Monstache menyinkronkan data dari ApsaraDB for MongoDB ke Alibaba Cloud Elasticsearch secara real time dengan mengikuti (tail) oplog MongoDB. Tutorial ini memandu Anda melalui penyiapan lengkap, menggunakan dataset film sebagai contoh untuk menunjukkan sinkronisasi penuh (full-sync), sinkronisasi inkremental, serta analisis data berbasis Kibana.
Monstache menyinkronkan dan berlangganan data secara real time berdasarkan oplog MongoDB. Fitur ini mendukung change streams dan aggregation pipelines MongoDB, serta memungkinkan sinkronisasi data antara database MongoDB dan kluster Elasticsearch versi terbaru. Untuk informasi lebih lanjut mengenai fitur Monstache, lihat Features.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Akun Alibaba Cloud dengan izin untuk membuat instance ECS, instance ApsaraDB for MongoDB, dan kluster Elasticsearch
Pemahaman dasar mengenai operasi command-line Linux
Cara kerja
Monstache menggunakan oplog MongoDB sebagai sumber event. Setiap operasi insert, update, dan delete di MongoDB dicatat dalam oplog; Monstache mengikuti oplog tersebut dan menyebarkan perubahan ke Elasticsearch hampir secara real time. Karena oplog merupakan fitur replica set, instans MongoDB Anda harus berupa instans replica set atau instansi kluster sharded — instans mandiri tidak didukung.
Langkah 1: Buat sumber daya yang diperlukan
Buat sumber daya berikut dalam virtual private cloud (VPC) yang sama. Menempatkan ketiganya dalam VPC yang sama memastikan data ditransmisikan melalui jaringan internal secara aman dan berkecepatan tinggi.
Buat kluster Elasticsearch. Saat pembuatan, aktifkan fitur Auto Indexing. Tutorial ini menggunakan kluster Elasticsearch V6.7 Edisi Standar. Untuk detailnya, lihat Buat kluster Alibaba Cloud Elasticsearch dan Konfigurasikan file YML.
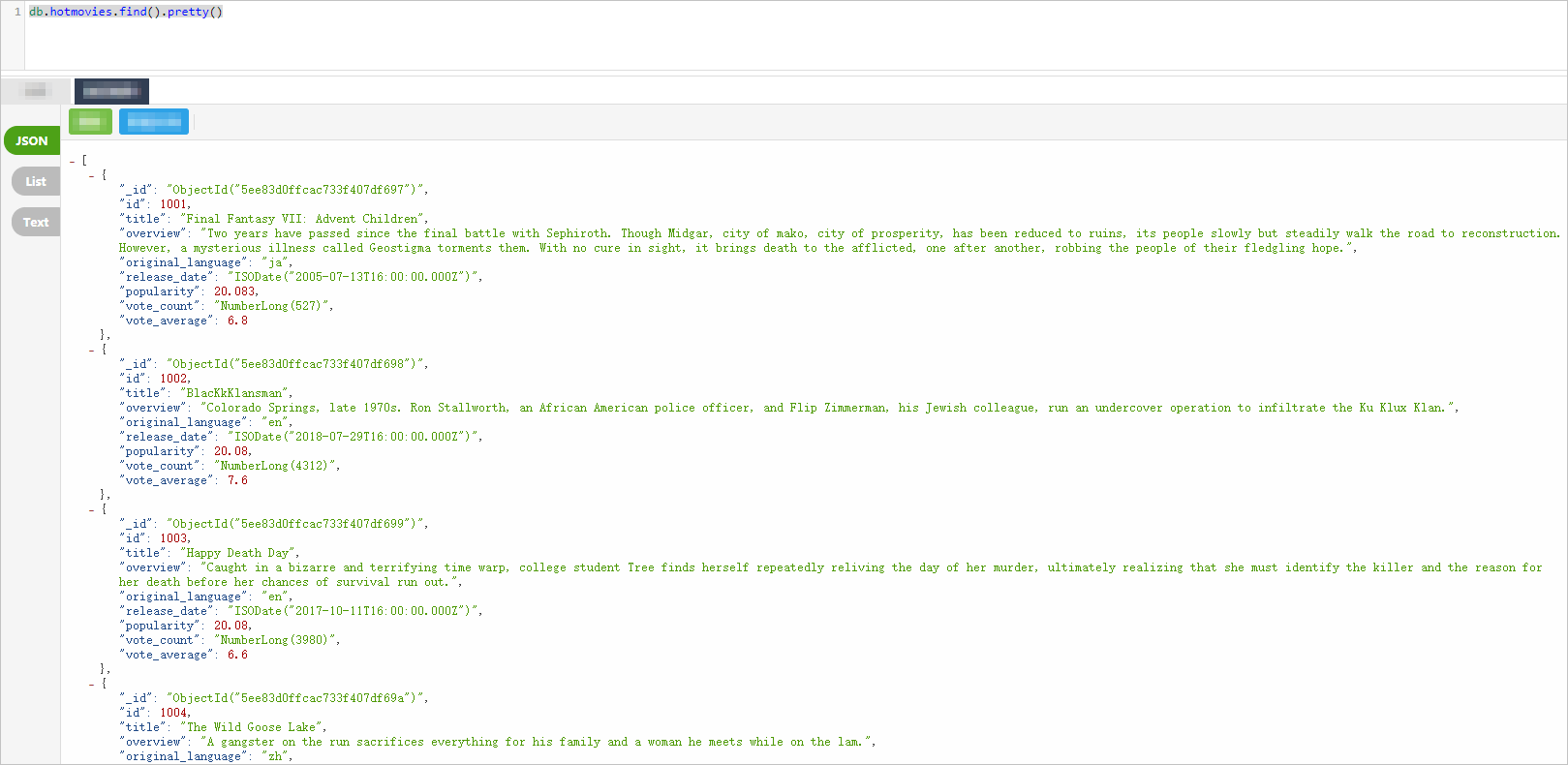
Buat instans ApsaraDB for MongoDB replica set. Tutorial ini menggunakan instans ApsaraDB for MongoDB V4.2 replica set. Siapkan data uji setelah pembuatan — gambar berikut menunjukkan sebagian dataset film yang digunakan sebagai contoh. Untuk detailnya, lihat Panduan cepat untuk instans replica set.
PentingInstans ApsaraDB for MongoDB harus berupa instans replica set atau instansi kluster sharded. Monstache menggunakan oplog sebagai sumber event, yang hanya tersedia pada tipe instans tersebut.
Buat instance Elastic Compute Service (ECS). Instance ECS menjalankan Monstache dan harus menggunakan sistem operasi Linux. Untuk detailnya, lihat Buat instance menggunakan wizard.
Pastikan versi Monstache yang diinstal kompatibel dengan versi instans ApsaraDB for MongoDB dan kluster Elasticsearch Anda. Untuk informasi kompatibilitas versi, lihat Monstache version.
Langkah 2: Instal Monstache
Instal Monstache pada instance ECS dengan membangun dari source code. Sebelum menginstal Monstache, pastikan Anda telah mengonfigurasi variabel lingkungan Go.
Login ke instance ECS. Untuk detailnya, lihat Hubungkan ke instance Linux menggunakan password atau kunci.
CatatanContoh ini menggunakan pengguna biasa (non-root).
Unduh dan ekstrak Go.
wget https://dl.google.com/go/go1.14.4.linux-amd64.tar.gz tar -xzf go1.14.4.linux-amd64.tar.gzKonfigurasikan variabel lingkungan Go. Buka
~/.bash_profile:vim ~/.bash_profileTambahkan baris-baris berikut.
GOPROXYmengarah ke proxy modul Go Alibaba Cloud, yang meningkatkan kecepatan unduh.export GOROOT=/home/test1/go export GOPATH=/home/go/ export PATH=$PATH:$GOROOT/bin:$GOPATH/bin export GOPROXY=https://mirrors.aliyun.com/goproxy/Terapkan perubahan:
source ~/.bash_profileKlon repositori Monstache.
CatatanJika muncul error
git: command not found, instal git terlebih dahulu:sudo yum install -y git.git clone https://github.com/rwynn/monstache.gitBeralih ke branch rel5 dan instal.
cd monstache git checkout rel5 sudo go installVerifikasi instalasi.
monstache -vOutput yang diharapkan:
5.5.5
Langkah 3: Konfigurasikan dan mulai sinkronisasi data
Monstache menggunakan format TOML untuk konfigurasi. Dalam tutorial ini, data disinkronkan dari koleksi hotmovies dan col dalam database mydb.
Di direktori monstache, buat file konfigurasi.
vim config.tomlTambahkan konfigurasi berikut. Ganti nilai placeholder dengan titik akhir dan kredensial aktual Anda.
# pengaturan koneksi mongo-url = "mongodb://<your_mongodb_user>:<your_mongodb_password>@dds-bp1aadcc629******.mongodb.rds.aliyuncs.com:3717" elasticsearch-urls = ["http://es-cn-mp91kzb8m00******.elasticsearch.aliyuncs.com:9200"] # koleksi yang akan disinkronkan (full-sync saat startup, lalu tail oplog) direct-read-namespaces = ["mydb.hotmovies","mydb.col"] # gunakan change streams MongoDB alih-alih tailing oplog (memerlukan MongoDB 3.6+): #change-stream-namespaces = ["mydb.col"] # filter ke koleksi tertentu (hanya untuk pendengar oplog, tidak memicu full-sync): #namespace-regex = '^mydb\.col$' # kredensial Elasticsearch # Untuk penggunaan produksi, buat akun khusus alih-alih menggunakan akun elastic default. # Berikan hanya izin yang dibutuhkan akun tersebut. Lihat Gunakan mekanisme RBAC yang disediakan oleh # Elasticsearch X-Pack untuk menerapkan kontrol akses. elasticsearch-user = "elastic" elasticsearch-password = "<your_es_password>" # jumlah thread Go konkuren yang mendorong dokumen ke Elasticsearch elasticsearch-max-conns = 4 # sebarkan penghapusan koleksi dan database ke Elasticsearch dropped-collections = true dropped-databases = true # simpan progres sinkronisasi ke monstache.monstache agar sinkronisasi dapat dilanjutkan setelah restart resume = true resume-strategy = 0 # aktifkan logging debug (mencatat semua permintaan ke Elasticsearch) verbose = true # mode ketersediaan tinggi: proses yang berbagi cluster-name yang sama saling bekerja sama cluster-name = 'es-cn-mp91kzb8m00******' # pemetaan indeks: timpa nama indeks database.collection default [[mapping]] namespace = "mydb.hotmovies" index = "hotmovies" type = "movies" [[mapping]] namespace = "mydb.col" index = "mydbcol" type = "collection"Parameter utama:
Parameter Deskripsi mongo-urlString koneksi untuk node primary instans ApsaraDB for MongoDB Anda. Dapatkan dari halaman detail instans di konsol ApsaraDB for MongoDB. Sebelum menghubungkan, tambahkan alamat IP pribadi instance ECS ke daftar putih instans MongoDB. Lihat Konfigurasikan daftar putih untuk instansi kluster sharded. elasticsearch-urlsTitik akhir internal kluster Elasticsearch Anda dalam format http://<endpoint>:9200. Dapatkan dari halaman Basic Information kluster Anda. Lihat Lihat informasi dasar kluster.direct-read-namespacesKoleksi yang akan disalin dari MongoDB saat startup (full-sync), ditentukan sebagai database.collection. Lihat direct-read-namespaces.change-stream-namespacesGunakan change streams MongoDB alih-alih tailing oplog. Jika dikonfigurasi, tailing oplog dinonaktifkan. Memerlukan MongoDB 3.6+. Lihat change-stream-namespaces. namespace-regexEkspresi reguler untuk memfilter koleksi mana yang didengarkan Monstache. Ini hanya berfungsi sebagai filter pada pendengar event perubahan — tidak memicu full-sync. elasticsearch-userNama pengguna untuk otentikasi Elasticsearch. Nilai default adalah elastic.elasticsearch-passwordPassword untuk pengguna Elasticsearch. Jika lupa, atur ulang. Lihat Atur ulang password akses kluster Elasticsearch. elasticsearch-max-connsJumlah thread Go konkuren yang menulis ke Elasticsearch. Nilai default adalah 4.dropped-collectionsJika diatur true(default), menghapus indeks Elasticsearch yang dipetakan saat koleksi MongoDB di-drop.dropped-databasesJika diatur true(default), menghapus indeks Elasticsearch yang dipetakan saat database MongoDB di-drop.resumeJika diatur true, menyimpan timestamp oplog kemonstache.monstachesehingga sinkronisasi dapat dilanjutkan setelah restart tanpa kehilangan data. Secara otomatis diatur ketruejikacluster-namedikonfigurasi. Lihat resume.resume-strategyStrategi resume (hanya berlaku jika resumebernilaitrue).0menggunakan timestamp. Lihat resume-strategy.verboseJika diatur true, mengaktifkan logging debug termasuk jejak permintaan Elasticsearch. Nilai default adalahfalse.cluster-nameMengaktifkan mode ketersediaan tinggi. Proses Monstache yang berbagi cluster-nameyang sama saling berkoordinasi. Lihat cluster-name.mappingMenimpa nama indeks default (yang berupa database.collection). Lihat Index Mapping.CatatanMonstache mendukung banyak parameter konfigurasi tambahan. Untuk skenario lanjutan seperti transformasi berbasis skrip, pengindeksan GridFS, atau filtering kompleks, lihat Monstache config dan Advanced.
Jalankan Monstache.
monstache -f config.tomlFlag
-fmemuat file konfigurasi yang ditentukan. Karenaverbose = truediatur dalam konfigurasi, Monstache mencatat semua jejak permintaan Elasticsearch.
Langkah 4: Verifikasi sinkronisasi data
Gunakan konsol Data Management (DMS) untuk kueri MongoDB dan konsol Kibana untuk kueri Elasticsearch.
Untuk akses DMS, lihat Hubungkan ke instans replica set menggunakan DMS.
Untuk akses Kibana, lihat Login ke konsol Kibana.
Periksa jumlah dokumen setelah full-sync
Jalankan kueri berikut untuk memastikan jumlah dokumen yang sama muncul di kedua sistem.
MongoDB:
db.hotmovies.find().count()Output yang diharapkan:
[
10000
]Elasticsearch:
GET hotmovies/_countOutput yang diharapkan:
{
"count" : 10000,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
}
}Uji sinkronisasi insert
Insert dua dokumen di MongoDB:
db.hotmovies.insert({id: 11003,title: "Beauty",overview: "How a group of IT women with high IQ become outstanding",original_language:"cn",release_date:"2020-06-17",popularity:67.654,vote_count:65487,vote_average:9.9})
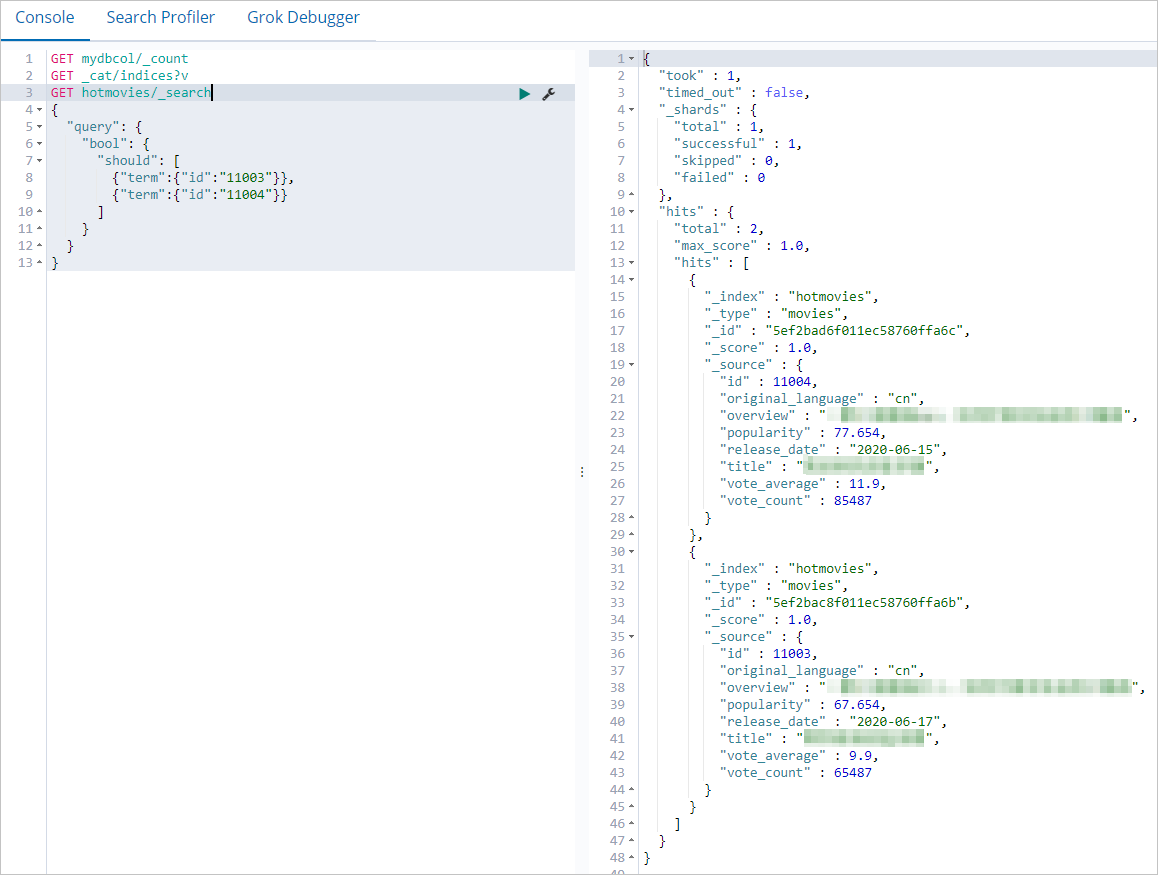
db.hotmovies.insert({id: 11004,title: "Heroic Programmers",overview: "How a group of IT men with high IQ become outstanding",original_language:"cn",release_date:"2020-06-15",popularity:77.654,vote_count:85487,vote_average:11.9})Kueri Elasticsearch untuk memastikan dokumen telah disinkronkan:
GET hotmovies/_search
{
"query": {
"bool": {
"should": [
{"term":{"id":"11003"}},
null
]
}
}
}
Uji sinkronisasi update
Update dokumen di MongoDB:
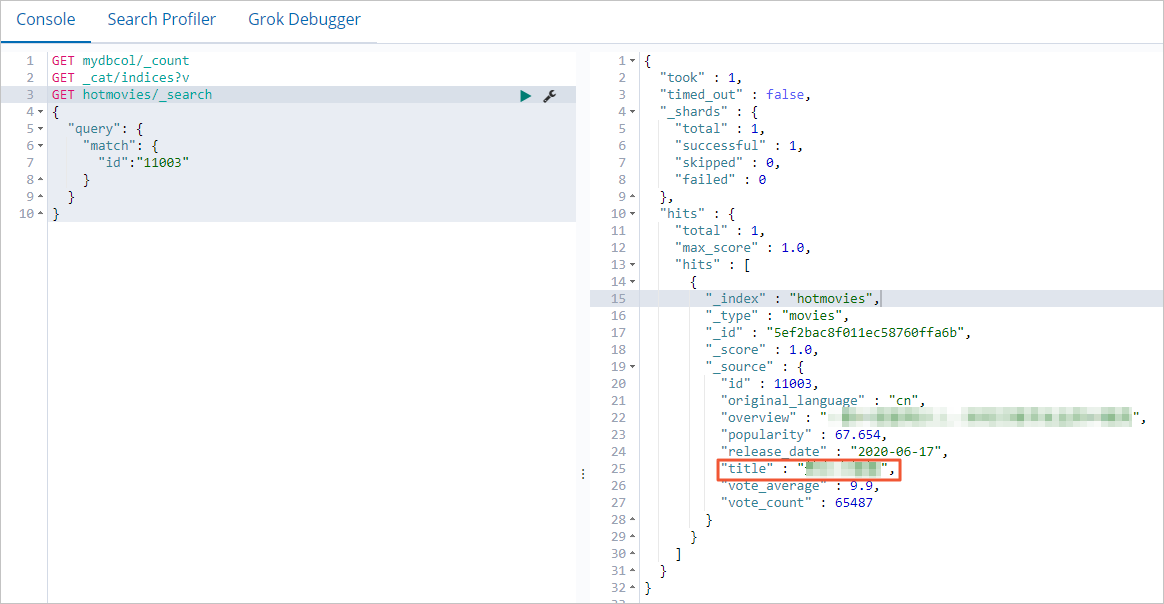
db.hotmovies.update({'title':'Beauty'},{$set:{'title':'Beautiful Programmers'}})Kueri Elasticsearch untuk memastikan update telah diterapkan:
GET hotmovies/_search
{
"query": {
"match": {
"id":"11003"
}
}
}
Uji Sinkronisasi Penghapusan
Hapus dokumen dari MongoDB:
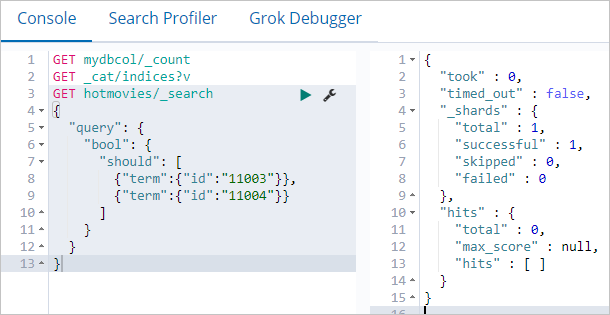
db.hotmovies.remove({id: 11003})
db.hotmovies.remove({id: 11004})Kueri Elasticsearch untuk memastikan dokumen telah dihapus:
GET hotmovies/_search
{
"query": {
"bool": {
"should": [
{"term":{"id":"11003"}},
null
]
}
}
}
Langkah 5: Analisis data di Kibana
Tutorial ini menggunakan Kibana V6.7.0. Navigasi mungkin berbeda pada versi lain.
Login ke konsol Kibana. Untuk detailnya, lihat Login ke konsol Kibana.
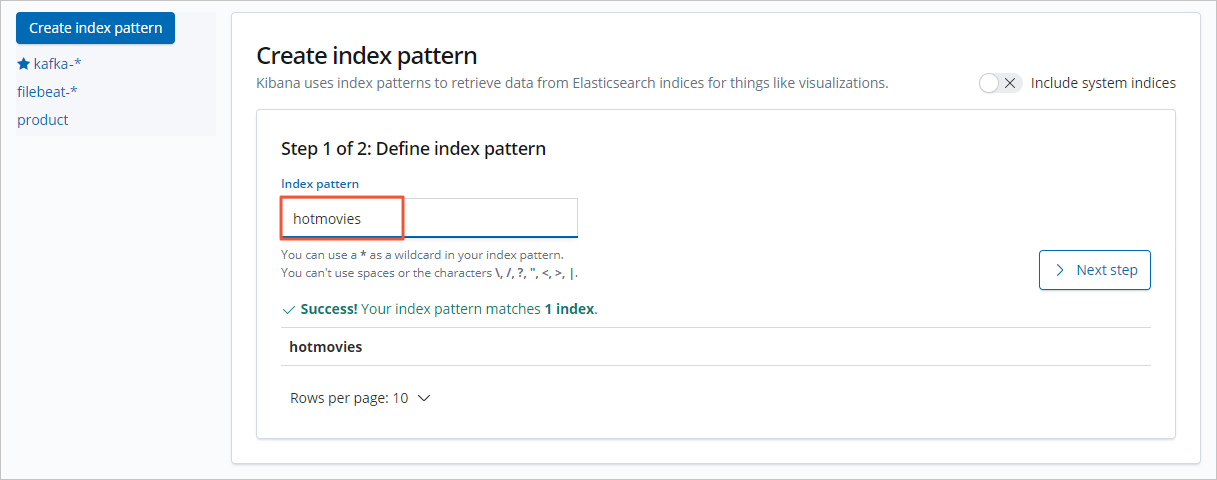
Buat pola indeks.
Di panel navigasi kiri, klik Management.
Di bagian Kibana, klik Index Patterns.
Klik Create index pattern.
Atur Index pattern dan klik Next step.
Atur Time Filter field name ke I don't want to use the Time Filter.
Klik Create index pattern.
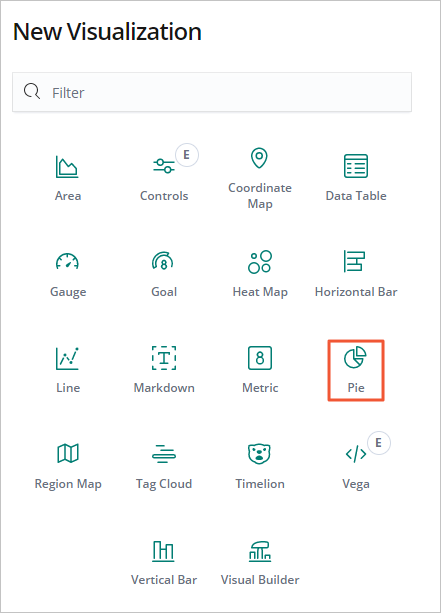
Buat grafik pie untuk 10 film paling populer.
Di panel navigasi kiri, klik Visualize.
Klik + di samping kotak pencarian.
Di dialog New Visualization, klik Pie.
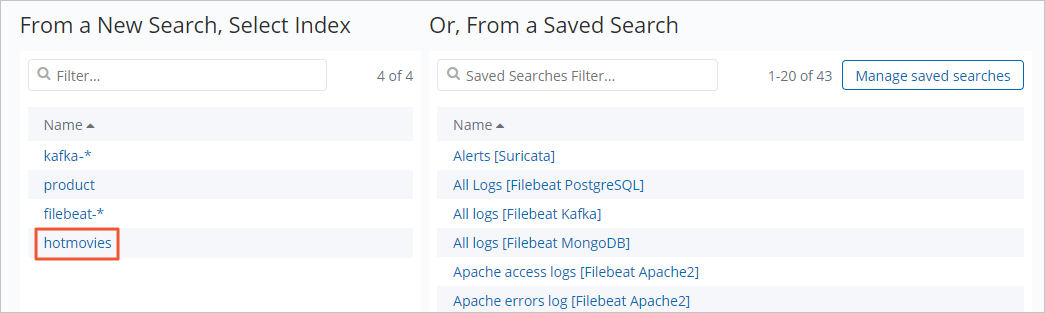
Klik pola indeks hotmovies.
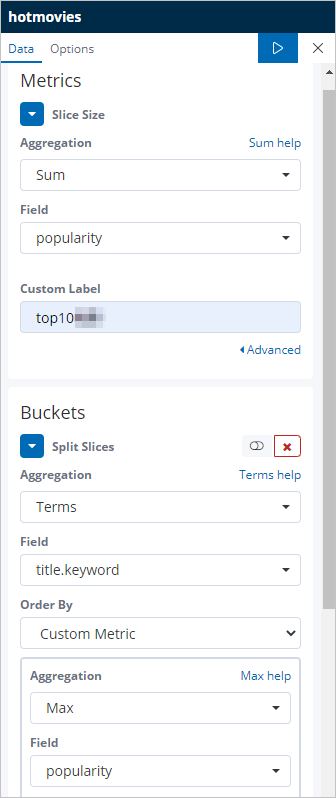
Konfigurasikan bagian Metrics dan Buckets seperti yang ditunjukkan.
Klik ikon
 untuk menerapkan konfigurasi.
untuk menerapkan konfigurasi. 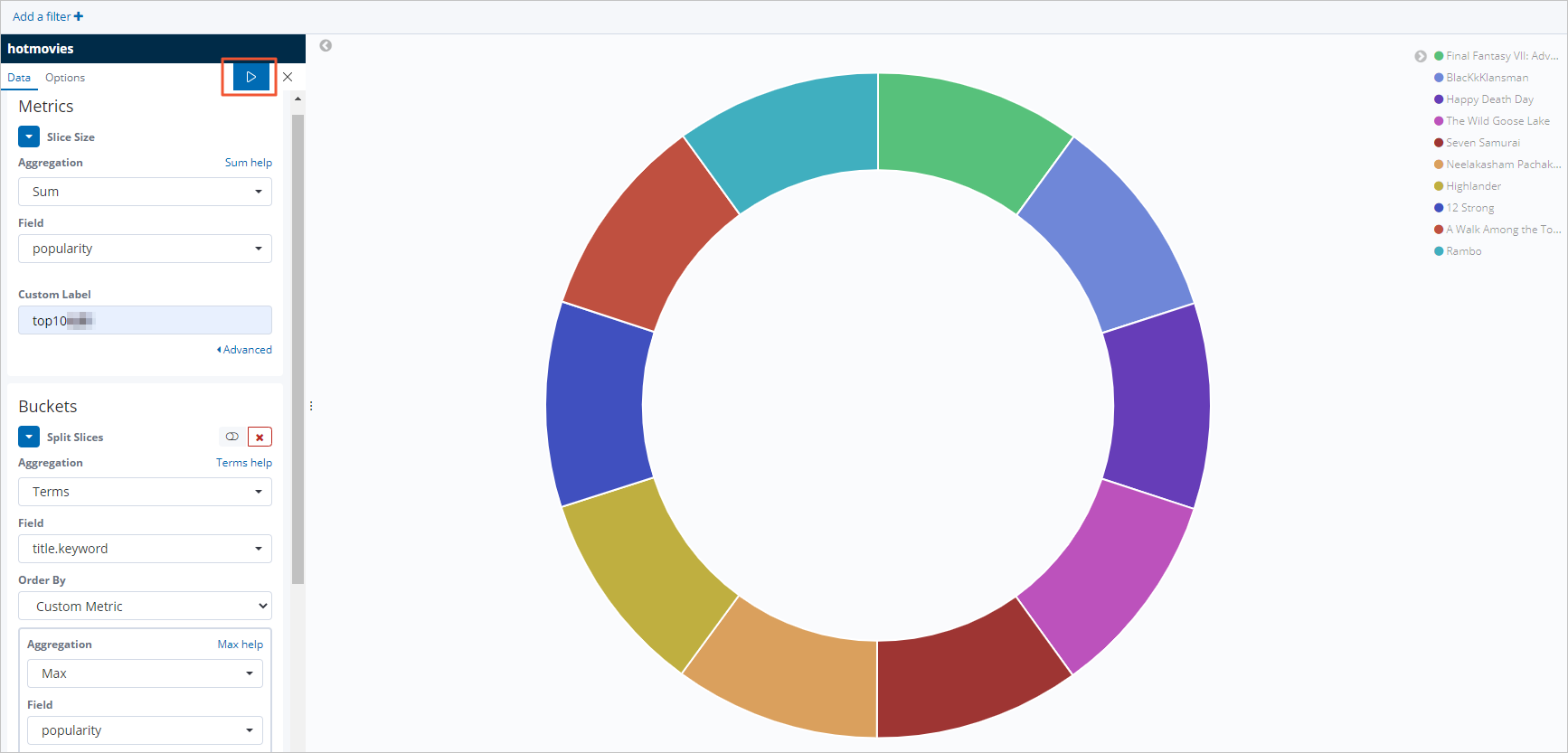
FAQ
Setelah mengaktifkan ketersediaan tinggi dan meningkatkan konkurensi, terjadi kehilangan data. Apa yang harus saya lakukan?
Pertama, periksa apakah kluster Elasticsearch dalam kondisi sehat. Jika kluster berada dalam kondisi abnormal, rujuk ke Elasticsearch FAQ untuk mendiagnosis dan menyelesaikan masalah tingkat kluster, lalu turunkan nilai elasticsearch-max-conns dan pantau kemungkinan kehilangan data lebih lanjut.
Jika kluster dalam kondisi sehat, kemungkinan besar masalah berasal dari Monstache. Periksa dokumentasi Monstache untuk mengetahui isu-isu yang diketahui dan panduan konfigurasi.