Beban tidak seimbang pada kluster Alibaba Cloud Elasticsearch (ES) dapat terjadi karena berbagai alasan, seperti pengaturan shard yang tidak sesuai, ukuran segmen yang tidak merata, tidak dipisahkannya data panas dan dingin, serta penggunaan koneksi persisten pada instance Server Load Balancer (SLB) atau arsitektur multi-zona. Topik ini menjelaskan analisis dan solusi untuk mengatasi beban tidak seimbang pada kluster Elasticsearch.
Deskripsi masalah
Penggunaan disk serupa di antara node, tetapi nilai metrik utilisasi CPU atau load_1m menunjukkan beban tidak seimbang.
Penggunaan disk sangat berbeda di antara node, dan nilai metrik utilisasi CPU atau load_1m menunjukkan beban tidak seimbang.
Penyebab
- Penting
Dalam kebanyakan kasus, beban tidak seimbang disebabkan oleh alokasi shard yang tidak sesuai. Kami menyarankan Anda memeriksa alokasi shard terlebih dahulu.
Data panas dan data dingin tidak dipisahkan pada node.
PentingMisalnya, jika Anda menentukan parameter routing dalam kueri atau mengkueri data panas, beban tidak seimbang dapat terjadi.
Saat menggunakan instance SLB dan arsitektur multi-zona, koneksi persisten yang tidak dilepas dapat menyebabkan distribusi lalu lintas tidak merata (hal ini jarang terjadi). Untuk informasi selengkapnya, lihat Koneksi persisten tidak merata.
Jika beban tidak seimbang terjadi karena alasan lain, hubungi insinyur dukungan teknis Alibaba Cloud untuk memecahkan masalah tersebut.
Alokasi shard tidak sesuai
Skenario
Perusahaan A telah membeli kluster Alibaba Cloud Elasticsearch. Kluster tersebut terdiri dari tiga node master khusus dan sembilan node data. Setiap node master khusus menyediakan 16 vCPU dan memori 32 GiB, sedangkan setiap node data menyediakan 32 vCPU dan memori 64 GiB. Data utama disimpan dalam indeks test. Selama jam sibuk (16.21 hingga 18.00), performa baca mencapai sekitar 2.000 QPS, performa tulis 1.000 QPS, serta dilakukan kueri terhadap data dingin maupun data panas. Utilisasi CPU dua node mencapai 100%, sehingga memengaruhi layanan Elasticsearch.
Analisis
Periksa jaringan dan instance Elastic Compute Service (ECS). Jika instance ECS berfungsi normal, tinjau data pemantauan jaringan.
Data pemantauan jaringan menunjukkan bahwa jumlah permintaan jaringan dan QPS kueri meningkat selama jam sibuk. Selain itu, utilisasi CPU node terkait meningkat secara signifikan. Berdasarkan informasi ini, dapat disimpulkan bahwa node dengan beban tinggi terutama digunakan untuk memproses permintaan kueri.
Jalankan perintah
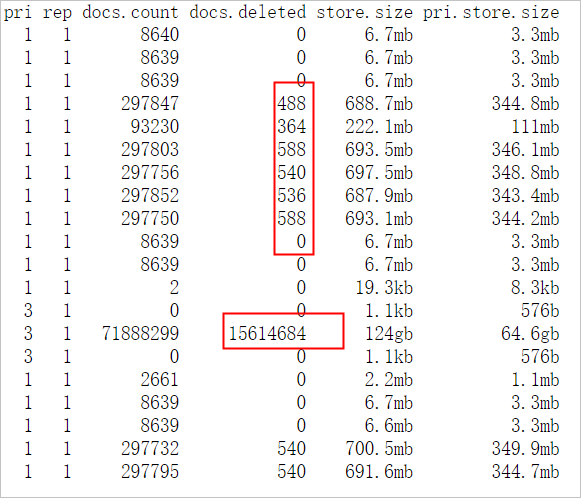
GET _cat/shards?vuntuk mengkueri shard dari indeks tersebut.Keluaran perintah menunjukkan bahwa shard tidak dialokasikan secara merata ke node. Shard dari indeks test terutama dialokasikan ke node dengan beban tinggi. Selain itu, data pemantauan penggunaan disk menunjukkan bahwa penggunaan disk pada node dengan beban tinggi lebih besar daripada node lainnya. Dengan demikian, alokasi shard yang tidak merata menyebabkan penyimpanan yang tidak merata. Saat melakukan kueri atau penulisan data, node yang menyimpan lebih banyak data menangani sebagian besar beban kerja kueri dan tulis.
Jalankan perintah
GET _cat/indices?vuntuk mengkueri informasi indeks tersebut.Keluaran perintah menunjukkan bahwa indeks memiliki lima shard utama dan satu shard replika untuk setiap shard utama. Konfigurasi kluster juga menunjukkan bahwa shard tidak dialokasikan secara merata dan beberapa dokumen telah dihapus. Saat Elasticsearch mencari data, sistem juga mencari dan memfilter dokumen yang ditandai dengan .del, yang mengonsumsi sumber daya tambahan dan secara signifikan menurunkan efisiensi pencarian. Kami menyarankan Anda memanggil operasi force merge selama jam tidak sibuk.
Tinjau log kluster dan log pencarian lambat.
Log menunjukkan bahwa semua kueri merupakan kueri term normal, dan log kluster tidak mencatat kesalahan apa pun. Oleh karena itu, kluster Elasticsearch tidak mengalami kesalahan atau menjalankan pernyataan kueri yang mengonsumsi sumber daya CPU secara berlebihan.
Rangkuman
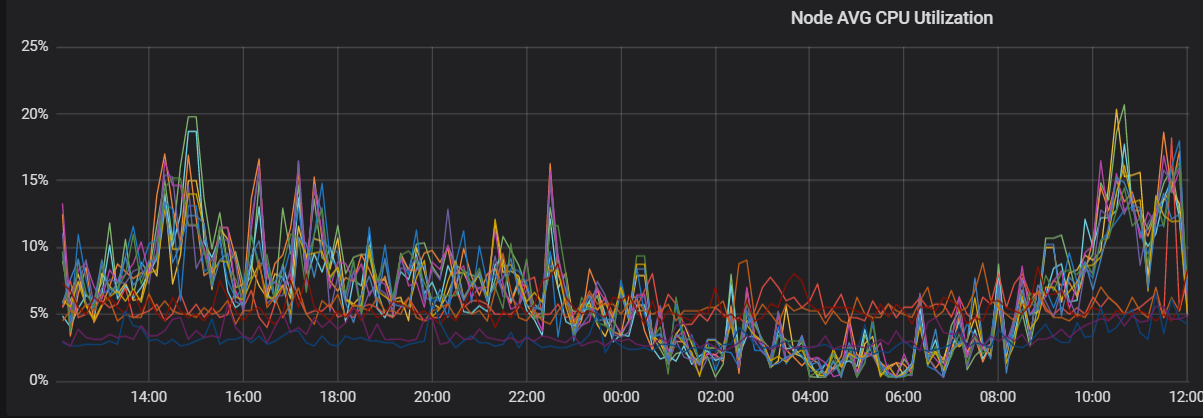
Analisis di atas menunjukkan bahwa ketidakmerataan utilisasi CPU terutama disebabkan oleh alokasi shard yang tidak merata. Anda harus mengalokasikan ulang shard untuk indeks tersebut, dengan memastikan bahwa jumlah total shard utama dan shard replika merupakan kelipatan dari jumlah node data dalam kluster. Setelah optimalisasi, utilisasi CPU menjadi relatif merata di antara node. Gambar berikut menunjukkan tren utilisasi CPU.
Solusi
Rencanakan shard dengan tepat sebelum membuat indeks. Untuk informasi selengkapnya, lihat Pedoman evaluasi shard.
Pedoman evaluasi shard
Jumlah shard dan ukuran setiap shard menentukan stabilitas dan performa kluster Elasticsearch. Anda harus merencanakan shard dengan tepat untuk setiap indeks dalam kluster Elasticsearch guna mencegah terlalu banyak shard yang memengaruhi performa kluster, terutama saat skenario bisnis sulit didefinisikan.
Pada versi sebelum Elasticsearch V7.X, satu indeks memiliki lima shard utama dan satu shard replika untuk setiap shard utama secara default. Pada Elasticsearch V7.X dan versi setelahnya, satu indeks memiliki satu shard utama dan satu shard replika secara default.
Untuk node dengan spesifikasi rendah, ukuran setiap shard tidak boleh melebihi 30 GB. Untuk node dengan spesifikasi tinggi, ukuran setiap shard tidak boleh melebihi 50 GB.
Untuk skenario analitik log atau indeks yang sangat besar, ukuran setiap shard tidak boleh melebihi 100 GB.
Jumlah total shard utama dan shard replika harus sama dengan atau merupakan kelipatan dari jumlah node data.
CatatanSemakin banyak shard utama yang dikonfigurasi, semakin besar overhead performa yang ditimbulkan oleh kluster Elasticsearch Anda.
Kami menyarankan Anda menentukan jumlah shard pada satu node berdasarkan ukuran memori dikalikan 30. Jika terlalu banyak shard direncanakan, kehabisan handle file dapat dengan mudah terjadi dan menyebabkan kegagalan kluster.
Konfigurasikan maksimal lima shard untuk setiap indeks pada satu node.
Jika Anda mengaktifkan fitur Auto Indexing untuk kluster Anda, Anda dapat menggunakan fitur konfigurasi berbasis skenario untuk memodifikasi konfigurasi shard. Pastikan shard dialokasikan secara merata. Untuk informasi selengkapnya, lihat Gunakan templat berbasis skenario untuk memodifikasi konfigurasi kluster.
Ukuran segmen tidak merata
Skenario
Sebuah node dalam kluster Elasticsearch Perusahaan A mengalami peningkatan mendadak pada utilisasi CPU, sehingga memengaruhi performa kueri. Kueri terutama dilakukan pada indeks test, yang memiliki tiga shard utama dan satu shard replika untuk setiap shard utama. Shard dialokasikan secara merata ke node, namun indeks berisi banyak dokumen yang ditandai dengan delete.doc. Instance ECS telah dipastikan berfungsi normal.
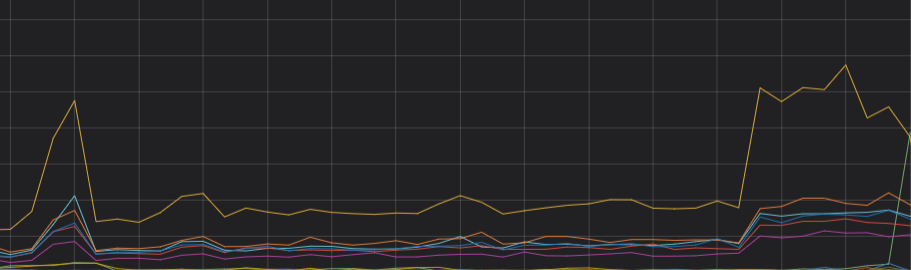
Analisis
Tambahkan
"profile": trueke body kueri.Hasil kueri menunjukkan bahwa Elasticsearch memerlukan waktu lebih lama untuk mengkueri Shard 1 dari indeks test dibandingkan shard lainnya.
Kirim permintaan kueri dengan
preference=_primarydanpreference=_replica, dengan body yang mencakup"profile": true, lalu bandingkan waktu yang diperlukan untuk mengkueri shard utama dan shard replika.Waktu yang diperlukan untuk mengkueri Shard 1 (shard utama) lebih lama daripada waktu yang diperlukan untuk mengkueri shard replikanya. Hal ini menunjukkan bahwa beban tidak seimbang disebabkan oleh Shard 1.
Jalankan perintah
GET _cat/segments/index?v&h=shard,segment,size,size.memory,ipdanGET _cat/shards?vuntuk mengkueri informasi Shard 1.Keluaran perintah menunjukkan bahwa Shard 1 berisi segmen besar dan jumlah dokumen dalam shard tersebut lebih banyak daripada jumlah dokumen dalam shard replikanya. Berdasarkan informasi ini, dapat disimpulkan bahwa beban tidak seimbang disebabkan oleh ukuran segmen yang tidak merata.
CatatanKetidakkonsistenan jumlah dokumen dapat terjadi karena berbagai alasan, misalnya:
Terdapat latensi dalam sinkronisasi data antara shard utama dan shard replika. Jika dokumen terus-menerus ditulis ke shard utama, ketidakkonsistenan data dapat terjadi. Namun, setelah penulisan dokumen dihentikan, jumlah dokumen akan menjadi sama antara shard utama dan shard replikanya.
Setelah data ditulis ke shard utama, sistem meneruskan permintaan penulisan data ke shard replikanya. Jika Anda menggunakan ID dokumen yang dihasilkan secara otomatis untuk menulis dokumen ke shard utama, operasi hapus tidak dapat dilakukan pada shard utama selama proses penulisan berlangsung. Jika Anda melakukan operasi hapus (misalnya, mengirim permintaan Delete by Query untuk menghapus dokumen yang baru saja ditulis), operasi tersebut juga dilakukan pada shard replika. Sistem kemudian meneruskan permintaan penulisan ke shard replika. Dokumen ditulis ke shard replika tanpa verifikasi karena ID dokumen dihasilkan secara otomatis oleh sistem. Akibatnya, jumlah dokumen dalam shard replika berbeda dari jumlah dokumen dalam shard utama, dan shard utama mencakup banyak dokumen yang ditandai dengan
doc.delete.
Solusi (pilih salah satu)
Selama jam tidak sibuk, panggil operasi force merge untuk menggabungkan segmen kecil dan menghapus dokumen yang ditandai dengan delete.doc.
Mulai ulang node tempat shard utama berada untuk mempromosikan shard replika menjadi shard utama. Gunakan shard utama baru untuk menghasilkan shard replika baru, sehingga segmen dalam shard utama dan shard replika baru menjadi identik.
Gambar berikut menunjukkan beban setelah optimalisasi.
Koneksi persisten tidak merata
Skenario
Perusahaan A menerapkan kluster Elasticsearch di dua zona: Zona B dan Zona C. Saat kluster memberikan layanan, beban node di Zona C lebih tinggi daripada beban node di Zona B. Anda telah memastikan bahwa beban tidak seimbang bukan disebabkan oleh perangkat keras atau distribusi data yang tidak merata.
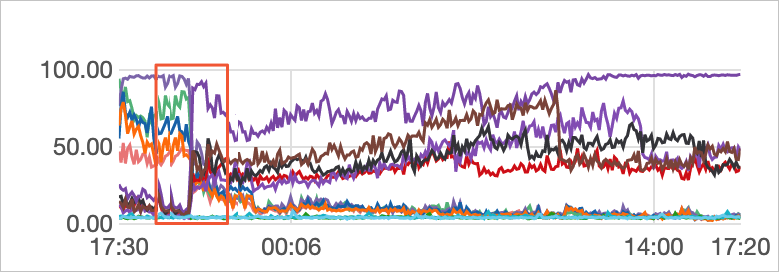
Analisis
Tinjau utilisasi CPU node di kedua zona selama empat hari terakhir.
Data pemantauan menunjukkan bahwa utilisasi CPU node berubah secara signifikan.

Tinjau koneksi TCP ke node.
Data pemantauan menunjukkan bahwa jumlah koneksi TCP di kedua zona sangat berbeda. Hal ini mengindikasikan bahwa beban tidak seimbang disebabkan oleh distribusi koneksi jaringan yang tidak merata.

Periksa koneksi klien.
Klien menggunakan koneksi persisten dan membuat sejumlah kecil koneksi baru. Dalam skenario ini, risiko terjadinya penjadwalan independen pada jaringan multi-zona meningkat. Layanan jaringan dijadwalkan secara independen berdasarkan jumlah koneksi, dan setiap unit penjadwalan memilih node optimal untuk membuat koneksi. Meskipun penjadwalan independen memberikan performa yang lebih tinggi, jika jumlah koneksi baru sedikit, beberapa unit penjadwalan dapat memilih node yang sama untuk membuat koneksi. Node klien kluster Elasticsearch terlebih dahulu meneruskan permintaan ke node lain yang berada di zona yang sama, sehingga menyebabkan beban tidak seimbang di antara zona.
Solusi (pilih salah satu)
Konfigurasi
httpClientBuilder.setConnectionTimeToLive()pada klien. Misalnya, untuk mengatur periode validitas koneksi menjadi 5 menit:httpClientBuilder.setConnectionTimeToLive(5, TimeUnit.MINUTES). Untuk informasi selengkapnya, lihat HttpAsyncClientBuilder.CatatanSaat mengonfigurasi periode validitas koneksi pada klien, gunakan httpClientBuilder.setConnectionTimeToLive() yang direkomendasikan oleh ES. Mengonfigurasi parameter lain, seperti httpClientBuilder.setKeepAliveStrategy(), mungkin tidak seefektif.
Mulai ulang klien secara bersamaan untuk membuat koneksi baru.
Gunakan node klien independen untuk meneruskan lalu lintas kompleks. Pendekatan ini mengurangi risiko ketidakseimbangan beban melalui pembagian tanggung jawab tugas. Bahkan jika node klien mengalami beban berat, node data tidak terpengaruh.
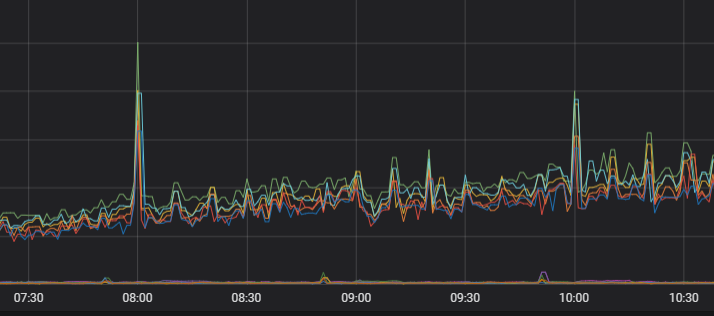
Gambar berikut menunjukkan beban setelah optimalisasi.

Shard tidak merata untuk satu indeks
Skenario: Anda mengamati bahwa shard didistribusikan secara merata di seluruh node, tetapi jumlah shard untuk indeks bisnis lebih tinggi pada node dengan beban tinggi, atau satu shard berisi lebih banyak data pada node tersebut.
Solusi: Tetapkan jumlah maksimum shard yang dialokasikan ke satu indeks pada setiap node dengan mengonfigurasi index.routing.allocation.total_shards_per_node. Nilai parameter dihitung menggunakan rumus
(shard utama + shard replika)/jumlah node data. Nilai parameter harus berupa bilangan bulat. Bulatkan ke atas jika hasilnya desimal.PUT index_name/_settings { { "index.routing.allocation.total_shards_per_node" : "3" } }