Realtime Compute for Apache Flink menyediakan kemampuan ingesti data real-time yang andal. Fitur seperti alih bencana otomatis antara sinkronisasi penuh dan inkremental, penemuan metadata otomatis, sinkronisasi evolusi skema otomatis, serta sinkronisasi seluruh database menyederhanakan pipeline ingesti real-time, sehingga membuat sinkronisasi data real-time menjadi lebih efisien dan mudah digunakan. Topik ini menjelaskan cara membangun pekerjaan ingesti data untuk memindahkan data dari MySQL ke Hologres secara cepat.
Informasi latar belakang
Asumsikan instans MySQL Anda berisi database bernama tpc_ds dengan 24 tabel bisnis yang memiliki skema berbeda. Database tersebut juga mencakup tiga database lain bernama user_db1, user_db2, dan user_db3. Karena sharding, masing-masing database ini berisi tiga tabel dengan skema identik, sehingga secara keseluruhan terdapat sembilan tabel bernama user01 hingga user09. Gambar berikut menunjukkan struktur database dan tabel di MySQL sebagaimana dilihat di konsol DMS Alibaba Cloud.
Untuk membangun pekerjaan ingesti data yang menyinkronkan semua tabel beserta datanya ke Hologres dan menggabungkan tabel-tabel user yang ter-shard menjadi satu tabel Hologres, ikuti langkah-langkah berikut:
Topik ini menggunakan fitur Flink CDC Data Ingestion Job Development (Public Preview) untuk melakukan sinkronisasi seluruh database dan menggabungkan tabel-tabel yang ter-shard menjadi satu tabel target. Fitur ini juga mendukung sinkronisasi penuh dan inkremental sekali klik serta sinkronisasi evolusi skema real-time.
Prasyarat
Jika Anda mengakses layanan menggunakan pengguna Resource Access Management (RAM) atau Peran RAM, pastikan Anda memiliki izin yang diperlukan untuk konsol Flink. Untuk informasi lebih lanjut, lihat Manajemen Izin.
Buat ruang kerja Flink. Untuk informasi lebih lanjut, lihat Aktifkan Realtime Compute for Apache Flink.
Sumber Data dan Sink
Buat instans ApsaraDB RDS for MySQL. Untuk informasi lebih lanjut, lihat (Usang, dialihkan ke “Langkah 1”) Buat instans ApsaraDB RDS for MySQL dengan cepat.
Anda telah membuat instans Hologres. Untuk informasi lebih lanjut, lihat Beli Instans Hologres.
CatatanInstans ApsaraDB RDS for MySQL dan Hologres harus berada di Wilayah dan VPC yang sama dengan ruang kerja Flink Anda. Jika tidak, Anda harus mengonfigurasi konektivitas jaringan. Untuk informasi lebih lanjut, lihat Bagaimana cara mengakses layanan lain lintas VPC? dan Bagaimana cara mengakses Internet?.
Siapkan data uji dan konfigurasikan daftar putih IP. Untuk informasi lebih lanjut, lihat Siapkan data uji MySQL dan database Hologres dan Konfigurasikan daftar putih IP.
Siapkan data uji MySQL dan database Hologres
Klik tpc_ds.sql, user_db1.sql, user_db2.sql, dan user_db3.sql untuk mengunduh data uji ke mesin lokal Anda.
Di konsol Data Management (DMS), siapkan data uji untuk instans ApsaraDB RDS for MySQL Anda.
Masuk ke instans ApsaraDB RDS for MySQL Anda menggunakan DMS.
Untuk informasi lebih lanjut, lihat (Usang, dialihkan ke “Langkah 2”) Masuk ke ApsaraDB RDS for MySQL menggunakan DMS.
Di jendela SQLConsole, masukkan perintah berikut lalu klik Execute.
Buat empat database: tpc_ds, user_db1, user_db2, dan user_db3.
CREATE DATABASE tpc_ds; CREATE DATABASE user_db1; CREATE DATABASE user_db2; CREATE DATABASE user_db3;Pada bilah menu pintasan atas, klik Data Import.
Pada tab Batch Data Import, pilih database target, unggah file SQL yang sesuai, klik Submit Application, lalu klik Execute Change. Pada kotak dialog yang muncul, klik Confirm Execution.
Ulangi proses ini untuk database tpc_ds, user_db1, user_db2, dan user_db3 guna mengimpor file data masing-masing.

Di konsol Hologres, buat database bernama my_user untuk menyimpan data tabel user yang digabung.
Untuk informasi lebih lanjut, lihat Buat database.
Konfigurasikan daftar putih IP
Agar Flink dapat mengakses instans ApsaraDB RDS for MySQL dan Hologres Anda, tambahkan Blok CIDR ruang kerja Flink ke daftar putih IP kedua instans tersebut.
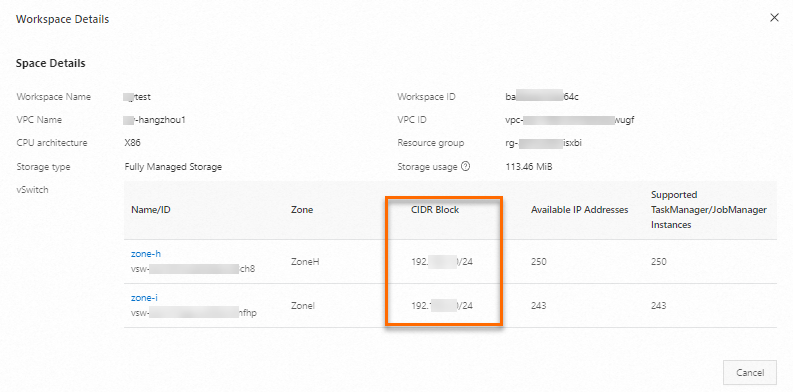
Dapatkan Blok CIDR VPC ruang kerja Flink Anda.
Masuk ke Konsol Realtime Compute.
Di daftar Workspace, temukan ruang kerja target Anda. Di kolom Actions, pilih .
Di kotak dialog Workspace Details, lihat VPC CIDR block dari virtual switch yang digunakan Flink.
Tambahkan Blok CIDR Flink ke daftar putih IP instans ApsaraDB RDS for MySQL Anda.
Untuk informasi lebih lanjut, lihat Konfigurasikan daftar putih IP.

Tambahkan Blok CIDR Flink ke daftar putih IP instans Hologres Anda.
Saat mengonfigurasi koneksi data di HoloWeb, atur Login Method ke Passwordless Login for Current User sebelum mengonfigurasi daftar putih IP untuk koneksi tersebut. Untuk informasi lebih lanjut, lihat Daftar Putih IP.

Langkah 1: Kembangkan pekerjaan sinkronisasi data
Masuk ke konsol pengembangan Flink dan buat pekerjaan baru.
Pada halaman , klik New.
Klik Blank Data Ingestion Draft.
Flink menyediakan banyak templat kode. Setiap templat mencakup studi kasus, contoh kode, dan panduan penggunaan. Anda dapat mengklik templat untuk mempelajari fitur dan sintaksis Flink serta menerapkan logika bisnis Anda.
Klik Next.
Di kotak dialog New Data Ingestion Job Draft, tentukan konfigurasi.
Job Parameter
Description
Example
File Name
Nama pekerjaan.
CatatanNama pekerjaan harus unik dalam proyek saat ini.
flink-test
Storage Location
Folder tempat file kode pekerjaan disimpan.
Anda juga dapat mengklik ikon
 di sebelah kanan folder yang ada untuk membuat subfolder.
di sebelah kanan folder yang ada untuk membuat subfolder.Job Draft
Engine Version
Versi engine Flink yang digunakan pekerjaan. Untuk detail tentang nomor versi, pemetaan versi, dan tahapan siklus hidup, lihat Ikhtisar Versi Engine.
vvr-11.1-jdk11-flink-1.20
Klik OK.
Salin kode pekerjaan berikut ke editor pekerjaan.
Pekerjaan ini menyinkronkan semua tabel dari database tpc_ds ke Hologres dan menggabungkan tabel-tabel user yang ter-shard menjadi satu tabel Hologres. Contoh kode:
source: type: mysql name: MySQL Source hostname: localhost port: 3306 username: username password: password tables: tpc_ds.\.*,user_db[0-9]+.user[0-9]+ server-id: 8601-8604 # (Optional) Synchronize table and column comments. include-comments.enabled: true # (Optional) Prioritize unbounded chunk distribution to avoid possible TaskManager OutOfMemory errors. scan.incremental.snapshot.unbounded-chunk-first.enabled: true # (Optional) Enable parsing filters to speed up reading. scan.only.deserialize.captured.tables.changelog.enabled: true sink: type: hologres name: Hologres Sink endpoint: ****.hologres.aliyuncs.com:80 dbname: cdcyaml_test username: ${secret_values.holo-username} password: ${secret_values.holo-password} sink.type-normalize-strategy: BROADEN route: # Merge sharded user tables into the my_user.users table. - source-table: user_db[0-9]+.user[0-9]+ sink-table: my_user.usersCatatanSemua tabel di database tpc_ds MySQL dipetakan langsung ke tabel dengan nama identik di database downstream. Tidak diperlukan pemetaan tambahan di bagian route. Untuk menyinkronkannya ke database berbeda, seperti ods_tps_ds, konfigurasikan bagian route sebagai berikut:
route: # Merge sharded user tables into the my_user.users table. - source-table: user_db[0-9]+.user[0-9]+ sink-table: my_user.users # Sync all tables from the tpc_ds database to the ods_tps_ds database. - source-table: tpc_ds.\.* sink-table: ods_tps_ds.<> replace-symbol: <>
Langkah 2: Mulai pekerjaan
Pada halaman , klik Deploy. Pada kotak dialog yang muncul, klik Confirm.

Pada halaman , klik Actions di samping pekerjaan target Anda, lalu klik Start. Untuk informasi lebih lanjut, lihat Mulai pekerjaan.
Klik Start.
Setelah pekerjaan dimulai, Anda dapat memantau status dan informasi waktu prosesnya di halaman Job Operations.

Langkah 3: Pantau hasil sinkronisasi data penuh
-
Masuk ke Konsol Manajemen Hologres.
Di tab Metadata Management, lihat 24 tabel beserta datanya di database tpc_ds.

Di tab Metadata Management, lihat skema tabel users di database my_user.
Skema dan data yang tersinkronisasi ditampilkan pada gambar berikut.
Skema

Skema tabel users mencakup dua kolom tambahan: _db_name dan _table_name. Kolom-kolom ini mencatat nama database dan tabel sumber serta membentuk bagian dari kunci primer komposit untuk memastikan keunikan setelah tabel-tabel yang ter-shard digabung.
Data tabel
Di pojok kanan atas halaman detail tabel users, klik Query Table, masukkan perintah berikut, lalu klik Run.
select * from users order by _db_name,_table_name,id;Hasil kueri ditampilkan pada gambar berikut.

Langkah 4: Pantau hasil sinkronisasi inkremental
Setelah sinkronisasi data penuh selesai, pekerjaan secara otomatis beralih ke sinkronisasi inkremental tanpa memerlukan intervensi manual. Anda dapat memeriksa metrik currentEmitEventTimeLag di tab Monitoring and Alerts untuk menentukan fase sinkronisasi saat ini.
Masuk ke Konsol Realtime Compute.
Temukan ruang kerja target Anda dan klik Console di kolom Actions.
Pada halaman , klik nama pekerjaan target Anda.
Klik tab Monitoring and Alerts (atau tab Data Curve).
Periksa kurva currentEmitEventTimeLag untuk mengidentifikasi fase sinkronisasi.

Nilai 0 menunjukkan bahwa sinkronisasi penuh masih berlangsung.
Nilai lebih dari 0 menunjukkan bahwa sinkronisasi inkremental telah dimulai.
Verifikasi sinkronisasi real-time perubahan data dan skema.
Sumber MySQL CDC mendukung sinkronisasi real-time perubahan data dan skema selama sinkronisasi inkremental. Setelah pekerjaan memasuki fase sinkronisasi inkremental, Anda dapat memodifikasi skema dan data tabel user yang ter-shard di MySQL untuk memverifikasi kemampuan ini.
Masuk ke instans ApsaraDB RDS for MySQL Anda menggunakan DMS.
Untuk informasi lebih lanjut, lihat (Usang, dialihkan ke “Langkah 2”) Masuk ke ApsaraDB RDS for MySQL menggunakan DMS.
Di database user_db2, jalankan perintah berikut untuk memodifikasi skema tabel user02 serta menyisipkan dan memperbarui data.
USE DATABASE `user_db2`; ALTER TABLE `user02` ADD COLUMN `age` INT; -- Add the age column. INSERT INTO `user02` (id, name, age) VALUES (27, 'Tony', 30); -- Insert data with age. UPDATE `user05` SET name='JARK' WHERE id=15; -- Update another table and change the name to uppercase.Di konsol Hologres, periksa perubahan skema dan data tabel users.
Di pojok kanan atas halaman detail tabel users, klik Query Table, masukkan perintah berikut, lalu klik Run.
select * from users order by _db_name,_table_name,id;Hasil kueri ditampilkan pada gambar berikut.
 Meskipun skema tabel-tabel yang ter-shard berbeda, perubahan skema dan data yang dilakukan pada tabel user02 disinkronkan secara real-time ke tabel users downstream. Di Hologres, tabel users kini mencakup kolom age baru, catatan Tony yang disisipkan, dan catatan JARK yang diperbarui.
Meskipun skema tabel-tabel yang ter-shard berbeda, perubahan skema dan data yang dilakukan pada tabel user02 disinkronkan secara real-time ke tabel users downstream. Di Hologres, tabel users kini mencakup kolom age baru, catatan Tony yang disisipkan, dan catatan JARK yang diperbarui.
(Opsional) Langkah 5: Konfigurasikan resource pekerjaan
Volume data bervariasi. Untuk mengoptimalkan kinerja pekerjaan, Anda dapat menyesuaikan konkurensi dan resource TaskManager melalui konfigurasi resource, yang memungkinkan penyetelan konkurensi pekerjaan serta alokasi memori atau CU.
Pada halaman , klik nama pekerjaan target Anda.
Di tab Deployment Details, klik Resource Configuration, lalu klik Edit di pojok kanan atas.
Atur secara manual parameter resource seperti memori TaskManager dan konkurensi.
Di pojok kanan atas bagian Resource Configuration, klik Save.
Restart pekerjaan.
Perubahan konfigurasi resource hanya berlaku setelah Anda me-restart pekerjaan.
Referensi
Untuk informasi lebih lanjut tentang sintaksis modul ingesti data, lihat Referensi Pengembangan Pekerjaan Ingesti Data Flink CDC.
Jika terjadi pengecualian saat menjalankan pekerjaan ingesti data, lihat Masalah Umum dan Solusi untuk Pekerjaan Ingesti Data.