Apache Spark adalah kerangka kerja tujuan umum untuk komputasi data besar yang menawarkan semua keunggulan Hadoop MapReduce. Perbedaannya terletak pada penyimpanan data di memori, memungkinkan iterasi cepat pada dataset besar. Dengan pendekatan ini, data dapat langsung dibaca dari cache alih-alih disk, sehingga memberikan kinerja pemrosesan lebih tinggi daripada MapReduce. Topik ini menjelaskan cara mengaktifkan Spark untuk menulis dan membaca data dari Alibaba Cloud Elasticsearch menggunakan Elasticsearch-Hadoop (ES-Hadoop).
Persiapan
- Buat kluster Alibaba Cloud Elasticsearch dan aktifkan fitur Auto Indexing.Untuk detail lebih lanjut, lihat Buat Kluster Alibaba Cloud Elasticsearch dan Akses dan Konfigurasikan Kluster Elasticsearch. Dalam topik ini, kluster Elasticsearch V6.7.0 dibuat.Penting Dalam lingkungan produksi, disarankan untuk menonaktifkan fitur Auto Indexing. Anda harus membuat indeks dan mengonfigurasi pemetaan terlebih dahulu. Kluster Elasticsearch dalam topik ini hanya digunakan untuk pengujian, sehingga fitur Auto Indexing diaktifkan.
Buat kluster E-MapReduce (EMR) di virtual private cloud (VPC) tempat kluster Elasticsearch berada.
Konfigurasi kluster EMR:
Versi EMR: Pilih EMR-3.29.0.
Layanan yang Diperlukan: Spark (2.4.5) adalah salah satu layanan yang diperlukan. Pengaturan default dipertahankan untuk layanan lainnya.
Untuk informasi lebih lanjut, lihat Buat Kluster.
PentingSecara default, 0.0.0.0/0 ditentukan dalam daftar putih alamat IP privat kluster Elasticsearch. Anda dapat melihat konfigurasi whitelist pada halaman konfigurasi keamanan kluster. Jika pengaturan default tidak digunakan, tambahkan alamat IP privat kluster EMR ke daftar putih.
Untuk informasi lebih lanjut tentang cara mendapatkan alamat IP privat kluster EMR, lihat Lihat Daftar Kluster dan Detail Kluster.
Untuk informasi lebih lanjut tentang cara mengonfigurasi daftar putih alamat IP privat untuk kluster Elasticsearch, lihat Konfigurasikan Daftar Putih Alamat IP Publik atau Privat untuk Kluster Elasticsearch. Alamat IP dalam daftar putih dapat digunakan untuk mengakses kluster Elasticsearch melalui VPC.
Persiapkan lingkungan Java. Versi JDK harus 1.8.0 atau lebih baru.
Kompilasi dan jalankan pekerjaan Spark
Persiapkan data uji.
Masuk ke Konsol E-MapReduce dan peroleh alamat IP node master kluster EMR. Kemudian, gunakan SSH untuk masuk ke instance Elastic Compute Service (ECS) yang ditunjukkan oleh alamat IP tersebut.
Untuk informasi lebih lanjut, lihat Masuk ke Kluster.
Tulis data uji ke file.
Dalam contoh ini, data uji berikut dalam format JSON ditulis ke file http_log.txt:
{"id": 1, "name": "zhangsan", "birth": "1990-01-01", "addr": "No.969, wenyixi Rd, yuhang, hangzhou"} {"id": 2, "name": "lisi", "birth": "1991-01-01", "addr": "No.556, xixi Rd, xihu, hangzhou"} {"id": 3, "name": "wangwu", "birth": "1992-01-01", "addr": "No.699 wangshang Rd, binjiang, hangzhou"}Jalankan perintah berikut untuk mengunggah file ke direktori /tmp/hadoop-es pada node master kluster EMR:
hadoop fs -put http_log.txt /tmp/hadoop-es
Tambahkan dependensi POM.
Buat proyek Java Maven dan tambahkan dependensi POM berikut ke file pom.xml proyek:
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.12</artifactId> <version>2.4.5</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.5</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch-spark-20_2.11</artifactId> <version>6.7.0</version> </dependency> </dependencies>PentingPastikan versi dependensi POM konsisten dengan versi layanan Alibaba Cloud terkait. Misalnya, versi elasticsearch-spark-20_2.11 konsisten dengan versi kluster Elasticsearch Anda, dan versi spark-core_2.12 konsisten dengan versi HDFS.
Kompilasi kode.
Tulis data
Kode sampel berikut digunakan untuk menulis data uji ke indeks perusahaan kluster Elasticsearch:
import java.util.Map; import java.util.concurrent.atomic.AtomicInteger; import org.apache.spark.SparkConf; import org.apache.spark.SparkContext; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.function.Function; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.elasticsearch.spark.rdd.api.java.JavaEsSpark; import org.spark_project.guava.collect.ImmutableMap; public class SparkWriteEs { public static void main(String[] args) { SparkConf conf = new SparkConf(); conf.setAppName("Es-write"); conf.set("es.nodes", "es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com"); conf.set("es.net.http.auth.user", "elastic"); conf.set("es.net.http.auth.pass", "xxxxxx"); conf.set("es.nodes.wan.only", "true"); conf.set("es.nodes.discovery","false"); conf.set("es.input.use.sliced.partitions","false"); SparkSession ss = new SparkSession(new SparkContext(conf)); final AtomicInteger employeesNo = new AtomicInteger(0); //Ganti /tmp/hadoop-es/http_log.txt dengan path sebenarnya dari data uji Anda. JavaRDD<Map<Object, ?>> javaRDD = ss.read().text("/tmp/hadoop-es/http_log.txt") .javaRDD().map((Function<Row, Map<Object, ?>>) row -> ImmutableMap.of("employees" employeesNo.getAndAdd(1), row.mkString())); JavaEsSpark.saveToEs(javaRDD, "company/_doc"); } }Baca data
Kode sampel berikut digunakan untuk membaca dan menampilkan data uji yang ditulis ke kluster Elasticsearch:
import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaSparkContext; import org.elasticsearch.spark.rdd.api.java.JavaEsSpark; import java.util.Map; public class ReadES { public static void main(String[] args) { SparkConf conf = new SparkConf().setAppName("readEs").setMaster("local[*]") .set("es.nodes", "es-cn-n6w1o1x0w001c****.elasticsearch.aliyuncs.com") .set("es.port", "9200") .set("es.net.http.auth.user", "elastic") .set("es.net.http.auth.pass", "xxxxxx") .set("es.nodes.wan.only", "true") .set("es.nodes.discovery","false") .set("es.input.use.sliced.partitions","false") .set("es.resource", "company/_doc") .set("es.scroll.size","500"); JavaSparkContext sc = new JavaSparkContext(conf); JavaPairRDD<String, Map<String, Object>> rdd = JavaEsSpark.esRDD(sc); for ( Map<String, Object> item : rdd.values().collect()) { System.out.println(item); } sc.stop(); } }
Tabel 1. Parameter
Parameter
Nilai default
Deskripsi
es.nodes
localhost
Titik akhir yang digunakan untuk mengakses kluster Elasticsearch. Kami sarankan Anda menggunakan titik akhir internal. Anda dapat memperoleh titik akhir internal pada halaman Informasi Dasar kluster Elasticsearch. Untuk informasi lebih lanjut, lihat Lihat informasi dasar kluster.
es.port
9200
Nomor port yang digunakan untuk mengakses kluster Elasticsearch.
es.net.http.auth.user
elastic
Nama pengguna yang digunakan untuk mengakses kluster Elasticsearch.
CatatanJika Anda menggunakan akun elastic untuk mengakses kluster Elasticsearch Anda dan mereset kata sandi akun tersebut, mungkin memerlukan waktu bagi kata sandi baru untuk berlaku. Selama periode ini, Anda tidak dapat menggunakan akun elastic untuk mengakses kluster. Oleh karena itu, kami sarankan Anda tidak menggunakan akun elastic untuk mengakses kluster Elasticsearch. Anda dapat masuk ke Konsol Kibana dan membuat pengguna dengan peran yang diperlukan untuk mengakses kluster Elasticsearch. Untuk informasi lebih lanjut, lihat Gunakan mekanisme RBAC yang disediakan oleh Elasticsearch X-Pack untuk mengimplementasikan kontrol akses.
es.net.http.auth.pass
/
Kata sandi yang sesuai dengan nama pengguna elastic. Kata sandi ditentukan saat Anda membuat kluster Elasticsearch. Jika Anda lupa kata sandi, Anda dapat meresetnya. Untuk informasi lebih lanjut, lihat Reset kata sandi akses untuk kluster Elasticsearch.
es.nodes.wan.only
false
Menentukan apakah akan mengaktifkan sniffing node ketika kluster Elasticsearch menggunakan alamat IP virtual untuk koneksi. Nilai valid:
true: menunjukkan bahwa sniffing node diaktifkan.
false: menunjukkan bahwa sniffing node dinonaktifkan.
es.nodes.discovery
true
Menentukan apakah akan melarang mekanisme penemuan node. Nilai valid:
true: menunjukkan bahwa mekanisme penemuan node dilarang.
false: menunjukkan bahwa mekanisme penemuan node tidak dilarang.
PentingJika Anda menggunakan Alibaba Cloud Elasticsearch, Anda harus mengatur parameter ini ke false.
es.input.use.sliced.partitions
true
Menentukan apakah akan menggunakan partisi. Nilai valid:
true: menggunakan partisi. Dalam hal ini, mungkin diperlukan lebih banyak waktu untuk fase pembacaan indeks awal. Waktu yang diperlukan untuk fase ini mungkin lebih lama daripada waktu yang diperlukan untuk kueri data. Untuk meningkatkan efisiensi kueri, kami sarankan Anda mengatur parameter ini ke false.
false: tidak menggunakan partisi.
es.index.auto.create
true
Menentukan apakah sistem membuat indeks di kluster Elasticsearch ketika Anda menggunakan ES-Hadoop untuk menulis data ke kluster. Nilai valid:
true: menunjukkan bahwa sistem membuat indeks di kluster Elasticsearch.
false: menunjukkan bahwa sistem tidak membuat indeks di kluster Elasticsearch.
es.resource
/
Nama dan tipe indeks tempat operasi baca atau tulis data dilakukan.
es.mapping.names
/
Pemetaan antara nama bidang dalam tabel dan nama bidang dalam indeks kluster Elasticsearch.
Untuk informasi lebih lanjut tentang item konfigurasi ES-Hadoop, lihat konfigurasi ES-Hadoop open source.
- Kompres kode menjadi paket JAR dan unggah ke klien EMR, seperti node master di kluster EMR atau kluster gateway yang terkait dengan kluster EMR ini.
Di klien EMR, jalankan pekerjaan Spark berikut:
Tulis data
cd /usr/lib/spark-current ./bin/spark-submit --master yarn --executor-cores 1 --class "SparkWriteEs" /usr/local/spark_es.jarPentingGanti /usr/local/spark_es.jar dengan path tempat Anda telah mengunggah paket JAR Anda.
Baca data
cd /usr/lib/spark-current ./bin/spark-submit --master yarn --executor-cores 1 --class "ReadES" /usr/local/spark_es.jarSetelah data dibaca, hasil yang ditunjukkan pada gambar berikut dikembalikan.
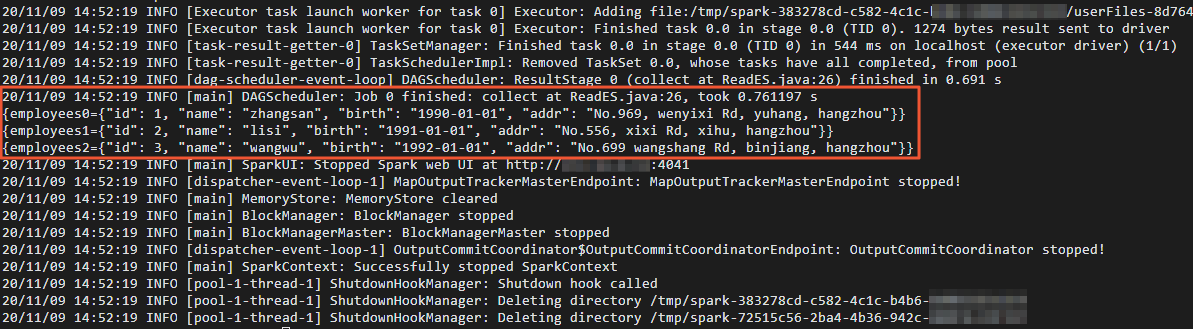
Verifikasi hasil
- Masuk ke konsol Kibana kluster Elasticsearch.Untuk informasi lebih lanjut, lihat Masuk ke Konsol Kibana.
- Di panel navigasi sisi kiri, klik Dev Tools.
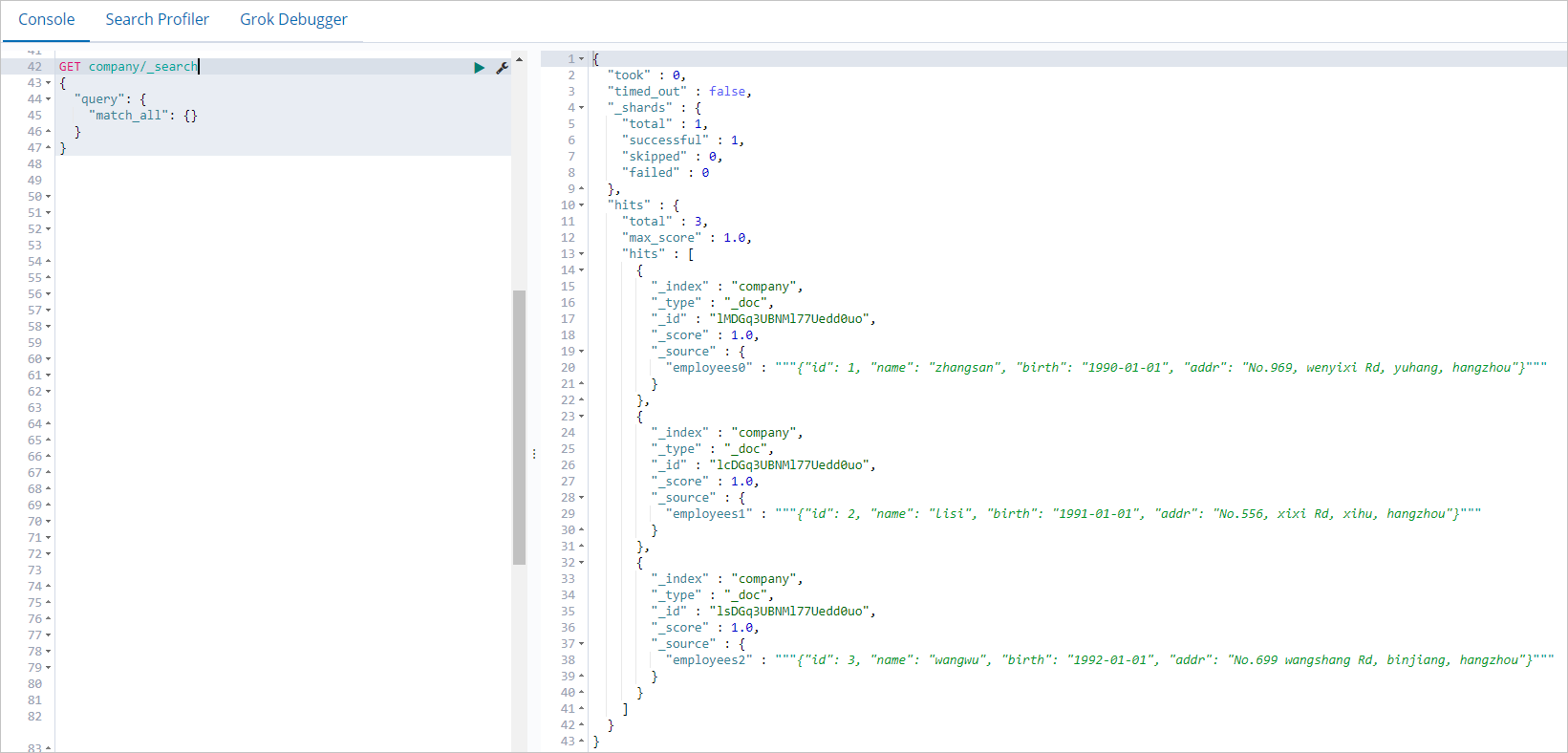
Di tab Console halaman yang muncul, jalankan perintah berikut untuk menanyakan data yang ditulis oleh pekerjaan Spark:
GET company/_search { "query": { "match_all": {} } }Jika perintah berhasil dijalankan, hasil yang ditunjukkan pada gambar berikut dikembalikan.
Ringkasan
Topik ini menjelaskan cara menggunakan ES-Hadoop untuk menulis dan membaca data di Alibaba Cloud Elasticsearch dengan menjalankan pekerjaan Spark di kluster EMR. Setelah ES-Hadoop diintegrasikan dengan Spark, ES-Hadoop mendukung dataset Spark, resilient distributed datasets (RDD), Spark Streaming, Scala, dan Spark SQL. Anda dapat mengonfigurasi ES-Hadoop sesuai kebutuhan. Untuk informasi lebih lanjut, lihat Dukungan Apache Spark.