Topik ini menjelaskan cara menggunakan fitur dasar Apache Paimon di Konsol Pengembangan Realtime Compute for Apache Flink. Fitur dasar mencakup pembuatan dan penghapusan katalog Apache Paimon, pembuatan dan penghapusan tabel Apache Paimon, penulisan data ke tabel Apache Paimon, serta pembaruan dan konsumsi data dalam tabel Apache Paimon.
Prasyarat
Jika Anda ingin menggunakan pengguna RAM atau Peran RAM untuk mengakses Konsol Pengembangan Realtime Compute for Apache Flink, pastikan bahwa pengguna RAM atau Peran RAM memiliki izin yang diperlukan. Untuk informasi lebih lanjut, lihat Manajemen Izin.
Sebuah workspace telah dibuat. Untuk informasi lebih lanjut, lihat Aktifkan Realtime Compute for Apache Flink.
Object Storage Service (OSS) telah diaktifkan dan sebuah Bucket OSS dengan kelas penyimpanan Standar telah dibuat. Untuk informasi lebih lanjut, lihat Mulai Menggunakan Konsol OSS. OSS digunakan untuk menyimpan file terkait tabel Apache Paimon, seperti file data dan file metadata.
Hanya Realtime Compute for Apache Flink yang menggunakan Ververica Runtime (VVR) 8.0.5 atau versi lebih baru yang mendukung tabel Apache Paimon.
Langkah 1: Buat katalog Apache Paimon
Buka tab Scripts.
Masuk ke Konsol Realtime Compute for Apache Flink.
Temukan workspace yang ingin Anda kelola dan klik Console di kolom Actions.
Di panel navigasi sebelah kiri, klik . Di tab Scripts, buat sebuah script.
Di editor skrip, masukkan kode berikut untuk membuat katalog Apache Paimon:
-- my-Catalog adalah nama katalog kustom. CREATE Catalog `my-catalog` WITH ( 'type' = 'paimon', 'metastore' = 'filesystem', 'warehouse' = '<warehouse>', 'fs.oss.endpoint' = '<fs.oss.endpoint>', 'fs.oss.accessKeyId' = '<fs.oss.accessKeyId>', 'fs.oss.accessKeySecret' = '<fs.oss.accessKeySecret>' );Tabel berikut menjelaskan parameter-parameter tersebut.
Parameter
Deskripsi
Diperlukan
Catatan
type
Jenis katalog.
Ya
Atur nilainya menjadi Paimon.
metastore
Jenis penyimpanan metadata.
Ya
Dalam contoh ini, parameter ini disetel ke filesystem. Untuk informasi lebih lanjut tentang jenis lainnya, lihat Kelola katalog Apache Paimon.
warehouse
Direktori gudang data yang ditentukan di OSS.
Ya
Formatnya adalah oss://<bucket>/<object>. Parameter dalam direktori:
bucket: menunjukkan nama Bucket OSS yang Anda buat.
object: menunjukkan jalur tempat data Anda disimpan.
Anda dapat melihat nama bucket dan nama objek di konsol OSS.
fs.oss.endpoint
Titik akhir OSS.
Tidak
Parameter ini diperlukan jika Bucket OSS yang ditentukan oleh parameter warehouse tidak berada di wilayah yang sama dengan workspace Realtime Compute for Apache Flink atau jika Bucket OSS dari akun Alibaba Cloud lain digunakan.
Untuk informasi lebih lanjut, lihat Wilayah dan titik akhir.
CatatanUntuk menyimpan tabel Apache Paimon di OSS-HDFS, Anda harus mengonfigurasi parameter fs.oss.endpoint, fs.oss.accessKeyId, dan fs.oss.accessKeySecret. Nilai parameter fs.oss.endpoint berformat cn-<region>.oss-dls.aliyuncs.com, seperti cn-hangzhou.oss-dls.aliyuncs.com.
fs.oss.accessKeyId
ID AccessKey akun Alibaba Cloud atau pengguna RAM yang memiliki izin baca dan tulis pada OSS.
Tidak
Parameter ini diperlukan jika Bucket OSS yang ditentukan oleh parameter warehouse tidak berada di wilayah yang sama dengan workspace Realtime Compute for Apache Flink atau jika Bucket OSS dari akun Alibaba Cloud lain digunakan. Untuk informasi lebih lanjut tentang cara mendapatkan pasangan AccessKey, lihat Buat pasangan AccessKey.
fs.oss.accessKeySecret
Rahasia AccessKey akun Alibaba Cloud atau pengguna RAM yang memiliki izin baca dan tulis pada OSS.
Tidak
Pilih kode untuk membuat katalog Apache Paimon, lalu klik Run di sisi kiri editor skrip.
Jika pesan
Pernyataan berikut telah berhasil dieksekusi!muncul, katalog telah berhasil dibuat.
Langkah 2: Buat tabel Apache Paimon
Di tab Scripts, masukkan kode berikut di editor skrip untuk membuat database Apache Paimon bernama my_db dan tabel Apache Paimon bernama my_tbl:
CREATE DATABASE `my-catalog`.`my_db`; CREATE TABLE `my-catalog`.`my_db`.`my_tbl` ( dt STRING, id BIGINT, content STRING, PRIMARY KEY (dt, id) NOT ENFORCED ) PARTITIONED BY (dt) WITH ( 'changelog-producer' = 'lookup' );CatatanDalam contoh ini, parameter
changelog-producerdisetel kelookupdalam klausa WITH untuk menggunakan kebijakan lookup dalam menghasilkan log perubahan. Dengan cara ini, data dapat dikonsumsi dari tabel Apache Paimon dalam mode streaming. Untuk informasi lebih lanjut tentang pembuatan log perubahan, lihat Mekanisme Pembuatan Data Perubahan.Pilih kode untuk membuat database Apache Paimon dan tabel Apache Paimon, lalu klik Run di sisi kiri editor skrip.
Jika pesan
Pernyataan berikut telah berhasil dieksekusi!muncul, database Apache Paimon bernama my_db dan tabel Apache Paimon bernama my_tbl telah berhasil dibuat.
Langkah 3: Tulis data ke tabel Apache Paimon
Di tab Drafts halaman , klik New. Di tab SQL Scripts kotak dialog New Draft, klik Blank Stream Draft. Untuk informasi lebih lanjut tentang cara mengembangkan draft SQL, lihat Kembangkan Draft SQL. Salin pernyataan INSERT berikut ke editor SQL:
-- Tabel hasil Apache Paimon hanya melakukan commit data setelah setiap checkpointing selesai. -- Dalam contoh ini, interval checkpointing dikurangi menjadi 10 detik untuk membantu Anda mendapatkan hasil dengan cepat. -- Di lingkungan produksi, interval checkpointing dan jeda minimal antara percobaan checkpointing bervariasi berdasarkan persyaratan bisnis Anda untuk latensi. Biasanya, mereka diatur antara 1 hingga 10 menit. SET 'execution.checkpointing.interval'='10s'; INSERT INTO `my-catalog`.`my_db`.`my_tbl` VALUES ('20240108',1,'apple'), ('20240108',2,'banana'), ('20240109',1,'cat'), ('20240109',2,'dog');Di pojok kanan atas halaman editor SQL, klik Deploy. Pada kotak dialog Deploy draft, konfigurasikan parameter yang diperlukan, lalu klik Confirm.
Di halaman , temukan deployment yang diinginkan, dan klik Start di kolom Actions. Di panel Start Job, pilih Initial Mode, lalu klik Start.
Jika status deployment berubah menjadi FINISHED, data telah berhasil ditulis ke deployment.
Langkah 4: Konsumsi data dari tabel Apache Paimon dalam mode streaming
Buat draft streaming kosong, dan salin kode berikut ke editor SQL. Kode ini menggunakan Print connector untuk mengekspor semua data dari tabel my_tbl ke log.
CREATE TEMPORARY TABLE Print ( dt STRING, id BIGINT, content STRING ) WITH ( 'connector' = 'print' ); INSERT INTO Print SELECT * FROM `my-catalog`.`my_db`.`my_tbl`;Di pojok kanan atas halaman editor SQL, klik Deploy. Di kotak dialog Deploy draft, konfigurasikan parameter dan klik Confirm.
Di halaman , temukan deployment yang diinginkan, dan klik Start di kolom Actions. Di panel Start Job, pilih Initial Mode, lalu klik Start.
Di halaman Deployments, lihat hasil komputasi.
Di panel navigasi sebelah kiri, klik . Di halaman Deployments, klik nama deployment yang ingin Anda kelola.
Di tab Logs, yang terdapat di tab Logs, klik nilai pada kolom Path, ID di tab Running Task Managers.
Klik tab Stdout untuk melihat data Apache Paimon yang dikonsumsi.
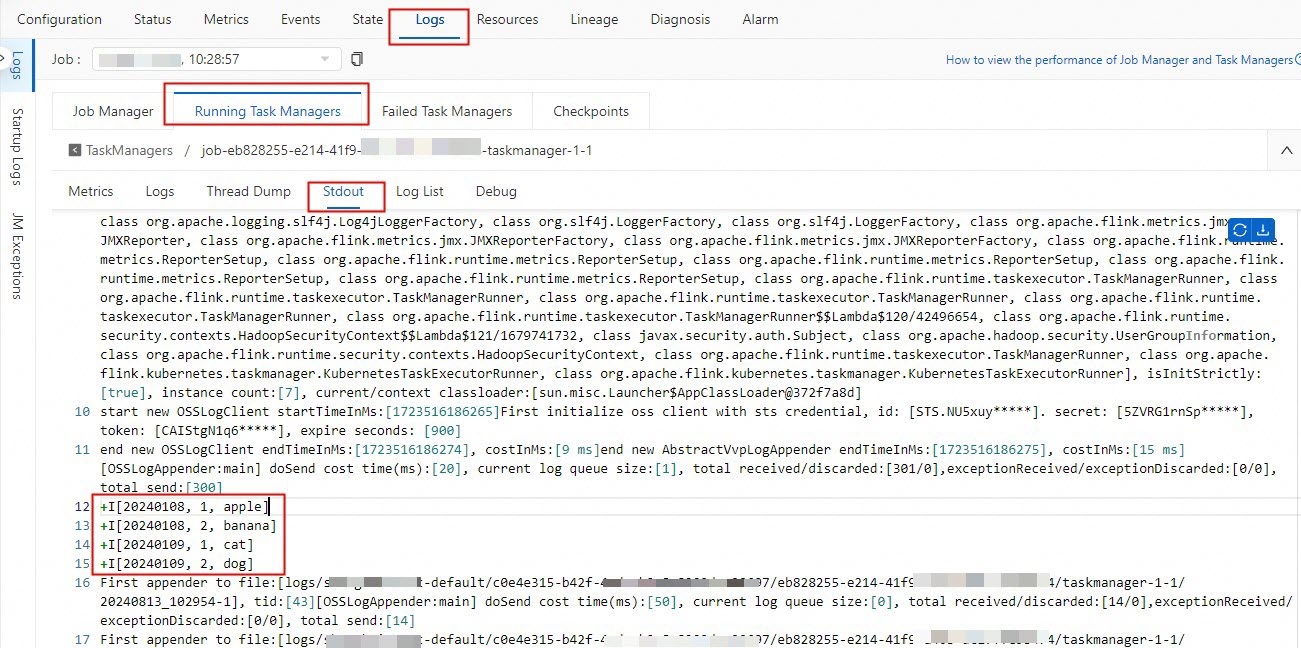
Langkah 5: Perbarui data dalam tabel Apache Paimon
Buat draft streaming kosong, dan salin kode berikut ke editor SQL:
SET 'execution.checkpointing.interval' = '10s'; INSERT INTO `my-catalog`.`my_db`.`my_tbl` VALUES ('20240108', 1, 'hello'), ('20240109', 2, 'world');Di pojok kanan atas halaman editor SQL, klik Deploy. Di kotak dialog Deploy draft, konfigurasikan parameter dan klik Confirm.
Di halaman , temukan deployment yang diinginkan, dan klik Start di kolom Actions. Di panel Start Job, pilih Initial Mode, lalu klik Start.
Jika status deployment berubah menjadi FINISHED, data telah berhasil ditulis ke tabel Apache Paimon.
Buka tab Stdout dari halaman Deployments seperti yang dijelaskan di Langkah 4, dan lihat data yang diperbarui dalam tabel Apache Paimon.
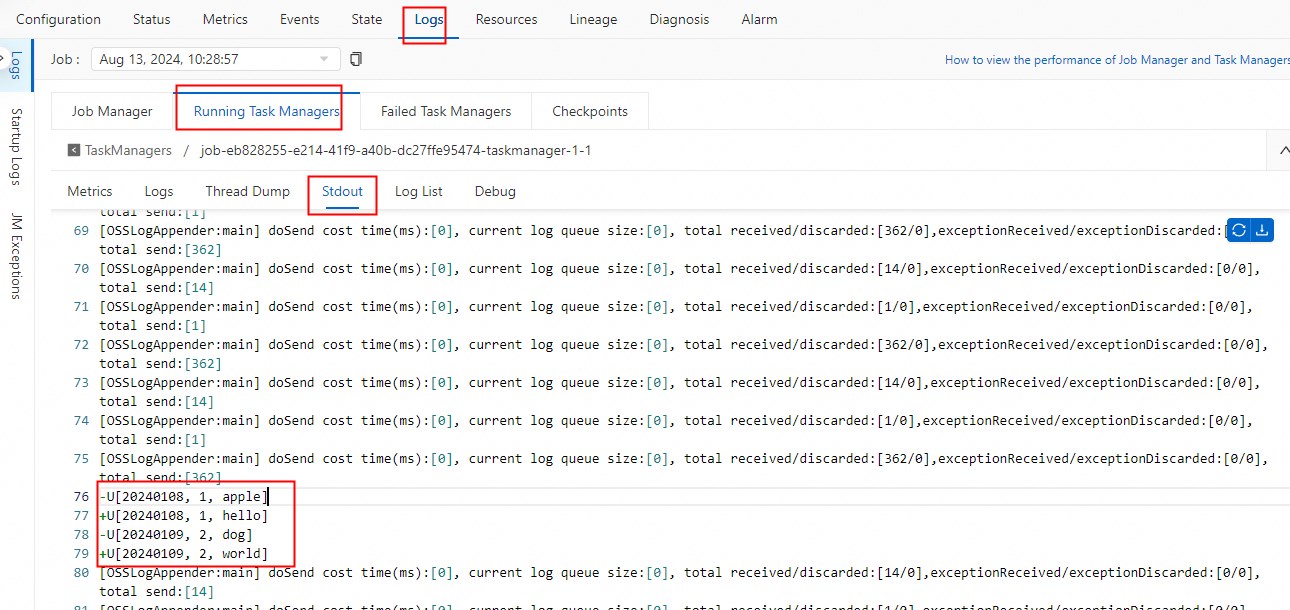
(Opsional) Langkah 6: Batalkan deployment di mana data dikonsumsi dalam mode streaming dan bersihkan sumber daya
Setelah pengujian selesai, Anda dapat melakukan langkah-langkah berikut untuk membatalkan deployment di mana data dikonsumsi dalam mode streaming dan membersihkan sumber daya:
Di halaman , temukan deployment yang ingin Anda batalkan dan klik Cancel di kolom Actions.
Di halaman Editor SQL, klik tab Scripts. Di editor SQL pada tab Scripts, masukkan kode berikut untuk menghapus file data Apache Paimon dan katalog Apache Paimon:
DROP DATABASE 'my-catalog'.'my_db' CASCADE; -- Hapus semua file data dari database Apache Paimon yang disimpan di OSS. DROP CATALOG 'my-catalog'; -- Hapus katalog Apache Paimon dari metadata di konsol pengembangan Realtime Compute for Apache Flink. File data yang disimpan di OSS tidak dihapus.Jika pesan
The following statement has been executed successfully!dikembalikan, file data Apache Paimon dan katalog Apache Paimon akan dihapus.
Referensi
Untuk informasi lebih lanjut tentang cara menulis data ke atau mengonsumsi data dari tabel Apache Paimon, lihat Tulis Data ke atau Konsumsi Data dari Tabel Apache Paimon.
Untuk informasi lebih lanjut tentang cara memodifikasi skema tabel Apache Paimon, seperti menambahkan kolom dan mengubah tipe data kolom, serta cara sementara memodifikasi parameter tabel Apache Paimon, lihat Modifikasi Skema Tabel Apache Paimon.
Untuk informasi lebih lanjut tentang cara mengoptimalkan tabel kunci utama Apache Paimon dan tabel Append Scalable dalam berbagai skenario, lihat Optimalkan Performa Tabel Apache Paimon.
Untuk informasi lebih lanjut tentang cara menyelesaikan masalah terkait Apache Paimon, lihat FAQ tentang Konektor.