Elasticsearch-Hadoop (ES-Hadoop) adalah alat yang dikembangkan oleh Elasticsearch open source. Alat ini menghubungkan Elasticsearch dengan Apache Hadoop dan memungkinkan transmisi data di antara keduanya. ES-Hadoop menggabungkan kemampuan pencarian cepat dari Elasticsearch dan kemampuan pemrosesan batch dari Hadoop untuk mencapai pemrosesan data interaktif. Topik ini menjelaskan cara menggunakan ES-Hadoop untuk mengaktifkan Hive menulis data ke dan membaca data dari Alibaba Cloud Elasticsearch serta membantu Anda menggabungkan Elasticsearch dengan Hadoop untuk menerapkan analitik data yang lebih fleksibel.
Informasi latar belakang
Hadoop dapat menangani dataset besar. Namun, ketika digunakan untuk analitik interaktif, latensi tinggi terjadi. Elasticsearch memiliki keunggulan dibandingkan Hadoop dalam analitik interaktif karena dapat merespons permintaan, terutama permintaan ad hoc, dalam hitungan detik. ES-Hadoop menggabungkan keunggulan Hadoop dan Elasticsearch. ES-Hadoop memungkinkan Anda melakukan hanya beberapa modifikasi kode untuk memproses data yang disimpan di Elasticsearch, serta memberikan pengalaman query yang dipercepat.
ES-Hadoop menggunakan Elasticsearch sebagai sumber data untuk mesin pemrosesan data seperti MapReduce, Spark, dan Hive. ES-Hadoop juga menggunakan Elasticsearch sebagai penyimpanan dalam arsitektur pemisahan komputasi-penyimpanan. Elasticsearch bekerja mirip dengan sumber data lainnya dari MapReduce, Spark, dan Hive, tetapi dapat memilih dan menyaring data secara lebih cepat. Hal ini sangat penting bagi mesin analitik.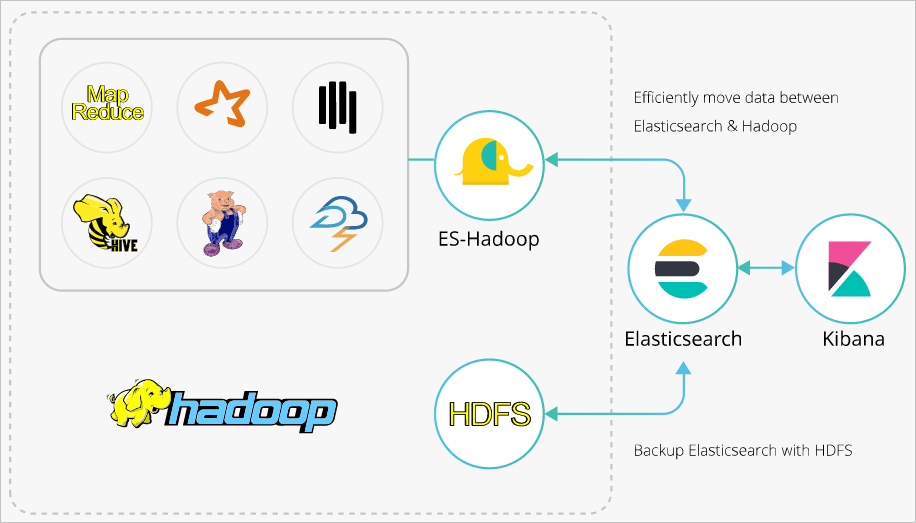
Untuk informasi lebih lanjut tentang konfigurasi lanjutan ES-Hadoop dan Hive, lihat dokumentasi Elasticsearch open source.
Prosedur
Buat kluster Elasticsearch Alibaba Cloud dan kluster E-MapReduce (EMR) di virtual private cloud (VPC) yang sama, nonaktifkan fitur Auto Indexing untuk kluster Elasticsearch, buat indeks di kluster Elasticsearch, dan konfigurasikan pemetaan untuk indeks tersebut.
Langkah 1: Unggah Paket JAR ES-Hadoop ke HDFS
Unduh paket ES-Hadoop yang kompatibel dengan versi kluster Elasticsearch, dan unggah paket ES-Hadoop ke direktori HDFS pada node master kluster EMR.
Langkah 2: Buat Tabel Eksternal Hive
Buat tabel eksternal Hive dan peta bidang dalam tabel dengan bidang dalam indeks kluster Elasticsearch.
Langkah 3: Gunakan Hive untuk Menulis Data ke Indeks
Gunakan HiveSQL untuk menulis data ke indeks kluster Elasticsearch.
Langkah 4: Gunakan Hive untuk Membaca Data dari Indeks
Gunakan HiveSQL untuk membaca data dari indeks kluster Elasticsearch.
Lakukan persiapan
Buat Kluster Elasticsearch Alibaba Cloud.
Dalam contoh ini, kluster Elasticsearch V6.7.0 dibuat. Untuk informasi lebih lanjut, lihat Buat Kluster Elasticsearch Alibaba Cloud.
Nonaktifkan Fitur Auto Indexing untuk Kluster, Buat Indeks di Kluster, dan Konfigurasikan Pemetaan untuk Indeks.
Jika Anda mengaktifkan fitur Auto Indexing untuk kluster, indeks yang dibuat secara otomatis oleh kluster Elasticsearch mungkin tidak sesuai dengan kebutuhan Anda. Misalnya, Anda mendefinisikan bidang age dengan tipe data INT dan mengaktifkan fitur Auto Indexing. Dalam hal ini, tipe data bidang age mungkin menjadi LONG di indeks. Oleh karena itu, kami sarankan Anda menonaktifkan fitur Auto Indexing. Indeks bernama company dibuat dalam contoh ini. Kode berikut menunjukkan indeks ini dan pemetaannya:
PUT company { "mappings": { "_doc": { "properties": { "id": { "type": "long" }, "name": { "type": "text", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } }, "birth": { "type": "text" }, "addr": { "type": "text" } } } }, "settings": { "index": { "number_of_shards": "5", "number_of_replicas": "1" } } }Buat Kluster EMR yang Berada di VPC yang Sama dengan Kluster Elasticsearch.
PentingSecara default, 0.0.0.0/0 ditentukan dalam daftar putih alamat IP privat kluster Elasticsearch. Anda dapat melihat konfigurasi whitelist pada halaman konfigurasi keamanan kluster. Jika pengaturan default tidak digunakan, Anda harus menambahkan alamat IP privat kluster EMR ke daftar putih.
Untuk informasi lebih lanjut tentang cara mendapatkan alamat IP privat kluster EMR, lihat Lihat Daftar Kluster dan Detail Kluster.
Untuk informasi lebih lanjut tentang cara mengonfigurasi daftar putih alamat IP privat untuk kluster Elasticsearch, lihat Konfigurasikan Daftar Putih Alamat IP Publik atau Privat untuk Kluster Elasticsearch. Alamat IP dalam daftar putih dapat digunakan untuk mengakses kluster Elasticsearch melalui VPC.
Langkah 1: Unggah paket JAR ES-Hadoop ke HDFS
Unduh Paket ES-Hadoop yang Kompatibel dengan Versi Kluster Elasticsearch.
Paket elasticsearch-hadoop-6.7.0.zip digunakan dalam contoh ini.
Masuk ke Konsol EMR dan peroleh alamat IP node master kluster EMR. Kemudian, gunakan SSH untuk masuk ke instance Elastic Compute Service (ECS) yang ditunjukkan oleh alamat IP tersebut.
Untuk informasi lebih lanjut, lihat Masuk ke Kluster.
Unggah paket elasticsearch-hadoop-6.7.0.zip ke node master, dan ekstrak paket tersebut untuk mendapatkan file elasticsearch-hadoop-hive-6.7.0.jar.
Buat Direktori HDFS dan Unggah File elasticsearch-hadoop-hive-6.7.0.jar ke Direktori Tersebut.
hadoop fs -mkdir /tmp/hadoop-es hadoop fs -put elasticsearch-hadoop-6.7.0/dist/elasticsearch-hadoop-hive-6.7.0.jar /tmp/hadoop-es
Langkah 2: Buat tabel eksternal Hive
Pada tab Data Platform di Konsol EMR, buat pekerjaan HiveSQL.
Untuk informasi lebih lanjut, lihat Konfigurasikan Pekerjaan Hive SQL.
Konfigurasikan Pekerjaan dan Buat Tabel Eksternal Hive.
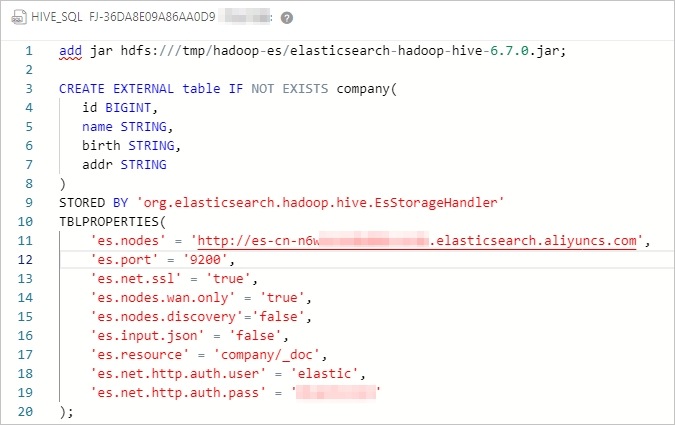
Kode berikut menunjukkan konfigurasi pekerjaan:
####Tambahkan file JAR, yang hanya valid untuk sesi saat ini.######## add jar hdfs:///tmp/hadoop-es/elasticsearch-hadoop-hive-6.7.0.jar; ####Buat tabel eksternal Hive dan peta tabel dengan indeks kluster Elasticsearch.#### CREATE EXTERNAL table IF NOT EXISTS company( id BIGINT, name STRING, birth STRING, addr STRING ) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES( 'es.nodes' = 'http://es-cn-mp91kzb8m0009****.elasticsearch.aliyuncs.com', 'es.port' = '9200', 'es.net.ssl' = 'true', 'es.nodes.wan.only' = 'true', 'es.nodes.discovery'='false', 'es.input.use.sliced.partitions'='false', 'es.input.json' = 'false', 'es.resource' = 'company/_doc', 'es.net.http.auth.user' = 'elastic', 'es.net.http.auth.pass' = 'xxxxxx' );Tabel 1. Parameter ES-Hadoop
Parameter
Nilai default
Deskripsi
es.nodes
localhost
Titik akhir yang digunakan untuk mengakses kluster Elasticsearch. Kami sarankan Anda menggunakan titik akhir internal. Anda dapat memperoleh titik akhir internal pada halaman Informasi Dasar kluster Elasticsearch. Untuk informasi lebih lanjut, lihat Lihat informasi dasar kluster.
es.port
9200
Nomor port yang digunakan untuk mengakses kluster Elasticsearch.
es.net.http.auth.user
elastic
Nama pengguna yang digunakan untuk mengakses kluster Elasticsearch.
CatatanJika Anda menggunakan akun elastic untuk mengakses kluster Elasticsearch Anda dan mengatur ulang kata sandi akun tersebut, mungkin diperlukan waktu agar kata sandi baru berlaku. Selama periode ini, Anda tidak dapat menggunakan akun elastic untuk mengakses kluster. Oleh karena itu, kami sarankan Anda tidak menggunakan akun elastic untuk mengakses kluster Elasticsearch. Anda dapat masuk ke konsol Kibana dan membuat pengguna dengan peran yang diperlukan untuk mengakses kluster Elasticsearch. Untuk informasi lebih lanjut, lihat Gunakan mekanisme RBAC yang disediakan oleh Elasticsearch X-Pack untuk menerapkan kontrol akses.
es.net.http.auth.pass
/
Kata sandi yang digunakan untuk mengakses kluster Elasticsearch.
es.nodes.wan.only
false
Menentukan apakah akan mengaktifkan sniffing node ketika kluster Elasticsearch menggunakan alamat IP virtual untuk koneksi. Nilai valid:
true: mengaktifkan sniffing node.
false: menonaktifkan sniffing node.
es.nodes.discovery
true
Menentukan apakah akan mengaktifkan mekanisme penemuan node. Nilai valid:
true: mengaktifkan mekanisme penemuan node.
false: menonaktifkan mekanisme penemuan node.
PentingJika Anda menggunakan Alibaba Cloud Elasticsearch, Anda harus mengatur parameter ini ke false.
es.input.use.sliced.partitions
true
Menentukan apakah akan menggunakan partisi. Nilai valid:
true: menggunakan partisi. Dalam hal ini, mungkin diperlukan lebih banyak waktu untuk fase pembacaan indeks sebelumnya. Waktu yang diperlukan untuk fase ini mungkin lebih lama daripada waktu yang diperlukan untuk kueri data. Untuk meningkatkan efisiensi kueri, kami sarankan Anda mengatur parameter ini ke false.
false: tidak menggunakan partisi.
es.index.auto.create
true
Menentukan apakah sistem membuat indeks di kluster Elasticsearch ketika Anda menggunakan ES-Hadoop untuk menulis data ke kluster. Nilai valid:
true: Sistem membuat indeks di kluster Elasticsearch.
false: Sistem tidak membuat indeks di kluster Elasticsearch.
es.resource
/
Nama dan jenis indeks tempat operasi baca atau tulis data dilakukan.
es.mapping.names
/
Pemetaan antara nama bidang dalam tabel dan nama bidang dalam indeks kluster Elasticsearch.
es.read.metadata
false
Menentukan apakah akan menyertakan metadata dokumen seperti _id dalam hasil. Untuk menyertakan metadata dokumen, atur nilainya ke true.
Untuk informasi lebih lanjut tentang item konfigurasi ES-Hadoop, lihat Konfigurasi ES-Hadoop Open Source.
Simpan dan Jalankan Pekerjaan.
Jika pekerjaan berhasil dijalankan, hasil yang ditunjukkan pada gambar berikut dikembalikan.

Langkah 3: Gunakan Hive untuk menulis data ke indeks
Buat pekerjaan penulisan data HiveSQL.
Kode berikut menunjukkan konfigurasi pekerjaan:
add jar hdfs:///tmp/hadoop-es/elasticsearch-hadoop-hive-6.7.0.jar; INSERT INTO TABLE company VALUES (1, "zhangsan", "1990-01-01","No.969, wenyixi Rd, yuhang, hangzhou"); INSERT INTO TABLE company VALUES (2, "lisi", "1991-01-01", "No.556, xixi Rd, xihu, hangzhou"); INSERT INTO TABLE company VALUES (3, "wangwu", "1992-01-01", "No.699 wangshang Rd, binjiang, hangzhou");Simpan dan Jalankan Pekerjaan.

Jika pekerjaan berhasil dijalankan, masuk ke Konsol Kibana Kluster Elasticsearch dan kueri data dalam indeks company.
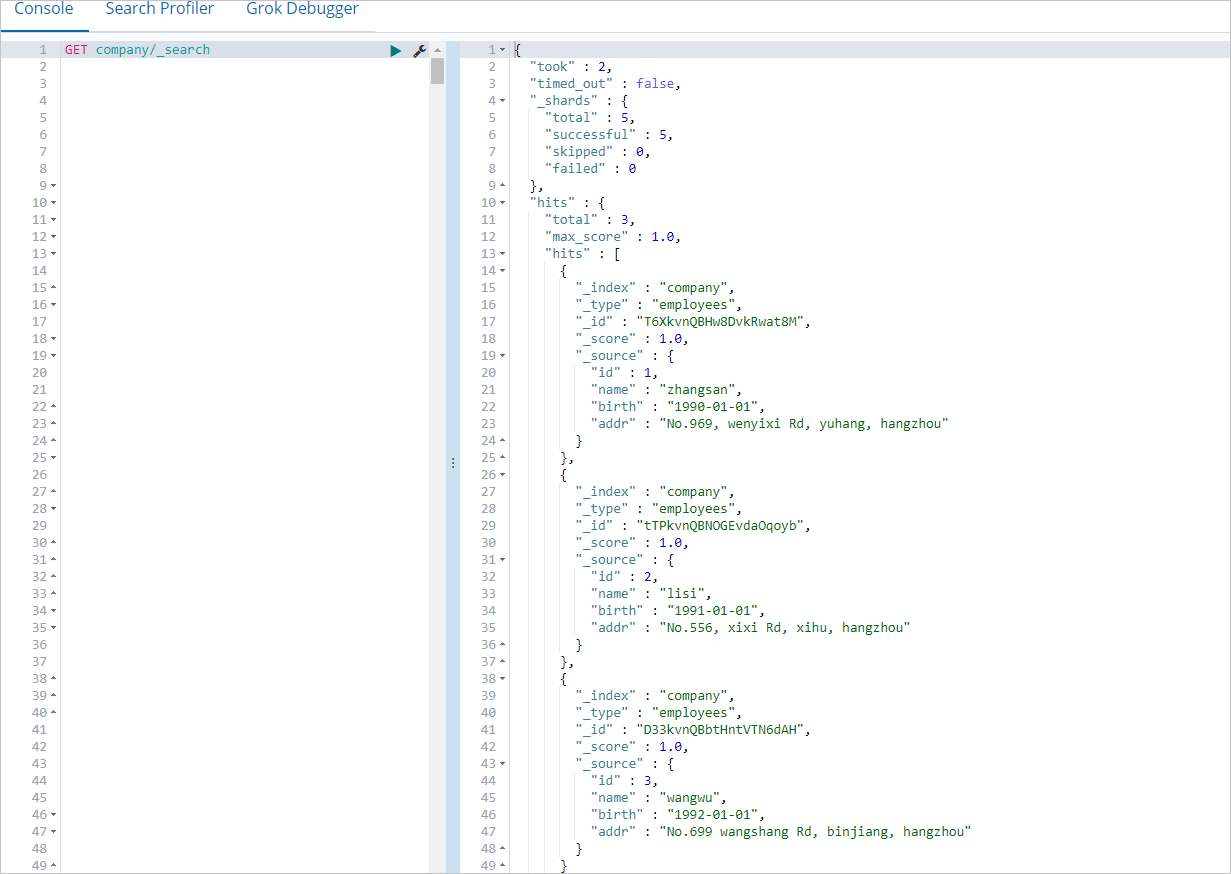
Untuk informasi lebih lanjut tentang cara masuk ke Konsol Kibana, lihat Masuk ke Konsol Kibana. Anda dapat menjalankan perintah berikut untuk mengkueri data dalam indeks company:
GET company/_searchJika perintah berhasil dijalankan, hasil yang ditunjukkan pada gambar berikut dikembalikan.
Langkah 4: Gunakan Hive untuk membaca data dari indeks
Buat Pekerjaan Pembacaan Data HiveSQL.
Kode berikut menunjukkan konfigurasi pekerjaan:
add jar hdfs:///tmp/hadoop-es/elasticsearch-hadoop-hive-6.7.0.jar; select * from company;Simpan dan Jalankan Pekerjaan.

FAQ
T: Apa yang harus saya lakukan jika pesan kesalahan berikut dilaporkan ketika Hive membaca data dari dan menulis data ke Elasticsearch?
FAILED: Execution Error, return code -101 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask. Could not initialize class org.elasticsearch.hadoop.rest.commonshttp.CommonsHttpTransport.
A: Pesan kesalahan dilaporkan karena file commons-httpclient-3.1.jar tidak ada untuk komponen Hive di kluster EMR V5.6.0 Anda. Untuk menyelesaikan masalah ini, tambahkan file tersebut secara manual ke direktori lib Hive. Untuk informasi lebih lanjut, lihat commons-httpclient-3.1.