ES-Hadoop adalah alat yang dikembangkan oleh Elasticsearch open source. Alat ini menghubungkan Elasticsearch dengan Apache Hadoop dan memungkinkan transmisi data di antara keduanya. ES-Hadoop menggabungkan kemampuan pencarian cepat dari Elasticsearch dan kemampuan pemrosesan batch dari Hadoop untuk mencapai pemrosesan data interaktif. Untuk beberapa tugas analitik data yang kompleks, Anda perlu menjalankan tugas MapReduce untuk membaca data dari file JSON yang disimpan dalam Hadoop Distributed File System (HDFS) dan menulis data tersebut ke kluster Elasticsearch. Topik ini menjelaskan cara menggunakan ES-Hadoop untuk menjalankan tugas MapReduce tersebut.
Prosedur
- PersiapanBuat kluster Alibaba Cloud Elasticsearch dan kluster E-MapReduce (EMR) di virtual private cloud (VPC) yang sama. Aktifkan fitur Auto Indexing untuk kluster Elasticsearch, serta siapkan data uji dan lingkungan Java.
- Langkah 1: Unggah Paket JAR ES-Hadoop ke HDFSUnduh paket ES-Hadoop dan unggah paket tersebut ke direktori HDFS pada node master di kluster EMR.
- Langkah 2: Konfigurasikan Dependensi POMBuat proyek Java Maven dan konfigurasikan dependensi POM.
- Langkah 3: Kompilasi Kode dan Jalankan Tugas MapReduceKompilasi kode Java yang digunakan untuk menulis data ke kluster Elasticsearch. Kompres kode menjadi paket JAR dan unggah paket tersebut ke kluster EMR. Kemudian, jalankan kode dalam tugas MapReduce untuk menulis data.
- Langkah 4: Verifikasi HasilMasuk ke konsol Kibana dari kluster Elasticsearch. Kemudian, kueri data yang ditulis oleh tugas MapReduce.
Persiapan
- Buat kluster Alibaba Cloud Elasticsearch dan aktifkan fitur Auto Indexing untuk kluster tersebut.Untuk informasi lebih lanjut, lihat Buat Kluster Alibaba Cloud Elasticsearch dan Akses dan Konfigurasikan Kluster Elasticsearch. Dalam topik ini, kluster Elasticsearch V6.7.0 dibuat.Penting Dalam lingkungan produksi, kami sarankan Anda menonaktifkan fitur Auto Indexing. Anda harus membuat indeks dan mengonfigurasi pemetaan untuk indeks tersebut terlebih dahulu. Kluster Elasticsearch yang digunakan dalam topik ini hanya untuk pengujian. Oleh karena itu, fitur Auto Indexing diaktifkan.
- Buat kluster EMR yang berada di VPC yang sama dengan kluster Elasticsearch.Konfigurasi kluster EMR:
- Versi EMR: Pilih EMR-3.29.0.
- Layanan yang Diperlukan: HDFS (2.8.5) adalah salah satu layanan yang diperlukan. Pengaturan default dipertahankan untuk layanan lainnya.
Untuk informasi lebih lanjut, lihat Buat Kluster.PentingSecara default, 0.0.0.0/0 ditentukan dalam daftar putih alamat IP privat kluster Elasticsearch. Anda dapat melihat konfigurasi daftar putih pada halaman konfigurasi keamanan kluster. Jika pengaturan default tidak digunakan, Anda harus menambahkan alamat IP privat kluster EMR ke daftar putih.
Untuk informasi lebih lanjut tentang cara mendapatkan alamat IP privat kluster EMR, lihat Lihat Daftar Kluster dan Detail Kluster.
Untuk informasi lebih lanjut tentang cara mengonfigurasi daftar putih alamat IP privat untuk kluster Elasticsearch, lihat Konfigurasikan Daftar Putih Alamat IP Publik atau Privat untuk Kluster Elasticsearch. Alamat IP dalam daftar putih dapat digunakan untuk mengakses kluster Elasticsearch melalui VPC.
- Siapkan data uji berformat JSON dan tulis data tersebut ke file map.json. Unggah file tersebut ke direktori /tmp/hadoop-es HDFS.Data uji berikut digunakan dalam topik ini:
{"id": 1, "name": "zhangsan", "birth": "1990-01-01", "addr": "No.969, wenyixi Rd, yuhang, hangzhou"} {"id": 2, "name": "lisi", "birth": "1991-01-01", "addr": "No.556, xixi Rd, xihu, hangzhou"} {"id": 3, "name": "wangwu", "birth": "1992-01-01", "addr": "No.699 wangshang Rd, binjiang, hangzhou"} - Siapkan lingkungan Java. Versi JDK harus 1.8.0 atau lebih baru.
Langkah 1: Unggah paket JAR ES-Hadoop ke HDFS
Unduh paket ES-Hadoop yang kompatibel dengan versi kluster Elasticsearch.
Paket elasticsearch-hadoop-6.7.0.zip digunakan dalam contoh ini.
Masuk ke konsol EMR dan peroleh alamat IP dari node master kluster EMR. Kemudian, gunakan SSH untuk masuk ke instance Elastic Compute Service (ECS) yang ditunjukkan oleh alamat IP tersebut.
Untuk informasi lebih lanjut, lihat Masuk ke Kluster.
- Unggah paket elasticsearch-hadoop-6.7.0.zip ke node master di kluster EMR. Ekstrak paket tersebut untuk mendapatkan file elasticsearch-hadoop-6.7.0.jar.
- Buat direktori HDFS dan unggah file elasticsearch-hadoop-6.7.0.jar ke direktori tersebut.
hadoop fs -mkdir /tmp/hadoop-es hadoop fs -put elasticsearch-hadoop-6.7.0/dist/elasticsearch-hadoop-6.7.0.jar /tmp/hadoop-es
Langkah 2: Konfigurasikan dependensi POM
Buat proyek Java Maven dan tambahkan dependensi POM berikut ke file pom.xml proyek.
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>WriteToEsWithMR</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop-mr</artifactId>
<version>6.7.0</version>
</dependency>
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
</dependencies>Langkah 3: Kompilasi kode dan jalankan tugas MapReduce
- Kompilasi kode.Kode berikut membaca data dari file JSON di direktori /tmp/hadoop-es HDFS. Kode ini juga menulis setiap baris data dalam file JSON ini sebagai dokumen ke kluster Elasticsearch. Penulisan data diselesaikan oleh EsOutputFormat pada tahap map.
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.util.GenericOptionsParser; import org.elasticsearch.hadoop.mr.EsOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class WriteToEsWithMR extends Configured implements Tool { public static class EsMapper extends Mapper<Object, Text, NullWritable, Text> { private Text doc = new Text(); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { if (value.getLength() > 0) { doc.set(value); System.out.println(value); context.write(NullWritable.get(), doc); } } } public int run(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); conf.setBoolean("mapreduce.map.speculative", false); conf.setBoolean("mapreduce.reduce.speculative", false); conf.set("es.nodes", "es-cn-4591jumei000u****.elasticsearch.aliyuncs.com"); conf.set("es.port","9200"); conf.set("es.net.http.auth.user", "elastic"); conf.set("es.net.http.auth.pass", "xxxxxx"); conf.set("es.nodes.wan.only", "true"); conf.set("es.nodes.discovery","false"); conf.set("es.input.use.sliced.partitions","false"); conf.set("es.resource", "maptest/_doc"); conf.set("es.input.json", "true"); Job job = Job.getInstance(conf); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(EsOutputFormat.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); job.setJarByClass(WriteToEsWithMR.class); job.setMapperClass(EsMapper.class); FileInputFormat.setInputPaths(job, new Path(otherArgs[0])); return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int ret = ToolRunner.run(new WriteToEsWithMR(), args); System.exit(ret); } }Tabel 1. Parameter ES-Hadoop Parameter Nilai default Deskripsi es.nodes localhost Titik akhir yang digunakan untuk mengakses kluster Elasticsearch. Kami sarankan Anda menggunakan titik akhir internal. Anda dapat memperoleh titik akhir internal di halaman Informasi Dasar kluster Elasticsearch. Untuk informasi lebih lanjut, lihat Lihat informasi dasar kluster. es.port 9200 Nomor port yang digunakan untuk mengakses kluster Elasticsearch. es.net.http.auth.user elastic Nama pengguna yang digunakan untuk mengakses kluster Elasticsearch. CatatanJika Anda menggunakan akun elastic untuk mengakses kluster Elasticsearch dan mereset kata sandi akun tersebut, mungkin diperlukan waktu agar kata sandi baru berlaku. Selama periode ini, Anda tidak dapat menggunakan akun elastic untuk mengakses kluster. Oleh karena itu, kami sarankan Anda tidak menggunakan akun elastic untuk mengakses kluster Elasticsearch. Anda dapat masuk ke konsol Kibana dan membuat pengguna dengan peran yang diperlukan untuk mengakses kluster Elasticsearch. Untuk informasi lebih lanjut, lihat Gunakan mekanisme RBAC yang disediakan oleh Elasticsearch X-Pack untuk mengimplementasikan kontrol akses.
es.net.http.auth.pass / Kata sandi yang digunakan untuk mengakses kluster Elasticsearch. es.nodes.wan.only false Menentukan apakah akan mengaktifkan sniffing node ketika kluster Elasticsearch menggunakan alamat IP virtual untuk koneksi. Nilai valid: - true: menunjukkan bahwa sniffing node diaktifkan.
- false: menunjukkan bahwa sniffing node dinonaktifkan.
es.nodes.discovery true Menentukan apakah akan melarang mekanisme penemuan node. Nilai valid: - true: menunjukkan bahwa mekanisme penemuan node dilarang.
- false: menunjukkan bahwa mekanisme penemuan node tidak dilarang.
PentingJika Anda menggunakan Alibaba Cloud Elasticsearch, Anda harus menyetel parameter ini ke false.
es.input.use.sliced.partitions true Menentukan apakah akan menggunakan partisi. Nilai valid: true: menggunakan partisi. Dalam kasus ini, mungkin diperlukan lebih banyak waktu untuk fase pembacaan indeks sebelumnya. Waktu yang diperlukan untuk fase ini mungkin lebih lama daripada waktu yang diperlukan untuk kueri data. Untuk meningkatkan efisiensi kueri, kami sarankan Anda menyetel parameter ini ke false.
false: tidak menggunakan partisi.
es.index.auto.create true Menentukan apakah sistem membuat indeks di kluster Elasticsearch ketika Anda menggunakan ES-Hadoop untuk menulis data ke kluster. Nilai valid: - true: menunjukkan bahwa sistem membuat indeks di kluster Elasticsearch.
- false: menunjukkan bahwa sistem tidak membuat indeks di kluster Elasticsearch.
es.resource / Nama dan tipe indeks tempat operasi baca atau tulis data dilakukan. es.input.json false Menentukan apakah data input dalam format JSON. es.mapping.names / Pemetaan antara nama bidang dalam tabel dan nama bidang dalam indeks kluster Elasticsearch. es.read.metadata false Menentukan apakah akan menyertakan metadata dokumen seperti _id dalam hasil. Untuk menyertakan metadata dokumen, atur nilainya ke true. Untuk informasi lebih lanjut tentang item konfigurasi ES-Hadoop, lihat konfigurasi ES-Hadoop sumber terbuka.
- Kompres kode menjadi paket JAR dan unggah ke klien EMR, seperti node master di kluster EMR atau kluster gateway yang terkait dengan kluster EMR ini.
- Di klien EMR, jalankan perintah berikut untuk menjalankan tugas MapReduce:
hadoop jar es-mapreduce-1.0-SNAPSHOT.jar /tmp/hadoop-es/map.jsonCatatan Ganti es-mapreduce-1.0-SNAPSHOT.jar dengan nama file JAR yang diunggah.
Langkah 4: Verifikasi hasil
- Masuk ke konsol Kibana dari kluster Elasticsearch.Untuk informasi lebih lanjut, lihat Masuk ke Konsol Kibana.
- Di panel navigasi di sebelah kiri, klik Dev Tools.
- Di tab Console pada halaman yang muncul, jalankan perintah berikut untuk mengkueri data yang ditulis oleh tugas MapReduce:
GET maptest/_search { "query": { "match_all": {} } }Jika perintah berhasil dijalankan, hasil yang ditunjukkan pada gambar berikut dikembalikan.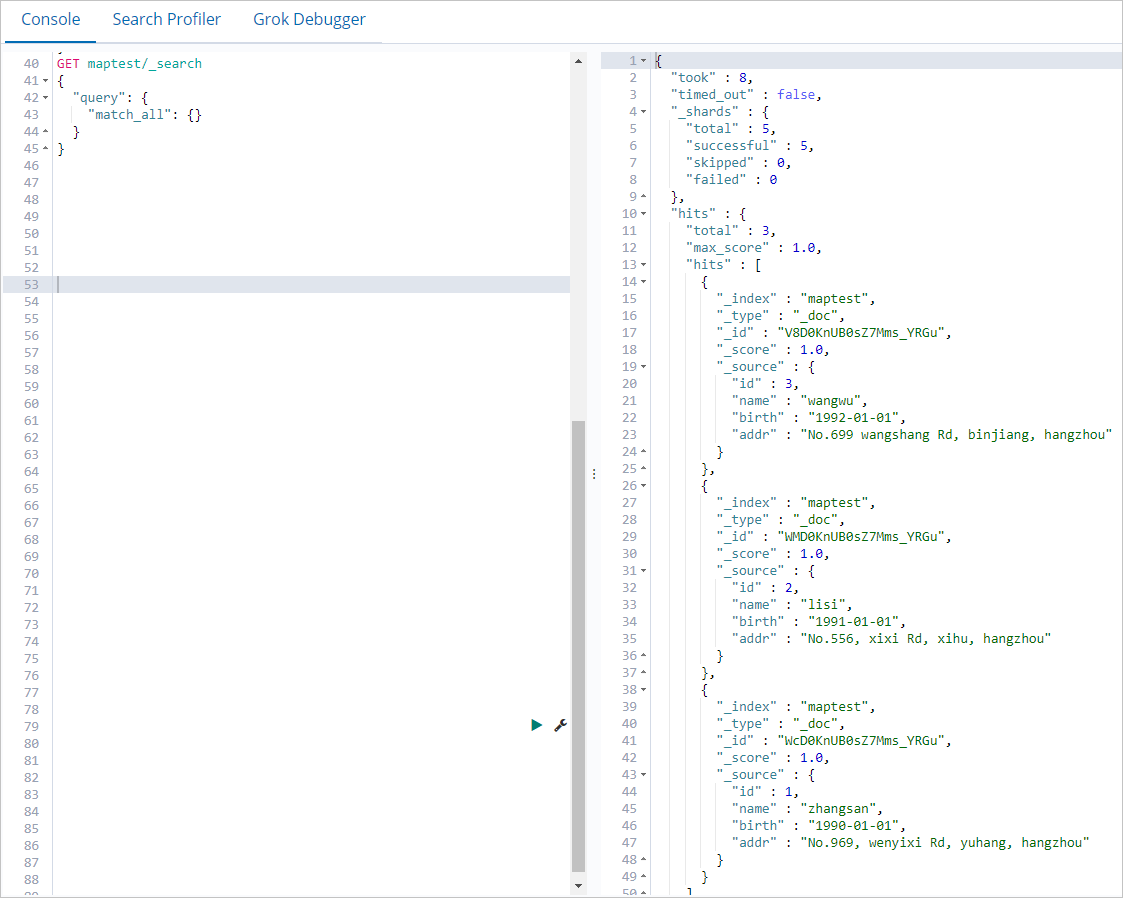
Ringkasan
Topik ini menjelaskan cara menggunakan ES-Hadoop untuk menulis data ke Elasticsearch dengan menjalankan tugas MapReduce di kluster EMR. Anda juga dapat menjalankan tugas MapReduce untuk membaca data dari Elasticsearch. Konfigurasi untuk operasi pembacaan data serupa dengan konfigurasi untuk operasi penulisan data. Untuk informasi lebih lanjut, lihat Membaca Data dari Elasticsearch dalam dokumentasi Elasticsearch sumber terbuka.