Jika Anda ingin mencari dan menganalisis data produksi di database ApsaraDB RDS for MySQL menggunakan Alibaba Cloud Elasticsearch, Anda dapat memanfaatkan Data Transmission Service (DTS) untuk menyinkronkan data tersebut ke kluster Elasticsearch secara real time. Sinkronisasi ini diimplementasikan melalui tugas sinkronisasi real time dan cocok untuk skenario yang memerlukan kinerja tinggi dalam sinkronisasi real time. Topik ini menjelaskan cara membuat tugas sinkronisasi real time guna menyinkronkan data dari database ApsaraDB RDS for MySQL ke kluster Alibaba Cloud Elasticsearch secara real time, serta cara memverifikasi hasil sinkronisasi data penuh dan data inkremental.
Informasi latar belakang
DTS adalah layanan transmisi data yang mengintegrasikan migrasi data, langganan data, dan sinkronisasi data real time. Untuk informasi selengkapnya, lihat DTS. DTS mendukung sinkronisasi perubahan data yang dihasilkan oleh operasi INSERT, DELETE, dan UPDATE. Informasi mengenai versi sumber data yang dapat disinkronkan oleh DTS tersedia di Ikhtisar skenario sinkronisasi data.
Anda dapat menggunakan DTS untuk menyinkronkan data penuh atau inkremental dari MySQL ke Elasticsearch. Solusi ini cocok untuk skenario yang memerlukan kinerja tinggi dalam sinkronisasi real time dari database relasional atau ketika Anda perlu menyinkronkan data penuh atau inkremental dari database relasional ke kluster Alibaba Cloud Elasticsearch.
Perhatian
DTS tidak menyinkronkan perubahan data yang dihasilkan oleh operasi DDL. Jika operasi DDL dilakukan pada tabel di database sumber selama sinkronisasi data, Anda harus melakukan langkah-langkah berikut: hapus tabel tersebut dari tugas sinkronisasi data, hapus indeks terkait dari kluster Elasticsearch, lalu tambahkan kembali tabel tersebut ke tugas sinkronisasi data. Untuk informasi selengkapnya, lihat Hapus objek dari tugas sinkronisasi data dan Tambahkan objek ke tugas sinkronisasi data.
Jika Anda ingin menambahkan kolom ke tabel sumber, ubah pemetaan indeks yang sesuai dengan tabel tersebut terlebih dahulu. Setelah itu, lakukan operasi DDL terkait pada tabel sumber, jeda tugas sinkronisasi data, lalu mulai kembali tugas tersebut.
DTS menggunakan sumber daya baca dan tulis dari sumber dan tujuan selama sinkronisasi data penuh awal. Hal ini dapat meningkatkan beban pada sumber dan tujuan. Jika kinerja sumber atau tujuan tidak optimal, spesifikasinya rendah, atau volume datanya besar, sumber atau tujuan berisiko menjadi tidak tersedia. Misalnya, DTS menggunakan banyak sumber daya baca dan tulis dalam kasus berikut: banyak query SQL lambat dieksekusi pada sumber, satu atau beberapa tabel tidak memiliki primary key, atau terjadi deadlock pada tujuan. Untuk mencegah masalah ini, evaluasi dampak sinkronisasi data terhadap kinerja sumber dan tujuan sebelum memulai proses. Disarankan agar sinkronisasi data dilakukan selama jam sepi, misalnya saat utilisasi CPU sumber dan tujuan kurang dari 30%.
Jika sinkronisasi data penuh dilakukan selama jam sibuk, proses tersebut berpotensi gagal. Dalam kasus ini, restart tugas sinkronisasi.
Jika sinkronisasi data inkremental dilakukan selama jam sibuk, latensi sinkronisasi data mungkin terjadi.
ApsaraDB RDS for MySQL dan Elasticsearch mendukung tipe data yang berbeda. Selama sinkronisasi skema awal, DTS membuat pemetaan antara bidang sumber dan bidang tujuan berdasarkan tipe data yang didukung oleh tujuan. Untuk informasi selengkapnya, lihat Pemetaan tipe data untuk sinkronisasi skema.
Proses
Lakukan persiapan: Tambahkan data yang akan disinkronkan ke database ApsaraDB RDS for MySQL sumber, buat kluster Alibaba Cloud Elasticsearch, dan aktifkan fitur Auto Indexing pada kluster Elasticsearch tersebut.
Buat dan jalankan tugas sinkronisasi data: Buat dan jalankan tugas sinkronisasi data di Konsol DTS.
Verifikasi hasil sinkronisasi data: Login ke Konsol Kibana kluster Elasticsearch untuk memverifikasi hasil sinkronisasi data penuh. Kemudian, tambahkan data ke database ApsaraDB RDS for MySQL sumber dan login kembali ke Konsol Kibana kluster Elasticsearch untuk memverifikasi hasil sinkronisasi data inkremental.
Prosedur
Langkah 1: Lakukan persiapan
Pada contoh ini, digunakan instans ApsaraDB RDS yang menjalankan MySQL 8.0 dan kluster Alibaba Cloud Elasticsearch V7.10.
Siapkan database sumber dan data yang akan disinkronkan
Buat instans ApsaraDB RDS yang menjalankan MySQL 8.0. Untuk informasi selengkapnya, lihat Buat instans ApsaraDB RDS for MySQL.
Buat akun database dan database bernama
test_mysql. Untuk informasi selengkapnya, lihat Buat database dan akun.Di database
test_mysql, buat tabeles_testdan masukkan data. Pernyataan pembuatan tabel dan datanya adalah sebagai berikut:-- create table CREATE TABLE `es_test` ( `id` bigint(32) NOT NULL, `name` varchar(32) NULL, `age` bigint(32) NULL, `hobby` varchar(32) NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8; -- insert data INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (1,'user1',22,'music'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (2,'user2',23,'sport'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (3,'user3',43,'game'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (4,'user4',24,'run'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (5,'user5',42,'basketball');
Siapkan kluster Elasticsearch tujuan
Buat kluster Alibaba Cloud Elasticsearch V7.10. Untuk informasi selengkapnya, lihat Buat kluster Alibaba Cloud Elasticsearch.
Aktifkan fitur Auto Indexing untuk kluster Elasticsearch tersebut. Untuk informasi selengkapnya, lihat Konfigurasi file YML.
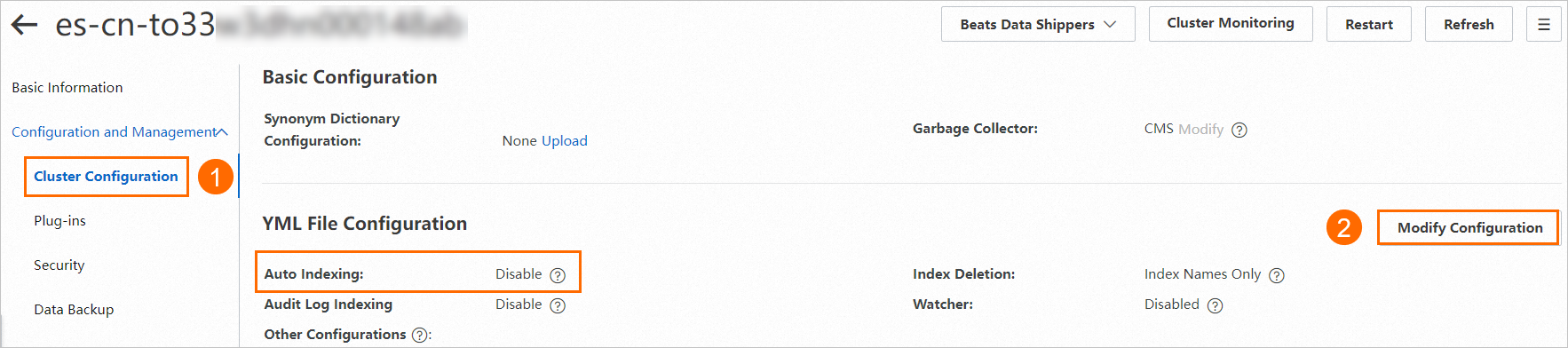
Langkah 2: Buat dan jalankan tugas sinkronisasi data
Buka halaman Sinkronisasi Data di Konsol DTS baru.
Klik Create Task.
Pada halaman yang muncul, buat dan konfigurasikan tugas sinkronisasi data sesuai petunjuk.
CatatanUntuk informasi tentang parameter yang terlibat dalam langkah-langkah berikut, lihat Sinkronisasi data dari instans ApsaraDB RDS for MySQL ke kluster Elasticsearch.
Konfigurasikan sumber dan tujuan. Di bagian bawah halaman, klik Test Connectivity and Proceed.
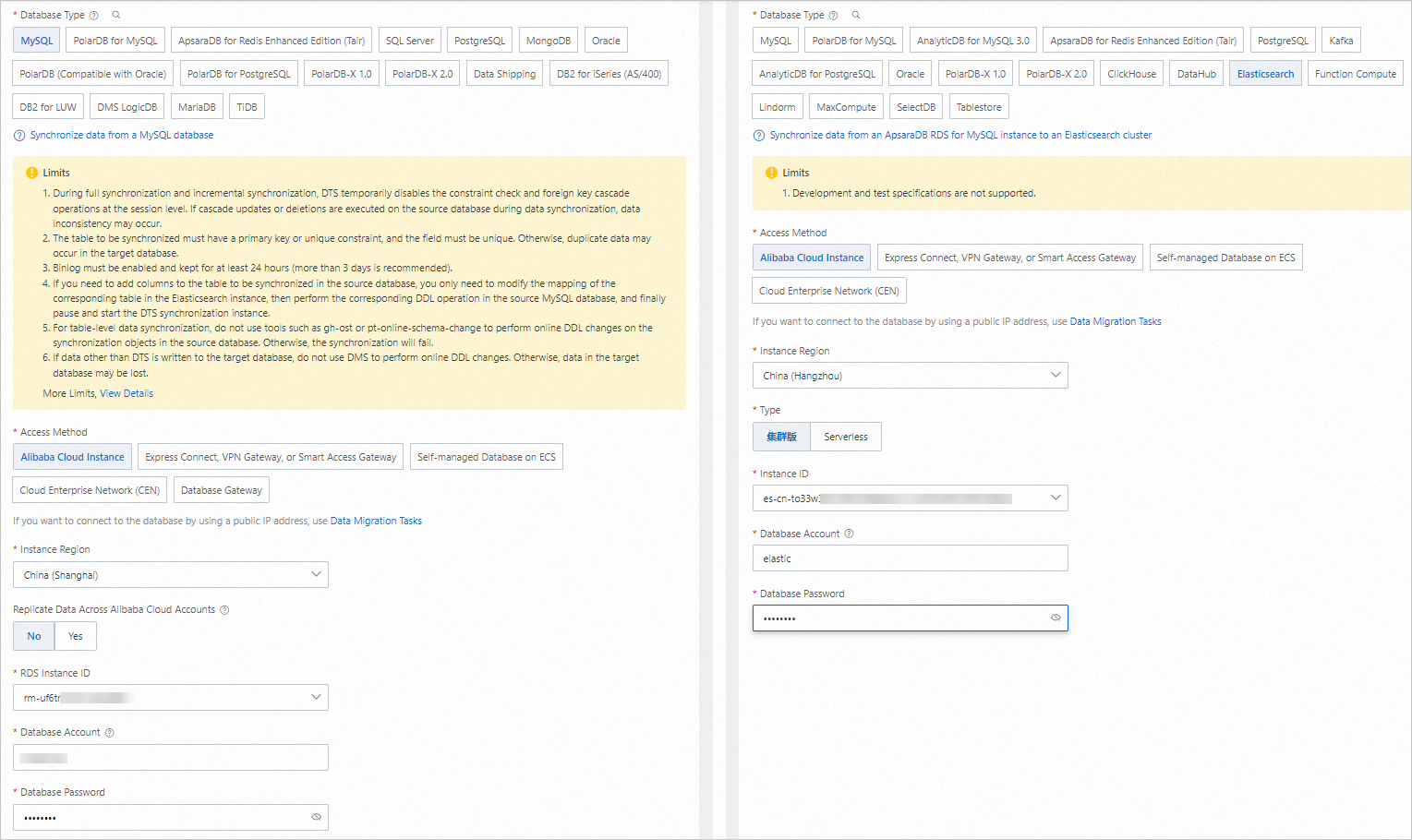
Konfigurasikan objek yang akan disinkronkan datanya.
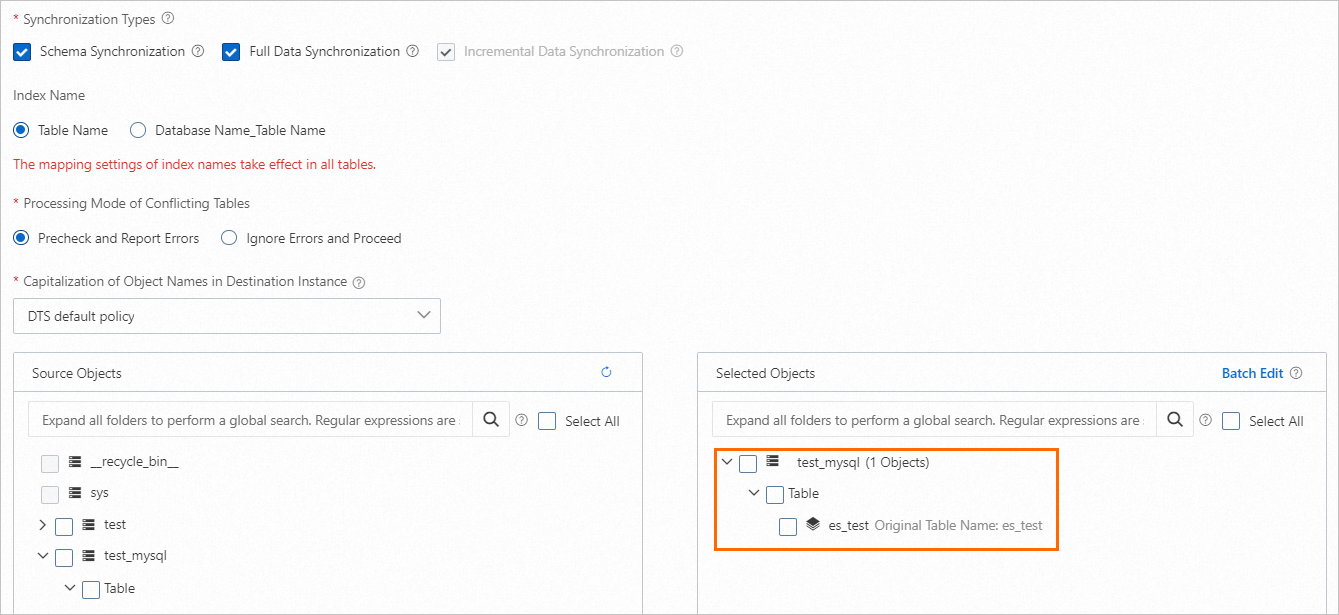
Konfigurasikan pengaturan advanced. Pada contoh ini, pengaturan advanced default digunakan.
Pada sublangkah Data Verification, pilih Apply _routing Policy to No Tables.
CatatanJika kluster Elasticsearch tujuan adalah versi V7.X, Anda harus memilih Apply _routing Policy to No Tables.
Setelah konfigurasi selesai, simpan tugas sinkronisasi data, lakukan pre-check pada tugas tersebut, dan beli instans DTS untuk memulai tugas sinkronisasi data.
Setelah instans DTS dibeli, tugas sinkronisasi data mulai berjalan. Anda dapat melihat progres sinkronisasi data di halaman Sinkronisasi Data. Setelah data penuh disinkronkan, data tersebut akan tersedia di kluster Elasticsearch.

Langkah 3 (Opsional): Verifikasi hasil sinkronisasi
Login ke Konsol Kibana kluster Elasticsearch.
Untuk informasi selengkapnya, lihat Login ke Konsol Kibana.
Di pojok kiri atas halaman Kibana, pilih
 > Management > Dev Tools, lalu jalankan perintah berikut di Console.
> Management > Dev Tools, lalu jalankan perintah berikut di Console.Verifikasi hasil sinkronisasi data penuh.
Jalankan perintah berikut:
GET /es_test/_searchJika perintah berhasil dijalankan, hasil berikut akan dikembalikan:
{ "took" : 10, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 5, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "es_test", "_type" : "es_test", "_id" : "3", "_score" : 1.0, "_source" : { "id" : 3, "name" : "user3", "age" : 43, "hobby" : "game" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "5", "_score" : 1.0, "_source" : { "id" : 5, "name" : "user5", "age" : 42, "hobby" : "basketball" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "4", "_score" : 1.0, "_source" : { "id" : 4, "name" : "user4", "age" : 24, "hobby" : "run" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "2", "_score" : 1.0, "_source" : { "id" : 2, "name" : "user2", "age" : 23, "hobby" : "sport" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "1", "_score" : 1.0, "_source" : { "id" : 1, "name" : "user1", "age" : 22, "hobby" : "music" } } ] } }Verifikasi hasil sinkronisasi data inkremental.
Jalankan pernyataan berikut untuk memasukkan catatan data ke tabel sumber:
INSERT INTO `test_mysql`.`es_test` (`id`,`name`,`age`,`hobby`) VALUES (6,'user6',30,'dance');Setelah sinkronisasi data inkremental selesai, jalankan kembali perintah
GET /es_test/_searchuntuk memeriksa hasilnya.Jika perintah berhasil dijalankan, hasil berikut akan dikembalikan:
{ "took" : 541, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "es_test", "_type" : "es_test", "_id" : "3", "_score" : 1.0, "_source" : { "id" : 3, "name" : "user3", "age" : 43, "hobby" : "game" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "5", "_score" : 1.0, "_source" : { "id" : 5, "name" : "user5", "age" : 42, "hobby" : "basketball" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "4", "_score" : 1.0, "_source" : { "id" : 4, "name" : "user4", "age" : 24, "hobby" : "run" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "2", "_score" : 1.0, "_source" : { "id" : 2, "name" : "user2", "age" : 23, "hobby" : "sport" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "6", "_score" : 1.0, "_source" : { "name" : "user6", "id" : 6, "age" : 30, "hobby" : "dance" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "1", "_score" : 1.0, "_source" : { "id" : 1, "name" : "user1", "age" : 22, "hobby" : "music" } } ] } }