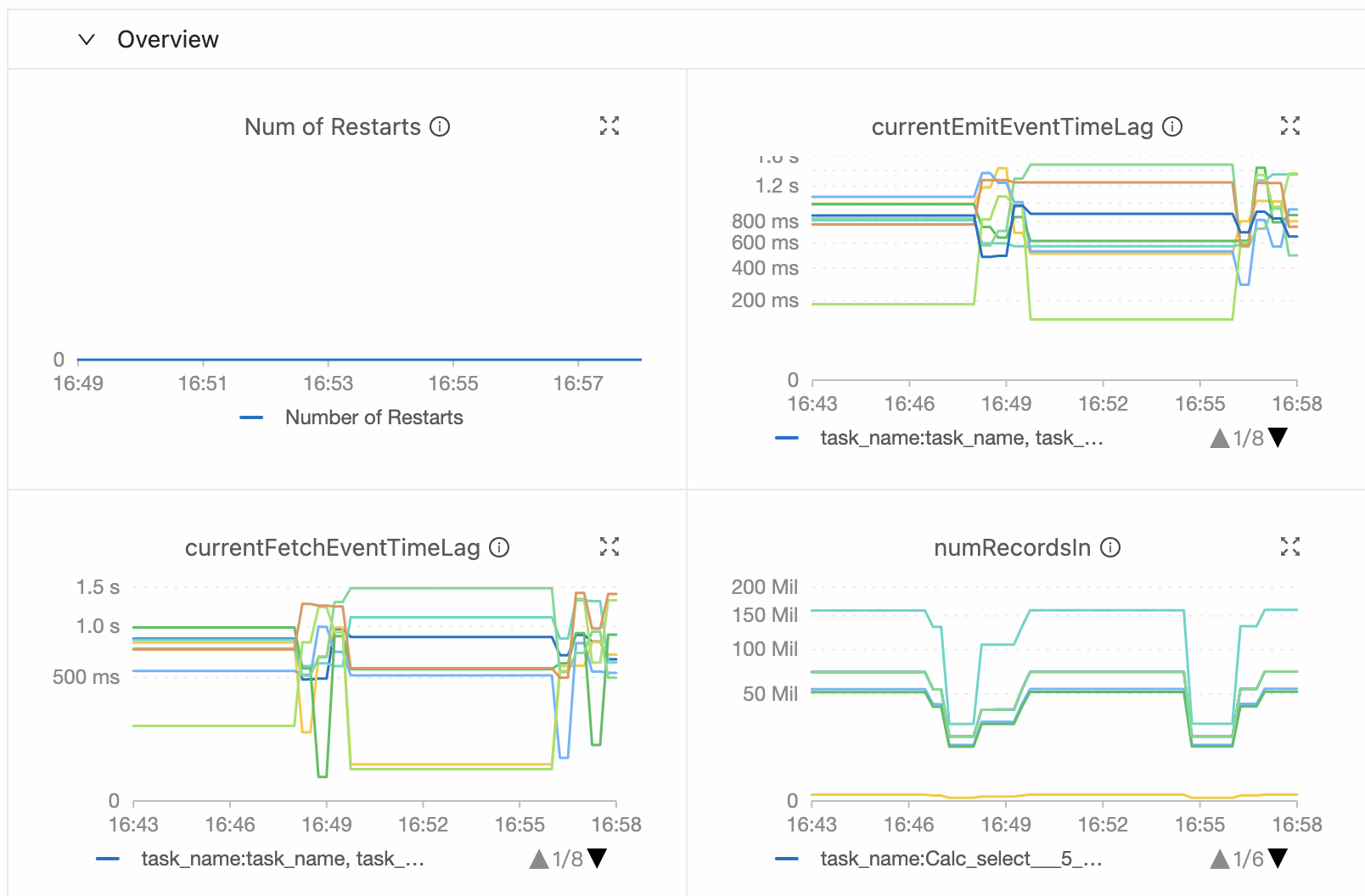
Di halaman Job O&M, periksa tab Monitoring and Alerts atau Data Curves untuk metrik currentEmitEventTimeLag dan currentFetchEventTimeLag:
-
Jika
currentEmitEventTimeLagtinggi, job mengalami keterlambatan dalam pengambilan atau pemrosesan data. Periksa performa operator. -
Jika
currentFetchEventTimeLagtinggi, keterlambatan berasal dari pengambilan data atau pemrosesan sistem hulu. Investigasi I/O jaringan dan sistem hulu.
Ketika faktor hulu menyebabkan latensi tinggi, kedua metrik tersebut meningkat secara bersamaan.
Bagaimana cara mengoptimalkan job Flink SQL ketika skew data menyebabkan backpressure?
Ketika backpressure berasal dari hotspot data (dikonfirmasi melalui analisis Subtask), gunakan optimasi berikut:
-
Aktifkan LocalGlobal (mengatasi masalah hotspot data umum)
Mekanisme LocalGlobal menggunakan LocalAgg untuk melakukan pre-agregasi data yang miring, sehingga mengurangi tekanan hotspot pada GlobalAgg dan meningkatkan performa keseluruhan.
LocalGlobal membagi satu agregasi menjadi dua tahap: Local dan Global—mirip dengan fase Combine dan Reduce dalam MapReduce. Pada tahap pertama, node hulu menyimpan dan mengagregasi data secara lokal (localAgg), lalu menghasilkan akumulator inkremental. Pada tahap kedua, akumulator tersebut digabungkan (Merge) untuk menghasilkan hasil akhir (GlobalAgg).
-
Skenario
Meningkatkan performa untuk agregasi standar (seperti SUM, COUNT, MAX, MIN, dan AVG) serta mengatasi masalah hotspot data dalam skenario tersebut.
-
Batasan
LocalGlobal diaktifkan secara default, tetapi batasan berikut berlaku:
-
MiniBatch harus diaktifkan.
-
AggregateFunction Anda harus mengimplementasikan Merge.
-
-
Memeriksa status
Periksa apakah topologi yang dihasilkan berisi node bernama GlobalGroupAggregate atau LocalGroupAggregate.
-
-
Aktifkan PartialFinal (mengatasi masalah hotspot COUNT DISTINCT)
Untuk mengatasi hotspot COUNT DISTINCT, biasanya Anda harus menulis ulang kueri secara manual menjadi agregasi dua tahap (menambahkan lapisan pengacakan berbasis modulo). Realtime Compute for Apache Flink kini menyediakan pengacakan COUNT DISTINCT otomatis melalui optimasi PartialFinal—tanpa perlu penulisan ulang manual.
LocalGlobal bekerja baik untuk agregasi standar tetapi memberikan manfaat kecil untuk COUNT DISTINCT. Selama agregasi lokal, tingkat deduplikasi kunci unik tetap rendah, sehingga hotspot tetap terjadi di node global.
-
Skenario
Gunakan ketika COUNT DISTINCT gagal memenuhi persyaratan performa node agregasi.
Penting-
Jangan gunakan optimasi PartialFinal pada Flink SQL yang mencakup UDAF.
-
Hindari PartialFinal ketika volume data kecil—hal ini menimbulkan pengacakan jaringan yang tidak perlu dan membuang sumber daya.
-
-
Cara mengaktifkan
Secara default, fitur ini dinonaktifkan. Untuk mengaktifkannya, pada tab Deployment Details job target, masukkan kode berikut di bagian Other Configurations pada area Runtime Parameter Settings.
table.optimizer.distinct-agg.split.enabled: true -
Verifikasi efektivitas
Periksa apakah topologi yang dihasilkan berubah dari satu tahap agregasi menjadi dua tahap.
-
Bagaimana cara mendiagnosis ketidakstabilan kecepatan konsumsi data masukan?
Kemungkinan penyebab dan solusi:
-
Pola produksi data hulu tidak sesuai dengan kecepatan pemrosesan saat ini.
Analisis pola generasi data hulu untuk menyelaraskan laju produksi dan pemrosesan.
-
Job mengalami backpressure.
Periksa adanya backpressure yang memengaruhi konsumsi hulu. Jika job Anda hanya menampilkan satu node, tambahkan
pipeline.operator-chaining: 'false', restart job untuk memisahkan rantai operator, lalu identifikasi node yang mengalami backpressure dan memengaruhi laju konsumsi. -
Laju I/O tidak normal.
Tinjau kurva laju input dan konsumsi data Flink pada waktu terkait untuk menentukan apakah I/O menjadi penyebabnya.
-
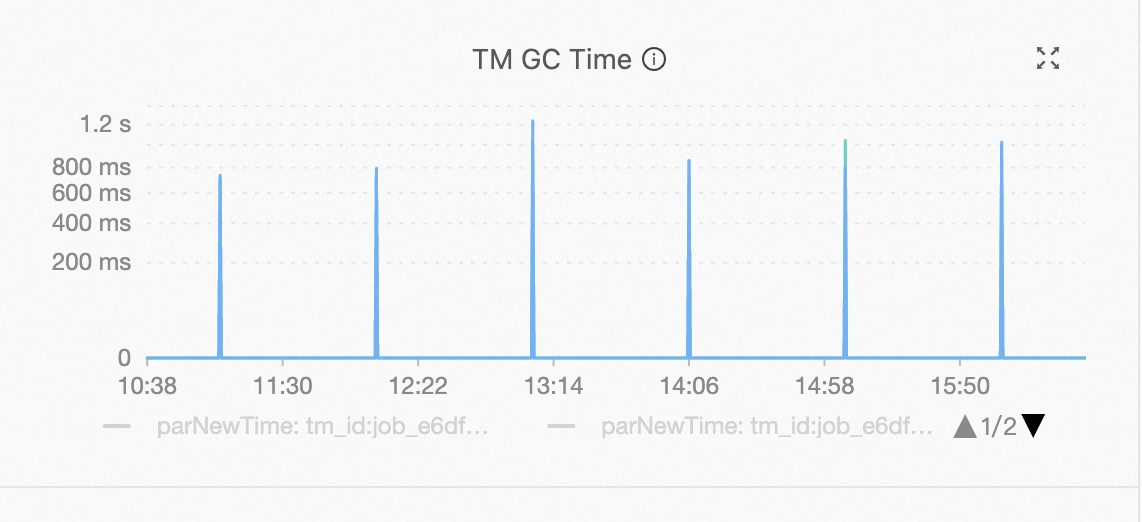
Laju konsumsi tidak normal.
Periksa apakah fluktuasi laju konsumsi sejalan dengan kejadian Garbage Collection (GC). Jika iya, periksa penggunaan memori node TM.