Jika data bisnis Anda disimpan di PolarDB-X 1.0 dan Anda ingin melakukan pencarian teks lengkap serta analitik semantik pada data tersebut, Anda dapat menggunakan Alibaba Cloud Elasticsearch dan Alibaba Cloud Logstash. Topik ini menjelaskan cara menggunakan Alibaba Cloud Logstash untuk menyinkronkan data dari PolarDB-X 1.0 ke Alibaba Cloud Elasticsearch secara real time.
Informasi latar belakang
Alibaba Cloud Logstash adalah alat andal untuk pengumpulan dan pemrosesan data yang mampu mengonsumsi, mentransformasi, mengoptimalkan, dan menghasilkan output data. Plugin logstash-input-jdbc—yang diinstal secara default dan tidak dapat dihapus—memungkinkan Anda mengambil data dari PolarDB-X secara batch dan menyinkronkannya ke Elasticsearch. Plugin ini juga melakukan polling berkala terhadap PolarDB-X untuk menyinkronkan catatan yang telah dimasukkan atau diubah sejak polling terakhir. Solusi ini ideal baik untuk sinkronisasi penuh awal maupun pembaruan inkremental berikutnya, yang biasanya memiliki latensi beberapa detik.
Prasyarat
Instans PolarDB-X 1.0, kluster Alibaba Cloud Elasticsearch, dan kluster Alibaba Cloud Logstash telah dibuat. Selain itu, sebuah database telah dibuat di instans PolarDB-X 1.0. Disarankan agar Anda membuat instans PolarDB-X 1.0, kluster Elasticsearch, dan kluster Logstash dalam virtual private cloud (VPC) yang sama.
Instans PolarDB-X 1.0 dan database telah dibuat. Untuk informasi lebih lanjut, lihat Buat instans PolarDB-X 1.0.
Untuk informasi lebih lanjut tentang cara membuat kluster Alibaba Cloud Elasticsearch, lihat Buat kluster Alibaba Cloud Elasticsearch. Dalam contoh ini, kluster Elasticsearch V6.7 Edisi Standar dibuat.
Untuk informasi lebih lanjut tentang cara membuat kluster Alibaba Cloud Logstash, lihat Buat kluster Alibaba Cloud Logstash.
CatatanJika Anda ingin menggunakan Logstash untuk mengumpulkan data dari Internet atau mentransfer data yang dikumpulkan ke Internet, Anda harus mengonfigurasi gerbang Network Address Translation (NAT) dan menggunakan gerbang tersebut untuk menghubungkan kluster Logstash Anda ke Internet. Untuk informasi lebih lanjut, lihat Konfigurasi gerbang NAT untuk transmisi data melalui Internet.
Batasan
Nilai bidang _id di kluster Elasticsearch harus sama dengan nilai bidang id di database PolarDB-X 1.0.
Kondisi ini memastikan bahwa tugas sinkronisasi data dapat membuat pemetaan antara catatan data di database PolarDB-X 1.0 dan dokumen di kluster Elasticsearch. Jika Anda memperbarui catatan data di database PolarDB-X 1.0, tugas sinkronisasi data akan menggunakan catatan data yang diperbarui tersebut untuk menimpa dokumen dengan ID yang sama di kluster Elasticsearch.
CatatanPada dasarnya, operasi update di Elasticsearch menghapus dokumen asli dan mengindeks dokumen baru. Oleh karena itu, operasi penimpaan ini sama efisiennya dengan operasi update yang dilakukan oleh tugas sinkronisasi data.
Jika Anda memasukkan atau memperbarui catatan data di database PolarDB-X 1.0, catatan data tersebut harus berisi bidang yang menunjukkan waktu saat catatan data dimasukkan atau diperbarui.
Setiap kali plugin logstash-input-jdbc melakukan round robin, plugin tersebut mencatat waktu saat catatan data terakhir dalam round robin tersebut dimasukkan atau diperbarui di database PolarDB-X 1.0. Logstash hanya menyinkronkan catatan data dari database PolarDB-X 1.0 yang memenuhi persyaratan berikut: Waktu saat catatan data dimasukkan atau diperbarui di database PolarDB-X 1.0 lebih baru daripada waktu saat catatan data terakhir dalam round robin sebelumnya dimasukkan atau diperbarui di database PolarDB-X 1.0.
PentingJika Anda menghapus catatan data di database PolarDB-X 1.0, plugin logstash-input-jdbc tidak dapat menghapus dokumen dengan ID yang sama dari kluster Elasticsearch. Untuk menghapus dokumen tersebut dari kluster Elasticsearch, Anda harus menjalankan perintah terkait pada kluster Elasticsearch.
Prosedur
Langkah 1: Persiapan
Buat tabel di instans PolarDB-X 1.0 Anda dan isi dengan data uji.
Dalam contoh ini, pernyataan berikut digunakan untuk membuat tabel:
CREATE table food( id int PRIMARY key AUTO_INCREMENT, name VARCHAR (32), insert_time DATETIME, update_time DATETIME );Pernyataan berikut digunakan untuk memasukkan data ke dalam tabel:
INSERT INTO food values(null,'chocolate',now(),now()); INSERT INTO food values(null,'yogurt',now(),now()); INSERT INTO food values(null,'ham sausage',now(),now());Aktifkan fitur Auto Indexing untuk kluster Elasticsearch. Untuk informasi lebih lanjut, lihat Akses dan konfigurasi kluster Elasticsearch.
Di kluster Logstash, unggah driver SQL JDBC yang versinya kompatibel dengan versi database PolarDB-X 1.0. Untuk informasi lebih lanjut, lihat Konfigurasi library pihak ketiga. Dalam contoh ini, driver mysql-connector-java-5.1.35 digunakan.
CatatanDalam contoh ini, driver JDBC MySQL digunakan untuk menghubungkan ke database PolarDB-X 1.0. Anda juga dapat menggunakan driver JDBC PolarDB untuk menghubungkan ke database PolarDB-X 1.0. Namun, untuk database PolarDB-X 2.0, driver JDBC PolarDB mungkin tidak berfungsi. Disarankan agar Anda menggunakan driver JDBC MySQL.
Dapatkan alamat IP node-node di kluster Logstash dari halaman Informasi Dasar kluster Logstash di Konsol Elasticsearch. Kemudian, tambahkan alamat IP tersebut ke daftar putih alamat IP instans PolarDB-X 1.0. Untuk informasi lebih lanjut, lihat Atur daftar putih alamat IP.
Langkah 2: Konfigurasi pipeline Logstash
Buka halaman Logstash Clusters.
Navigasi ke kluster target.
Di bilah navigasi atas, pilih wilayah tempat kluster berada.
Di halaman Logstash Clusters, temukan kluster tersebut dan klik ID-nya.
- Di panel navigasi kiri, klik Pipelines.
Klik Create Pipeline.
Di halaman Create, masukkan Pipeline ID dan konfigurasikan pipeline di kotak teks Config.
Dalam contoh ini, konfigurasi berikut dimasukkan di bidang Config Settings:
input { jdbc { jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_driver_library => "/ssd/1/share/<Logstash cluster ID>/logstash/current/config/custom/mysql-connector-java-5.1.35.jar" jdbc_connection_string => "jdbc:mysql://drdshbga51x6****.drds.aliyuncs.com:3306/<Your database name>?useUnicode=true&characterEncoding=utf-8&useSSL=false&allowLoadLocalInfile=false&autoDeserialize=false" jdbc_user => "db_user" jdbc_password => "db_password" jdbc_paging_enabled => "true" jdbc_page_size => "50000" statement => "select * from food where update_time >= :sql_last_value" schedule => "* * * * *" record_last_run => true last_run_metadata_path => "/ssd/1/<Logstash cluster ID>/logstash/data/last_run_metadata_update_time.txt" clean_run => false tracking_column_type => "timestamp" use_column_value => true tracking_column => "update_time" } } filter { } output { elasticsearch { hosts => "http://es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com:9200" user => "elastic" password => "es_password" index => "drds_test" document_id => "%{id}" } }CatatanDalam kode tersebut, ganti
<Logstash cluster ID>dengan ID kluster Logstash Anda. Untuk informasi lebih lanjut, lihat Lihat ikhtisar daftar kluster.Tabel 1. Parameter pada bagian input
Parameter
Deskripsi
jdbc_driver_class
Kelas driver JDBC.
jdbc_driver_library
Jalur file driver JDBC. Untuk informasi lebih lanjut, lihat Konfigurasi library pihak ketiga.
jdbc_connection_string
String koneksi JDBC yang digunakan untuk menghubungkan ke database PolarDB-X 1.0. String koneksi JDBC berisi titik akhir, nomor port, dan nama database PolarDB-X 1.0.
jdbc_user
Username yang digunakan untuk mengakses database PolarDB-X 1.0.
jdbc_password
Password yang digunakan untuk mengakses database PolarDB-X 1.0.
jdbc_paging_enabled
Menentukan apakah paging diaktifkan. Nilai default: false.
jdbc_page_size
Jumlah entri per halaman.
statement
Pernyataan SQL.
schedule
Jadwal untuk tugas sinkronisasi.
"* * * * *"berarti data disinkronkan setiap menit.record_last_run
Menentukan apakah hasil eksekusi terakhir dicatat. Jika parameter ini diatur ke true, nilai tracking_column pada hasil eksekusi terakhir disimpan dalam file di jalur yang ditentukan oleh parameter last_run_metadata_path.
last_run_metadata_path
Jalur file yang berisi waktu eksekusi terakhir. Jalur file disediakan oleh backend. Jalurnya dalam format /ssd/1/<Logstash cluster ID>/logstash/data/. Setelah Anda menentukan jalur, Logstash secara otomatis membuat file di jalur tersebut, tetapi Anda tidak dapat melihat datanya.
clean_run
Menentukan apakah jalur yang ditentukan oleh parameter last_run_metadata_path dihapus. Nilai default: false. Jika parameter ini diatur ke true, setiap kueri dimulai dari entri pertama di database.
use_column_value
Menentukan apakah nilai kolom tertentu dicatat.
tracking_column_type
Tipe kolom yang nilainya ingin Anda lacak. Nilai default: numeric.
tracking_column
Kolom yang nilainya ingin Anda lacak. Nilai-nilai tersebut harus diurutkan secara ascending. Biasanya, kolom ini adalah primary key tabel.
Tabel 2. Parameter pada bagian output
Parameter
Deskripsi
hosts
Titik akhir pribadi kluster Alibaba Cloud Elasticsearch, dalam format
http://<Private endpoint of the cluster>:9200. Anda dapat menemukan titik akhir pribadi di halaman Informasi Dasar. Untuk informasi lebih lanjut, lihat Lihat informasi dasar kluster.user
Username yang digunakan untuk mengakses kluster Elasticsearch. Username default adalah elastic.
password
Password akun elastic. Password akun elastic ditentukan saat Anda membuat kluster Elasticsearch. Jika Anda lupa password tersebut, Anda dapat mengatur ulang. Untuk prosedur dan tindakan pencegahan saat mengatur ulang password, lihat Atur ulang password akses kluster Elasticsearch.
index
Nama indeks di kluster Elasticsearch.
document_id
ID dokumen di kluster Elasticsearch. Atur parameter ini ke %{id}, yang menunjukkan bahwa ID dokumen sama dengan ID catatan data di database PolarDB-X 1.0.
PentingKonfigurasi di atas didasarkan pada data uji. Anda dapat mengonfigurasi pipeline sesuai dengan kebutuhan bisnis Anda. Untuk informasi lebih lanjut tentang parameter lain yang didukung oleh plugin input, lihat Plugin input Logstash Jdbc.
Jika konfigurasi Anda mencakup parameter seperti
last_run_metadata_path, jalur file harus disediakan oleh layanan Alibaba Cloud Logstash. Sistem menyediakan jalur/ssd/1/<Logstash cluster ID>/logstash/data/untuk tujuan pengujian. Data dalam direktori ini tidak dihapus. Pastikan Anda memiliki ruang disk yang cukup. Logstash secara otomatis membuat file di jalur yang ditentukan, tetapi Anda tidak dapat melihat isinya.Untuk keamanan yang lebih baik, jika Anda menggunakan driver JDBC dalam konfigurasi pipeline Anda, Anda harus menambahkan
allowLoadLocalInfile=false&autoDeserialize=falseke parameterjdbc_connection_string. Jika tidak, sistem penjadwalan akan melaporkan kegagalan validasi saat Anda menambahkan file konfigurasi Logstash. Contohnya:jdbc_connection_string => "jdbc:mysql://drdshbga51x6****.drds.aliyuncs.com:3306/<Your database name>?allowLoadLocalInfile=false&autoDeserialize=false".
Untuk informasi lebih lanjut tentang cara mengonfigurasi parameter di bidang Config Settings, lihat File konfigurasi Logstash.
Klik Next step dan konfigurasikan parameter pipeline.
Parameter
Deskripsi
Pipeline Workers
Jumlah thread pekerja untuk menjalankan tahap filter dan output pipeline secara paralel. Jika Anda memiliki backlog event atau CPU Anda tidak dimanfaatkan secara optimal, pertimbangkan untuk meningkatkan nilai ini guna meningkatkan kinerja. Nilai default: jumlah core CPU di instans.
Pipeline Batch Size
Jumlah maksimum event yang dikumpulkan oleh thread pekerja dari input sebelum mengeksekusi filter dan output. Ukuran batch yang lebih besar dapat menyebabkan overhead memori yang lebih tinggi. Untuk menggunakan ukuran batch yang lebih besar secara efektif, Anda mungkin perlu meningkatkan ukuran heap JVM dengan mengatur variabel LS_HEAP_SIZE. Nilai default: 125.
Pipeline Batch Delay
Durasi dalam milidetik untuk menunggu setiap event sebelum mengirimkan batch kecil ke thread pekerja pipeline. Nilai default: 50 ms.
Queue Type
Model antrian internal untuk buffering event. Nilai yang valid:
MEMORY: Nilai default. Ini menentukan antrian tradisional berbasis memori.
PERSISTED: Antrian persisten berbasis disk.
Queue Max Bytes
Jumlah maksimum data yang dapat disimpan oleh antrian, dalam
MB. Nilainya harus berupa bilangan bulat dari1hingga2<sup>53</sup>-1. Nilai default:1024.CatatanPastikan nilai ini lebih kecil dari kapasitas disk total Anda.
Queue Checkpoint Writes
Saat antrian persisten diaktifkan, ini adalah jumlah maksimum event yang dapat ditulis sebelum checkpoint dipaksakan. Nilai 0 menunjukkan tidak ada batasan. Nilai default: 1024.
PeringatanSetelah dikonfigurasi, Anda harus menyimpan dan menerapkan pengaturan agar berlaku. Tindakan ini memicu restart instans. Lanjutkan hanya jika restart tersebut tidak berdampak pada bisnis Anda.
Klik Save atau Save and Deploy.
Save: Menyimpan konfigurasi pipeline tetapi tidak menerapkannya. Setelah disimpan, Anda akan dikembalikan ke halaman Pipelines. Di bagian Pipelines, Anda dapat mengklik Deploy Now di kolom Actions untuk me-restart instans dan menerapkan konfigurasi.
Save and Deploy: Menyimpan dan menerapkan konfigurasi, me-restart instans untuk menerapkan perubahan.
Langkah 3: Verifikasi hasil
Login ke Konsol Kibana kluster Elasticsearch.
Untuk informasi lebih lanjut, lihat Login ke Konsol Kibana.
Di panel navigasi kiri, klik Dev Tools.
Di Console, jalankan perintah berikut untuk melihat jumlah dokumen yang telah disinkronkan.
GET drds_test/_count { "query": {"match_all": {}} }Jika perintah berhasil dijalankan, hasil berikut dikembalikan:
{ "count" : 3, "_shards" : { "total" : 1, "successful" : 1, "skipped" : 0, "failed" : 0 } }Perbarui data di tabel dan masukkan data ke dalam tabel.
UPDATE food SET name='Chocolates',update_time=now() where id = 1; INSERT INTO food values(null,'egg',now(),now());Lihat data yang telah diperbarui dan dimasukkan.
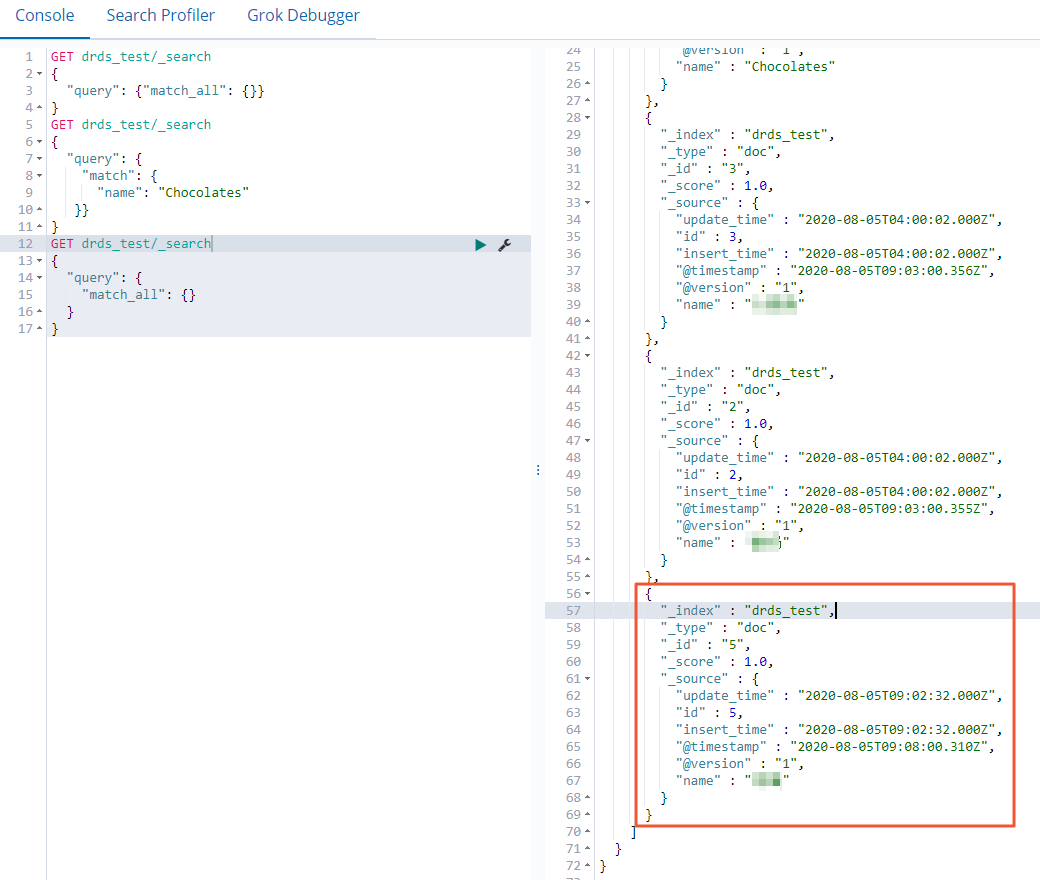
Kueri catatan data di mana nilai name adalah Chocolates.
GET drds_test/_search { "query": { "match": { "name": "Chocolates" }} }Jika perintah berhasil dijalankan, hasil seperti pada gambar berikut dikembalikan.
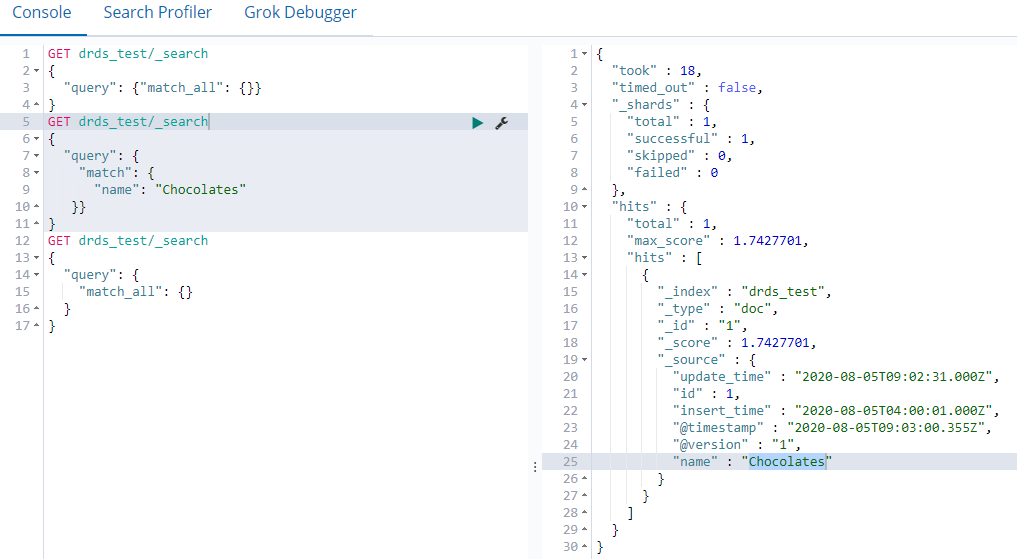
Kueri semua data.
GET drds_test/_search { "query": { "match_all": {} } }Jika perintah berhasil dijalankan, hasil seperti pada gambar berikut dikembalikan.