Jika lalu lintas layanan Anda berfluktuasi—misalnya antara jam sibuk dan jam sepi—kluster Anda mungkin mengalami pemanfaatan resource yang rendah. Anda dapat menurunkan spesifikasi kluster agar sesuai dengan kebutuhan bisnis dan mengoptimalkan biaya dengan mengurangi spesifikasi node, jumlah node, atau tipe penyimpanan.
Catatan tentang penurunan spesifikasi
Penurunan spesifikasi kluster dapat menyebabkan penundaan layanan, konflik konfigurasi, dan perubahan penagihan. Baca prasyarat berikut dengan cermat sebelum melanjutkan.
Stabilitas layanan
Aturan berikut berlaku untuk stabilitas layanan selama perubahan konfigurasi kluster:
Kluster
Status layanan
Langkah antisipasi
Payload tinggi + Tidak ada replika
Payload tinggi: Konkurensi tinggi untuk operasi write atau query selama penurunan spesifikasi, dengan penggunaan CPU > 60% dan penggunaan heap memory > 50%.
Sesekali terjadi timeout akses
Aktifkan mekanisme retry pada client.
Sebelum menurunkan spesifikasi, tambahkan jumlah replika indeks menjadi minimal 1.
Jumlah node data ≤ 2 setelah penurunan spesifikasi.
Berpotensi menyebabkan kehilangan data.
Lakukan operasi ini selama jam sepi.
Batasan konfigurasi
Penurunan kapasitas disk node data hanya didukung untuk kluster yang menggunakan arsitektur penyebaran v3.
Anda tidak dapat melakukan upgrade versi kluster selama proses penurunan spesifikasi.
Anda hanya dapat mengubah satu tipe node dalam satu operasi penurunan spesifikasi.
Anda tidak dapat menurunkan spesifikasi elastic data nodes.
Interval antara dua operasi penurunan spesifikasi berturut-turut pada kluster yang sama harus minimal 30 menit.
Batasan spesifikasi CPU setelah penurunan spesifikasi
Aturan dasar: CPU dan memori pada spesifikasi target harus minimal separuh dari spesifikasi saat ini.
Anda tidak dapat menurunkan spesifikasi ke konfigurasi berikut:
1-core 2 GiB,2-core 2 GiB,2-core 4 GiB, atau4-core 4 GiB. Node Kibana dapat diturunkan ke2-core 2 GiB.Kasus khusus: Untuk menurunkan spesifikasi ke konfigurasi yang tidak diizinkan, Anda harus membuat kluster baru lalu melakukan migrasi data.
Dampak biaya
Setelah Anda mengirimkan pesanan penurunan spesifikasi, sistem akan menagih Anda berdasarkan konfigurasi baru. Untuk informasi lebih lanjut, lihat Pay-as-you-go dan Subscription.
Pemeriksaan sebelum penurunan spesifikasi
Jika Anda menurunkan spesifikasi kluster tanpa melakukan pemeriksaan berikut, kluster dapat crash, data dapat hilang, atau layanan menjadi tidak tersedia. Anda wajib memeriksa dan memverifikasi setiap item berikut.
Kesehatan kluster
Jalankan
GET _cluster/healthuntuk memastikan status kluster adalah GREEN.Keamanan payload
Kluster hanya dapat diturunkan spesifikasinya jika memenuhi kondisi berikut:
Tipe node
Penggunaan CPU
Penggunaan heap memory JVM
Dedicated master node
Penggunaan puncak satu node dalam 24 jam terakhir < 30%
Penggunaan puncak satu node dalam 24 jam terakhir < 25%
Node dengan peran lainnya
Kedua kondisi berikut harus dipenuhi:
• Penggunaan puncak satu node dalam 24 jam terakhir < 50%
• Rata-rata penggunaan semua node dalam 24 jam terakhir < 30%
Kedua kondisi berikut harus dipenuhi:
• Penggunaan puncak satu node dalam 24 jam terakhir < 50%
• Rata-rata penggunaan semua node dalam 24 jam terakhir < 30%
Kesiapan indeks
Jalankan
GET /_cat/indices?vuntuk memeriksa apakah ada indeks dalam status CLOSE. Jika ditemukan, jalankanPOST /<index_name>/_openuntuk membukanya sementara. Jika indeks tersebut tidak dibuka, perubahan konfigurasi dapat gagal karena alasan berikut:Jika suatu indeks berada dalam status CLOSE, status kluster tidak dapat berubah menjadi GREEN. Elasticsearch mensyaratkan status kluster GREEN sebelum melakukan perubahan konfigurasi sensitif tertentu, seperti menyesuaikan aturan alokasi shard.
Selama perubahan konfigurasi, kluster melakukan realokasi shard:
Shard dari indeks yang ditutup tidak dapat dialokasikan ulang.
Hal ini menyebabkan operasi yang bergantung pada status GREEN gagal.
Akibatnya, status kluster tidak dapat mencapai GREEN. Status tertinggi yang dapat dicapai hanyalah YELLOW.
Jalankan
GET _cat/indices?vuntuk memastikan jumlah replika setiap indeks minimal 1.Untuk instans multi-zona, pastikan jumlah replika setiap indeks kurang dari jumlah zona yang tersedia untuk instans tersebut. Kami merekomendasikan Anda mengatur jumlah replika menjadi 1. Setelah penurunan spesifikasi selesai, Anda dapat menambahkan jumlah replika secara manual.
Metode 1: Menurunkan spesifikasi kluster melalui Konsol
Menurunkan spesifikasi, tipe disk, dan disk space
Pada halaman Instances, klik .
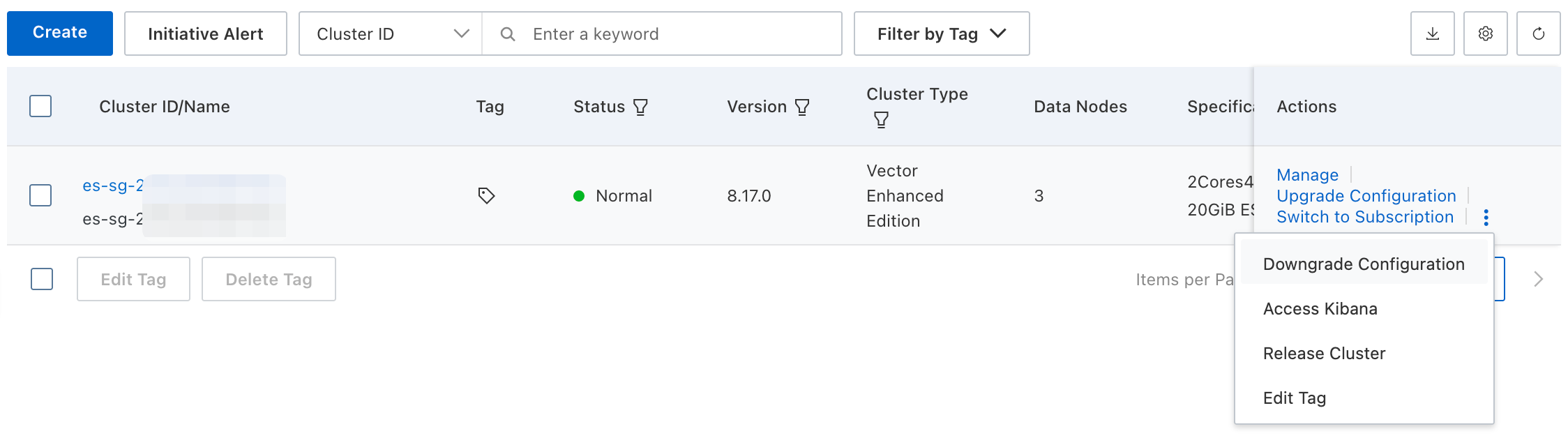
Alternatif: Pada halaman Basic Information, klik .
Pada halaman Downgrade Configuration, sesuaikan parameter konfigurasi sesuai kebutuhan.
PentingParameter konfigurasi yang tersedia bervariasi tergantung tipe dan versi kluster. Parameter pada halaman Downgrade Configuration memiliki prioritas tertinggi.
Anda dapat menurunkan spesifikasi node (tipe penyimpanan node). Tingkat kinerja diurutkan dari tinggi ke rendah:
Disk lokal: Local SSD (disk lokal NVMe SSD) -> Local SATA disk (disk lokal SATA HDD).
CatatanLocal disk adalah perangkat hard disk pada server fisik tempat Instance ECS berada. Disk ini menyediakan akses penyimpanan lokal untuk Instance ECS dan cocok untuk skenario bisnis yang memerlukan kinerja I/O penyimpanan tinggi serta hemat biaya untuk penyimpanan massal.
ESSD: Enterprise SSD (ESSD) menggabungkan jaringan 25 GE dan teknologi Remote Direct Memory Access (RDMA) untuk memberikan hingga 1 juta IOPS baca/tulis acak per disk tunggal serta latensi single-link yang rendah.
CatatanESSD-PL0 tidak dapat diturunkan ke SSD standar.
Disk generasi sebelumnya: Standard SSD -> Ultra disk -> Basic disk.
CatatanDisk ini sedang dihentikan secara bertahap di beberapa wilayah dan zona. Kami merekomendasikan Anda memilih ESSD.
Menurunkan kapasitas disk node data (hanya didukung untuk kluster yang menggunakan mode penyebaran v3): Untuk memastikan stabilitas kluster, penggunaan kapasitas disk setelah penurunan spesifikasi harus kurang dari 60%. Sebelum memulai penurunan spesifikasi, pastikan kondisi berikut terpenuhi: Penggunaan disk saat ini < (kapasitas disk setelah penurunan × 0,6).
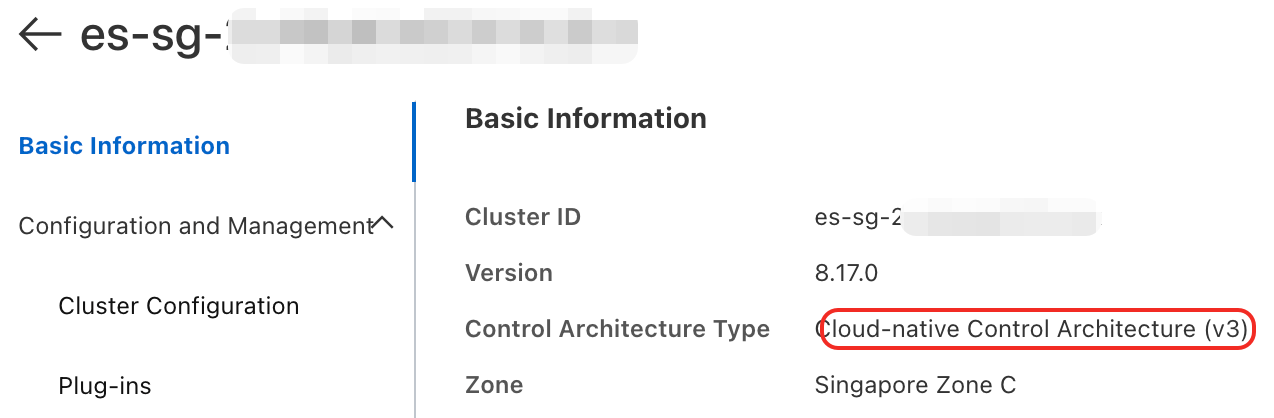
Kluster yang menggunakan mode penyebaran v2 tidak mendukung penurunan kapasitas disk melalui Konsol maupun API. Untuk melakukan penurunan, Anda harus menghubungi dukungan teknis.
Intelligent Update (diaktifkan secara default): Sistem secara otomatis memilih metode optimal berdasarkan perubahan konfigurasi yang Anda tentukan.
Forced Update (dinonaktifkan secara default, tidak disarankan): Opsi ini melewati pemeriksaan kesehatan dan memaksa restart kluster. Hal ini dapat menyebabkan gangguan layanan yang berkepanjangan. Waktu pemulihan tergantung pada volume data.
Klik untuk melihat Terms of Service dan Service Level Agreement. Jika Anda setuju, klik Buy Now. Sistem secara otomatis memilih kebijakan perubahan optimal untuk item konfigurasi dan menagih Anda sesuai metode penagihan.
Selama perubahan berlangsung, status kluster berubah menjadi Initializing. Kinerja kluster mungkin berfluktuasi dan terjadi diskoneksi sementara. Setelah perubahan selesai, status kluster diperbarui menjadi Normal, dan alamat IP node dalam kluster berubah.
Skala-masuk node data
Pada halaman Basic Information instans, klik .
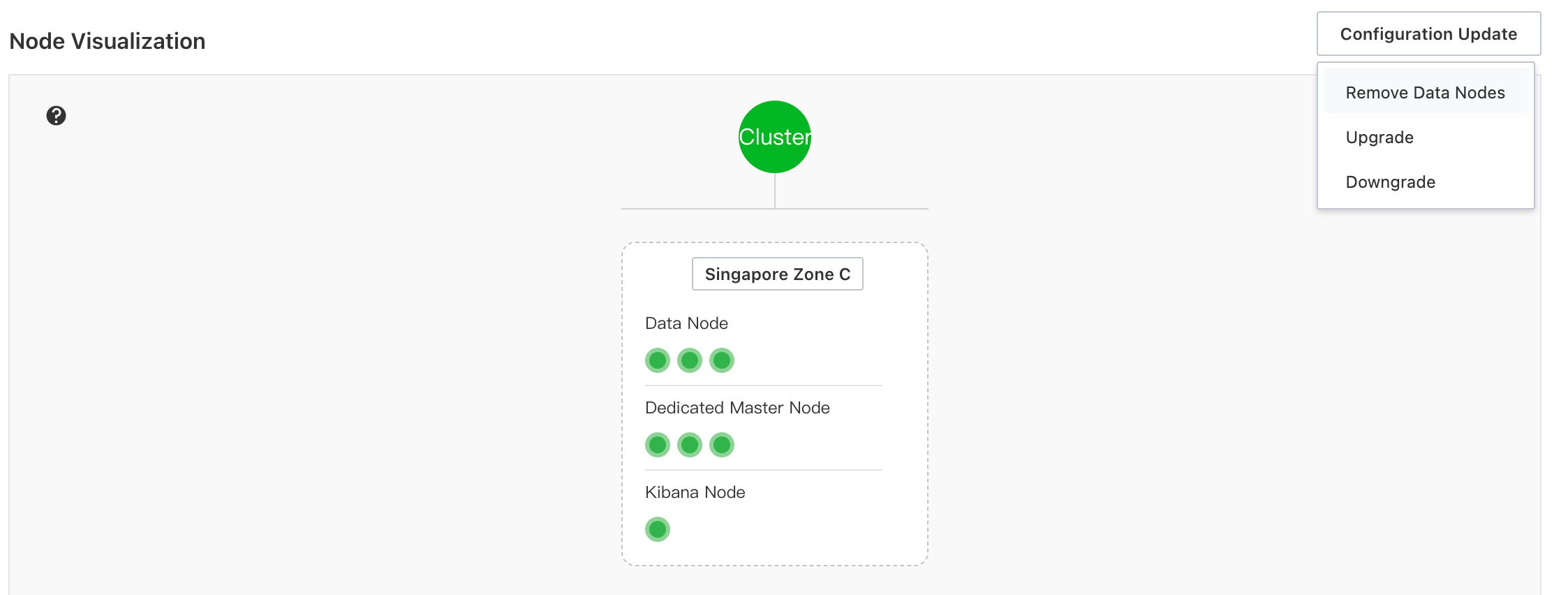
Pilih tipe node dan jumlah node yang akan dihapus sesuai kebutuhan.
PentingAlibaba Cloud ES secara otomatis melakukan pemeriksaan keamanan node sebelum skala-masuk. Jika pemeriksaan gagal, perbaiki masalah berdasarkan pesan error lalu coba ulang operasi skala-masuk.
Parameter konfigurasi yang tersedia bervariasi tergantung tipe dan versi kluster. Parameter pada halaman Console memiliki prioritas tertinggi. Contoh ini menggunakan kluster edisi vector search versi 8.17.0.
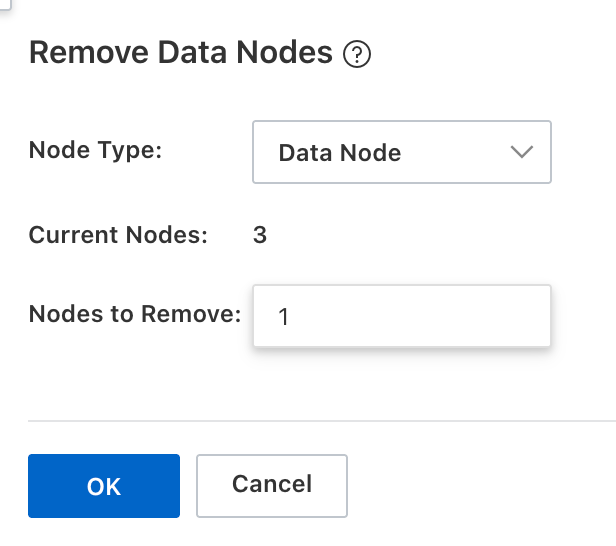
Klik OK. Sistem menjalankan operasi skala-masuk dan menagih Anda berdasarkan konfigurasi kluster dan metode penagihan.
Selama perubahan berlangsung, status kluster berubah menjadi Initializing. Kinerja kluster mungkin berfluktuasi dan terjadi diskoneksi sementara. Setelah perubahan selesai, status kluster diperbarui menjadi Normal, dan alamat IP node dalam kluster berubah.
Metode 2: Menurunkan spesifikasi kluster dengan memanggil API
Untuk informasi lebih lanjut tentang API penurunan spesifikasi kluster, lihat UpdateInstance.
Migrasi data dan rollback
Untuk memastikan keamanan data, node data yang akan dikurangi harus kosong. Jika node data yang dipilih berisi data, sistem akan meminta Anda untuk melakukan migrasi. Setelah migrasi, node yang dipilih tidak lagi berisi data indeks apa pun, dan tidak ada data indeks baru yang ditulis ke node tersebut.
Migrasi data
Pada bagian Remove Data Nodes, klik Data Migration Tool pada prompt.
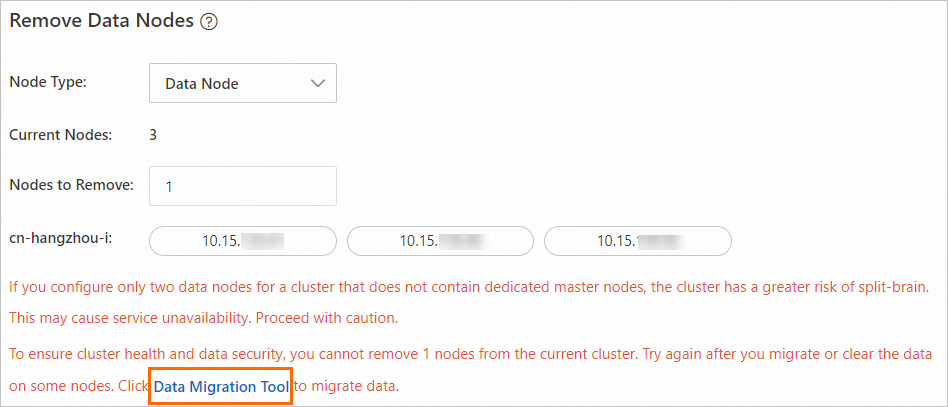
Data Migration Tool menggunakan fitur Elasticsearch shard allocation filtering untuk melakukan migrasi data yang lancar. Proses migrasi data ini transparan bagi layanan Anda.
Pada kotak dialog Migrate Data, pilih metode migrasi node.
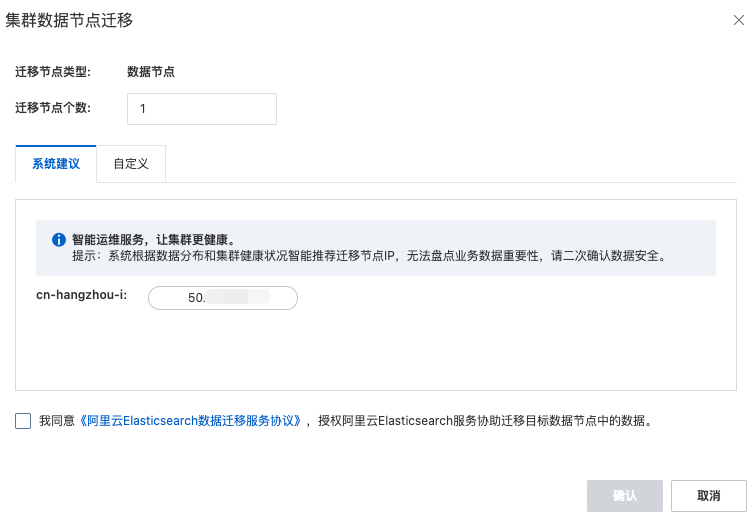
Parameter
Deskripsi
Smart Migration
Sistem secara otomatis memilih node data yang akan dimigrasikan.
Custom
Pilih secara manual node data yang akan dimigrasikan.
Terima perjanjian migrasi data lalu klik OK.
Data rollback
Migrasi data bisa memakan waktu lama. Selama proses ini, perubahan status atau data kluster dapat menyebabkan migrasi gagal. Anda dapat melihat detail tugas di Task List. Jika migrasi data gagal atau setelah selesai, Anda dapat melakukan rollback node yang telah dimigrasikan dengan langkah-langkah berikut:
Login ke Konsol Kibana kluster Elasticsearch Anda dan buka halaman utama Konsol Kibana seperti yang diminta.
Untuk informasi lebih lanjut tentang cara login ke Konsol Kibana, lihat Log on to the Kibana console.
CatatanPada contoh ini, digunakan kluster Elasticsearch V6.7.0. Operasi pada kluster versi lain mungkin berbeda. Ikuti operasi aktual di Konsol.
Pada panel navigasi kiri halaman yang muncul, klik Dev Tools.
Pada Console, jalankan perintah berikut untuk mendapatkan alamat IP node yang telah dimigrasikan.
GET _cluster/settingsJika perintah berhasil dijalankan, hasil berikut akan dikembalikan.
{ "transient": { "cluster": { "routing": { "allocation": { "exclude": { "_ip": "192.168.xx.xx,192.168.xx.xx,192.168.xx.xx" } } } } } }Jalankan perintah berikut untuk melakukan rollback data pada node yang telah dimigrasikan.
Rollback data pada node tertentu. Dalam konfigurasi, hapus alamat IP node yang ingin Anda rollback, tetapi pertahankan alamat IP node yang tidak ingin Anda rollback.
PUT _cluster/settings { "transient": { "cluster": { "routing": { "allocation": { "exclude": { "_ip": "192.168.xx.xx,192.168.xx.xx" } } } } } }Rollback data pada semua node yang telah dimigrasikan.
PUT _cluster/settings { "transient": { "cluster": { "routing": { "allocation": { "exclude": { "_ip": null } } } } } }
Jalankan perintah berikut untuk memverifikasi bahwa rollback data telah selesai.
GET _cluster/settingsJika perintah berhasil dijalankan dan hasilnya tidak berisi alamat IP node yang dimigrasikan, rollback telah selesai. Anda juga dapat memeriksa apakah shard telah dialokasikan ulang ke node tersebut.
CatatanSelama migrasi atau rollback data, Anda dapat menjalankan perintah
GET _cat/shards?vuntuk melihat status tugas.
FAQ
Apa yang harus saya lakukan jika tidak dapat mengubah konfigurasi kluster saya?
Apakah kluster secara otomatis merencanakan ulang shard setelah jumlah node diubah?
Apa yang harus saya lakukan jika memilih konfigurasi yang salah saat membeli instans ES?
Mengapa saya tidak dapat menurunkan spesifikasi cold data nodes?