Anda mungkin perlu me-restart kluster atau nodenya untuk menerapkan perubahan konfigurasi atau menangani pengecualian kluster. Untuk melakukan operasi ini secara aman dan efisien, penting memahami skenario serta risiko yang terkait dengan berbagai metode restart.
Persiapan
Untuk memastikan restart berjalan lancar, lakukan pemeriksaan kesehatan dan persiapan berikut sebelum memulai.
Periksa status kesehatan kluster
Terhubung ke kluster melalui Kibana dan jalankan perintahGET _cluster/health. Pastikan nilai bidangstatusadalahgreen.Pengecualian: Anda hanya dapat melakukan restart paksa jika status kluster adalah
yellowataured.Pastikan redundansi data
Jalankan perintahGET _cat/indices?vuntuk memeriksa nilai bidangrep(jumlah replika) untuk semua indeks kritis.Pastikan jumlah replika minimal
1. Indeks tanpa replika akan menjadi tidak dapat diakses selama proses restart.Untuk instans multi-zona, pastikan jumlah replika untuk setiap indeks kurang dari jumlah zona.
Periksa dan tangani indeks yang ditutup
Jalankan perintahGET _cat/indices?vuntuk memeriksa apakah ada indeks yang memilikistatusclose.Alasan: Indeks yang ditutup menyebabkan pemeriksaan kesehatan kluster gagal dan mencegah alokasi shard. Hal ini menghambat proses restart.
Tindakan: Jika terdapat indeks yang ditutup, jalankan perintah
POST /<index_name>/_openuntuk membukanya.
Nilai beban kluster
Di halaman Pemantauan Kluster instans, periksa metrik inti berikut. Pastikan Penggunaan sumber daya berada dalam batas yang ditentukan untuk menyediakan sumber daya yang cukup bagi migrasi shard selama restart.Penggunaan CPU node: Harus di bawah 80%.
Penggunaan HeapMemory node: Harus sekitar 50%.
load_1m node: Harus di bawah jumlah core CPU pada node data.
Lakukan restart
Setelah menyelesaikan pemeriksaan kesehatan, ikuti langkah-langkah berikut untuk me-restart instans.
Masuk ke Konsol Alibaba Cloud Elasticsearch. Di panel navigasi sebelah kiri, klik Elasticsearch Clusters.
Di bilah menu atas, pilih Wilayah tempat instans target berada. Klik ID instans target tersebut. Di halaman Basic Information, klik Restart di pojok kanan atas.
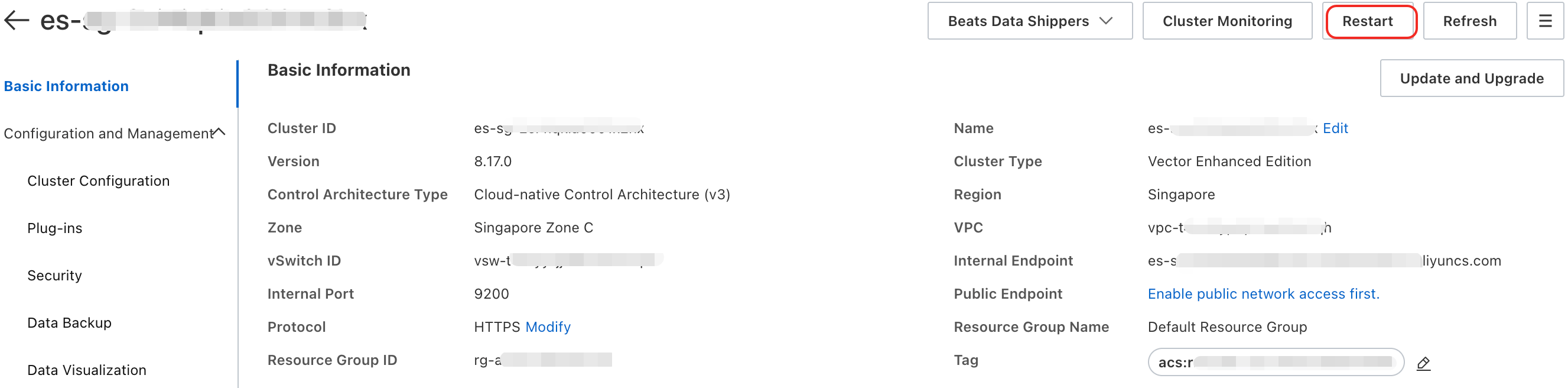
Pada kotak dialog Restart yang muncul, konfigurasikan parameter berikut sesuai kebutuhan.
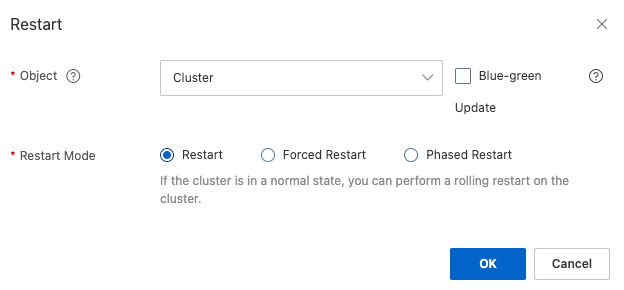
Object
Cluster: Me-restart semua node dalam instans. Opsi ini cocok untuk perubahan tingkat kluster.
Node Restart: Me-restart satu atau beberapa node tertentu yang Anda pilih. Opsi ini cocok untuk menangani masalah pada node individual.
Node Role (Hanya untuk kluster manajemen dasar v2): Me-restart node dengan peran tertentu yang Anda pilih, seperti node data atau node Kibana.
Blue-green Update dan Restart Mode
Operasi restart dapat memengaruhi stabilitas dan ketersediaan kluster Anda. Sebelum me-restart kluster, pilih metode restart yang sesuai dengan skenario spesifik, status kluster, dan toleransi risiko Anda.
Metode Restart
Status Kluster yang Diperlukan
Skenario
Dampak Layanan
Versi Instans yang Berlaku
Perubahan blue-green
Normal (green)
Operasi ini menambahkan node baru ke kluster, memigrasikan data dari node asli ke node baru, lalu menghapus node asli.
Metode ini cocok untuk skenario di mana satu node dalam kluster mengalami kinerja buruk, seperti penggunaan CPU yang terus-menerus tinggi, dan Anda memiliki persyaratan tinggi terhadap ketersediaan kluster tetapi tidak sensitif terhadap durasi perubahan.
PentingPerubahan blue-green tidak dapat digunakan bersamaan dengan restart paksa.
Alamat IP node berubah. Kinerja kluster mungkin mengalami fluktuasi singkat.
Tidak didukung untuk spesifikasi 1-core 2 GB
Restart (Standard)
Normal (green)
Pemeliharaan terencana dan konfigurasi kluster rutin.
Alamat IP node tidak berubah. Proses restart memakan waktu lama. Jika terdapat shard replika, layanan tetap tersedia tetapi mungkin mengalami fluktuasi singkat.
Semua versi
Restart bertahap
Normal (green)
Gunakan metode ini di lingkungan produksi untuk memverifikasi efek restart secara bertahap dan mengurangi risiko keseluruhan.
Jika Anda memilih opsi ini, Anda harus terlebih dahulu memilih node untuk restart bertahap. Setelah batch pertama node direstart dan kluster stabil, picu secara manual perubahan berikutnya untuk me-restart node yang tersisa.
Alamat IP node tidak berubah. Beberapa node direstart terlebih dahulu untuk Pengamatan, lalu node yang tersisa direstart.
Hanya untuk kluster cloud-native manajemen baru (v3)
Restart paksa
Tidak normal (yellow/red)
Ketika instans berada dalam kondisi tidak sehat (yellow atau red), operasi restart lainnya dinonaktifkan. Anda harus melakukan restart paksa.
PentingKetika penggunaan disk melebihi ambang batas
cluster.routing.allocation.disk.watermark.low, kluster mungkin memasuki kondisi tidak sehat (yellow atau red). Selama periode ini, hindari operasi berikut:Scale-out node
Scale-out disk
Restart (standar atau paksa)
Perubahan kata sandi
Perubahan konfigurasi lainnya
Lakukan operasi-operasi tersebut hanya setelah instans kembali ke kondisi sehat (green).
Alamat IP node tidak berubah.
Meningkatkan konkurensi secara signifikan dapat mempercepat restart paksa, tetapi juga memberikan dampak yang lebih besar:
Risiko konkurensi tinggi: Jika diatur ke 100%, semua node direstart secara bersamaan. Hal ini menyebabkan gangguan layanan total dan dapat menyebabkan hilangnya data cache yang belum dipersistensi.
Rekomendasi: Gunakan pengaturan konkurensi tinggi ketika kluster tidak normal dan perlu segera dipulihkan.
Konkurensi: Persentase node yang direstart secara bersamaan. Nilai default adalah 10% dari total jumlah node dalam kluster, dibulatkan ke atas minimal menjadi 1 node. Misalnya, jika konkurensi diatur ke 10%, 10% node dalam kluster direstart sekaligus.
Parameter ini hanya ditampilkan dalam mode restart paksa.
Semua versi
Setelah mengonfirmasi parameter, klik OK.
Jika Anda melakukan restart paksa, Anda juga harus memilih Restart Cluster Forcibly. Setelah operasi dimulai, status instans berubah menjadi Applying. Anda dapat melihat progres restart di daftar tugas di pojok kanan atas halaman. Setelah restart selesai, status instans kembali menjadi Normal.
FAQ
Berapa lama waktu yang dibutuhkan untuk me-restart instans ES atau node?
Apakah mengaktifkan atau menonaktifkan akses jaringan publik untuk instans ES memicu restart?
Apakah mengubah kata sandi akses kluster memicu restart kluster?
Bagaimana cara me-restart node peran (seperti node Kibana) atau node tunggal?