Plug-in aliyun-timestream, yang dikembangkan oleh tim Alibaba Cloud Elasticsearch, memungkinkan Anda mengelola indeks deret waktu melalui API khusus—tanpa perlu menulis kueri bahasa domain-spesifik (DSL) yang kompleks. Gunakan PromQL untuk mengkueri data metrik yang disimpan di kluster Anda, dan manfaatkan praktik terbaik bawaan Elasticsearch untuk penyimpanan deret waktu guna mengurangi penggunaan disk.
Untuk ikhtisar lengkap plug-in ini, lihat Ikhtisar aliyun-timestream. Untuk referensi API lengkap dan integrasi Prometheus, lihat Ikhtisar API yang didukung oleh aliyun-timestream dan Integrasikan aliyun-timestream dengan API Prometheus.
Kapan menggunakan aliyun-timestream
Gunakan plug-in aliyun-timestream jika data Anda memenuhi semua kriteria berikut:
Data terdiri dari pengukuran metrik dengan timestamp (misalnya, penggunaan CPU, memori, I/O disk, dan sejenisnya)
Data ditulis hampir secara real-time dan kira-kira dalam urutan
@timestampSetiap titik data diidentifikasi oleh serangkaian bidang dimensi (label seperti
clusterId,nodeId,namespace)Anda berencana mengkueri data menggunakan PromQL atau agregasi Elasticsearch
Indeks deret waktu yang dibuat melalui aliyun-timestream dibangun di atas data stream Elasticsearch, dengan konfigurasi otomatis untuk index.mode: time_series, plug-in kompresi indeks aliyun-codec, dan routing berbasis dimensi. Ini berbeda dari indeks atau data stream biasa dalam beberapa aspek utama:
Indeks pendukung berbatas waktu: Data dari jendela waktu yang sama dirutekan ke indeks pendukung yang sama, berdasarkan
index.time_series.start_timedanindex.time_series.end_time.Routing berbasis dimensi: Semua titik data yang memiliki nilai dimensi yang sama disimpan pada shard yang sama, diidentifikasi oleh bidang internal
_tsid. Hal ini meningkatkan kompresi dan kinerja kueri.Penyimpanan bidang metrik: Bidang metrik hanya menyimpan doc values dan tidak menyimpan data indeks terbalik, sehingga mengurangi penggunaan disk.
Dukungan PromQL: Kueri data metrik menggunakan PromQL melalui API kompatibel Prometheus dari plug-in, bukan DSL.
Prasyarat
Sebelum memulai, pastikan Anda memiliki:
Kluster Alibaba Cloud Elasticsearch Edisi Standar yang memenuhi salah satu persyaratan versi berikut:
Versi kluster V7.16 atau lebih baru, dan versi kernel V1.7.0 atau lebih baru
Versi kluster V7.10, dan versi kernel V1.8.0 atau lebih baru
Untuk instruksi membuat kluster, lihat Buat kluster Alibaba Cloud Elasticsearch.
Kelola indeks deret waktu
Buat indeks deret waktu
Buat indeks deret waktu bernama test_stream:
PUT _time_stream/test_streamIni akan membuat data stream Elasticsearch (bukan indeks mandiri), beserta templat indeks bernama .timestream_test_stream yang telah dikonfigurasi sebelumnya dengan pengaturan berikut:
| Pengaturan | Nilai | Efek |
|---|---|---|
index.mode | time_series | Mengaktifkan mode deret waktu dengan praktik terbaik bawaan Elasticsearch untuk penyimpanan deret waktu |
index.codec | ali | Mengaktifkan plug-in kompresi indeks aliyun-codec |
index.ali_codec_service.enabled | true | Mengaktifkan kompresi indeks |
index.doc_value.compression.default | zstd | Mengompresi data berorientasi kolom (doc values) menggunakan algoritma zstd |
index.postings.compression | zstd | Mengompresi data indeks terbalik menggunakan zstd |
index.ali_codec_service.source_reuse_doc_values.enabled | true | Mengaktifkan penggunaan ulang source dari doc values untuk mengurangi penyimpanan |
index.source.compression | zstd | Mengompresi data berorientasi baris (source) menggunakan zstd |
index.translog.durability | ASYNC | Mengurangi latensi tulis dengan menggunakan penulisan translog asinkron |
index.refresh_interval | 10s | Mengelompokkan penyegaran indeks untuk meningkatkan throughput tulis |
index.routing_path | labels.* | Merutekan dokumen ke shard berdasarkan bidang label |
Templat indeks juga telah dikonfigurasi sebelumnya untuk pemetaan dua kategori bidang:
Bidang dimensi (
labels.*): Dipetakan sebagaikeyworddengantime_series_dimension: true. Semua bidang dimensi digabungkan ke dalam bidang internal_tsid, yang secara unik mengidentifikasi setiap deret waktu.Bidang metrik (
metrics.*): Dipetakan sebagaidoubleataulongdengan"index": false. Hanya doc values yang disimpan—tidak ada data indeks terbalik.
Lihat konfigurasi lengkap test_stream:
GET _time_stream/test_streamSesuaikan templat indeks
Kirimkan badan template saat membuat indeks untuk mengganti pengaturan default. Contoh berikut menunjukkan penyesuaian umum:
Tentukan jumlah shard primary:
PUT _time_stream/test_stream { "template": { "settings": { "index": { "number_of_shards": "2" } } } }Sesuaikan model data (konvensi penamaan bidang):
PUT _time_stream/test_stream { "template": { "settings": { "index": { "number_of_shards": "2" } } }, "time_stream": { "labels_fields": ["labels_*"], "metrics_fields": ["metrics_*"] } }
Perbarui indeks deret waktu
Perbarui jumlah shard primary untuk test_stream:
POST _time_stream/test_stream/_update
{
"template": {
"settings": {
"index": {
"number_of_shards": "4"
}
}
}
}Sertakan semua konfigurasi yang ada dalam badan permintaan pembaruan, bukan hanya bidang yang ingin diubah. Menghilangkan suatu bidang akan mengembalikannya ke nilai default. Jalankan GET _time_stream/test_stream terlebih dahulu untuk mengambil konfigurasi lengkap saat ini, lalu modifikasi bidang yang diperlukan.
Setelah diperbarui, pengaturan baru tidak berlaku untuk indeks pendukung saat ini. Lakukan rollover pada indeks untuk menerapkannya:
POST test_stream/_rolloverIndeks pendukung baru dibuat dengan pengaturan yang diperbarui. Indeks pendukung asli tetap mempertahankan pengaturan sebelumnya.
Hapus indeks deret waktu
Hapus test_stream dan semua datanya:
DELETE _time_stream/test_streamOperasi ini akan menghapus semua data dan konfigurasi indeks secara permanen serta tidak dapat dikembalikan.
Tulis dan kueri data deret waktu
Indeks deret waktu digunakan dengan cara yang sama seperti indeks Elasticsearch biasa untuk penulisan data dan kueri dasar.
Tulis data
Gunakan API bulk atau index untuk menulis dokumen. Setiap dokumen harus menyertakan bidang @timestamp yang diatur ke waktu pengukuran dilakukan.
POST test_stream/_doc
{
"@timestamp": 1630465208722,
"metrics": {
"cpu.idle": 79.67298116109929,
"disk_ioutil": 17.630910821570456,
"mem.free": 75.79973639970004
},
"labels": {
"disk_type": "disk_type2",
"namespace": "namespaces1",
"clusterId": "clusterId3",
"nodeId": "nodeId5"
}
}Cara kerja routing berbasis waktu
Setiap indeks pendukung dalam data stream memiliki rentang waktu yang ditentukan oleh index.time_series.start_time dan index.time_series.end_time. Dokumen ditulis ke indeks pendukung yang rentang waktunya mencakup nilai @timestamp dokumen tersebut.
Data stream mengelola rentang waktu ini secara otomatis. Setelah rollover, indeks pendukung baru mengambil alih dari waktu akhir indeks sebelumnya, sehingga semua indeks pendukung bersama-sama mencakup rentang waktu kontinu tanpa celah.
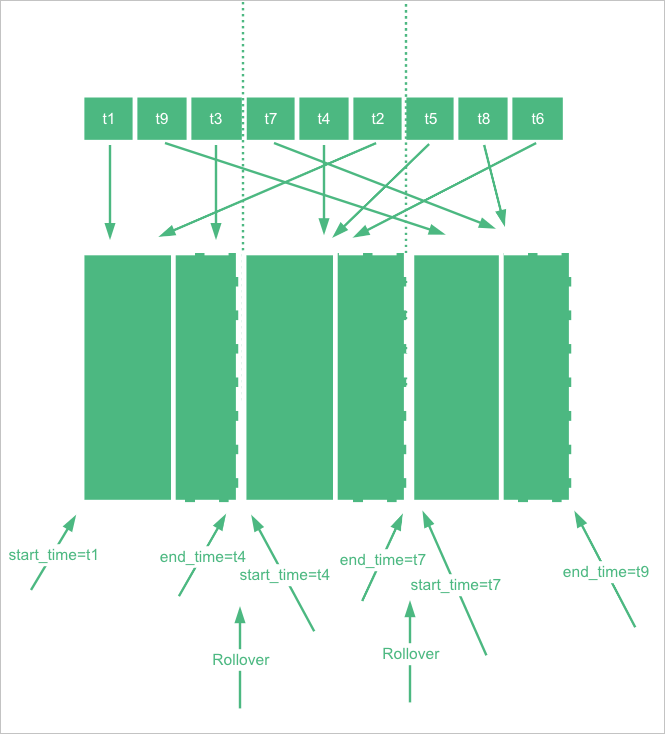
Batasan rentang waktu dalam UTC. Jika aplikasi Anda berjalan di UTC+8, lakukan konversi yang sesuai: misalnya, 2022-06-21T00:00:00.000Z (UTC) sesuai dengan 2022-06-21T08:00:00.000 di UTC+8.
Kueri data
Cari semua dokumen dalam test_stream:
GET test_stream/_searchLihat detail indeks:
GET _cat/indices/test_stream?v&s=iLihat statistik indeks
Dapatkan statistik untuk test_stream, termasuk jumlah deret waktu yang dilacak per shard:
GET _time_stream/test_stream/_statsContoh respons:
{
"_shards" : {
"total" : 2,
"successful" : 2,
"failed" : 0
},
"time_stream_count" : 1,
"indices_count" : 1,
"total_store_size_bytes" : 19132,
"time_streams" : [
{
"time_stream" : "test_stream",
"indices_count" : 1,
"store_size_bytes" : 19132,
"tsid_count" : 2
}
]
}Metrik time_stream_count menghitung jumlah deret waktu unik per shard primary dengan membaca doc values bidang _tsid. Ini merupakan operasi yang relatif mahal. Untuk mengurangi biaya:
Untuk indeks read-only, konfigurasikan kebijakan caching sehingga penghitungan hanya dilakukan sekali dan tidak diperbarui lagi.
Untuk indeks aktif, cache diperbarui setiap 5 menit secara default. Sesuaikan interval ini dengan parameter
index.time_series.stats.refresh_interval. Nilai minimum adalah 1 menit.
Gunakan API Prometheus untuk mengkueri data
Plug-in aliyun-timestream menyediakan antarmuka kueri kompatibel Prometheus di /_time_stream/prom/{index_name}. Gunakan ini untuk mengintegrasikan dengan Grafana atau tool kompatibel Prometheus lainnya.
Konfigurasikan sumber data Prometheus
Opsi 1: Konsol Grafana
Di konsol Grafana, tambahkan sumber data Prometheus dan atur URL ke /_time_stream/prom/test_stream. Indeks deret waktu kemudian tersedia sebagai sumber data Prometheus secara langsung.
Opsi 2: Awalan dan akhiran bidang kustom
Saat mengkueri melalui API Prometheus, plug-in secara default menghapus awalan metrics. dari bidang metrik dan awalan labels. dari bidang dimensi.
Jika Anda membuat indeks dengan model data kustom (awalan bidang non-default), konfigurasikan pemetaan awalan dan akhiran secara eksplisit:
PUT _time_stream/{name}
{
"time_stream": {
"labels_fields": "@labels.*_l",
"metrics_fields": "@metrics.*_m",
"label_prefix": "@labels.",
"label_suffix": "_l",
"metric_prefix": "@metrics.",
"metric_suffix": "_m"
}
}Kueri metadata
Lihat semua bidang metrik dalam test_stream:
GET /_time_stream/prom/test_stream/metadataContoh respons:
{
"status" : "success",
"data" : {
"cpu.idle" : [
{
"type" : "gauge",
"help" : "",
"unit" : ""
}
],
"disk_ioutil" : [
{
"type" : "gauge",
"help" : "",
"unit" : ""
}
],
"mem.free" : [
{
"type" : "gauge",
"help" : "",
"unit" : ""
}
]
}
}Lihat semua bidang dimensi dalam test_stream:
GET /_time_stream/prom/test_stream/labelsContoh respons:
{
"status" : "success",
"data" : [
"__name__",
"clusterId",
"disk_type",
"namespace",
"nodeId"
]
}Lihat semua nilai untuk bidang dimensi tertentu:
GET /_time_stream/prom/test_stream/label/clusterId/valuesContoh respons:
{
"status" : "success",
"data" : [
"clusterId1",
"clusterId3"
]
}Lihat semua deret waktu untuk metrik cpu.idle:
GET /_time_stream/prom/test_stream/series?match[]=cpu.idleContoh respons:
{
"status" : "success",
"data" : [
{
"__name__" : "cpu.idle",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"clusterId" : "clusterId1",
"nodeId" : "nodeId2"
},
{
"__name__" : "cpu.idle",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"clusterId" : "clusterId1",
"nodeId" : "nodeId5"
},
{
"__name__" : "cpu.idle",
"disk_type" : "disk_type2",
"namespace" : "namespaces1",
"clusterId" : "clusterId3",
"nodeId" : "nodeId5"
}
]
}Kueri data dengan PromQL
Gunakan API kueri instan dan kueri rentang Prometheus untuk menjalankan kueri PromQL terhadap indeks deret waktu Anda. Untuk detail sintaks PromQL yang didukung, lihat Dukungan aliyun-timestream untuk PromQL.
Kueri instan
GET /_time_stream/prom/test_stream/query?query=cpu.idle&time=1655769837Parameter time dalam satuan detik Unix. Jika dihilangkan, kueri akan mengembalikan data dari 5 menit sebelumnya.
Contoh respons:
{
"status" : "success",
"data" : {
"resultType" : "vector",
"result" : [
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId1",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"nodeId" : "nodeId2"
},
"value" : [
1655769837,
"79.672981161"
]
},
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId1",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"nodeId" : "nodeId5"
},
"value" : [
1655769837,
"79.672981161"
]
},
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId3",
"disk_type" : "disk_type2",
"namespace" : "namespaces1",
"nodeId" : "nodeId5"
},
"value" : [
1655769837,
"79.672981161"
]
}
]
}
}Kueri rentang
GET /_time_stream/prom/test_stream/query_range?query=cpu.idle&start=1655769800&end=16557699860&step=1mContoh respons:
{
"status" : "success",
"data" : {
"resultType" : "matrix",
"result" : [
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId1",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"nodeId" : "nodeId2"
},
"value" : [
[
1655769860,
"79.672981161"
]
]
},
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId1",
"disk_type" : "disk_type1",
"namespace" : "namespaces2",
"nodeId" : "nodeId5"
},
"value" : [
[
1655769860,
"79.672981161"
]
]
},
{
"metric" : {
"__name__" : "cpu.idle",
"clusterId" : "clusterId3",
"disk_type" : "disk_type2",
"namespace" : "namespaces1",
"nodeId" : "nodeId5"
},
"value" : [
[
1655769860,
"79.672981161"
]
]
}
]
}
}Konfigurasikan downsampling
Downsampling mengurangi resolusi data deret waktu lama untuk mempercepat kueri pada rentang waktu besar. Plug-in secara otomatis memilih indeks downsampling yang paling sesuai berdasarkan nilai fixed_interval dalam kueri agregasi Anda.
Konfigurasikan interval downsampling saat membuat indeks deret waktu. Contoh berikut mengonfigurasi tiga interval downsampling: 1 menit, 10 menit, dan 60 menit.
PUT _time_stream/test_stream
{
"time_stream": {
"downsample": [
{
"interval": "1m"
},
{
"interval": "10m"
},
{
"interval": "60m"
}
]
}
}Setelah data ditulis dan indeks pendukung asli di-rollover, plug-in secara otomatis menghasilkan indeks downsampling dari indeks pendukung asli. Downsampling dimulai ketika waktu saat ini setidaknya dua jam melewati end_time indeks tersebut.
Cara kerja pemilihan indeks otomatis
Saat Anda menjalankan kueri agregasi, berikan nama indeks asli dan tentukan fixed_interval dalam agregasi date_histogram. Plugin memilih indeks downsampling dengan Presisi waktu tertinggi yang masih merupakan kelipatan dari fixed_interval.
Misalnya, jika fixed_interval adalah 120m dan interval downsampling adalah 1m, 10m, dan 60m, plug-in akan mengkueri indeks downsampling 60m.
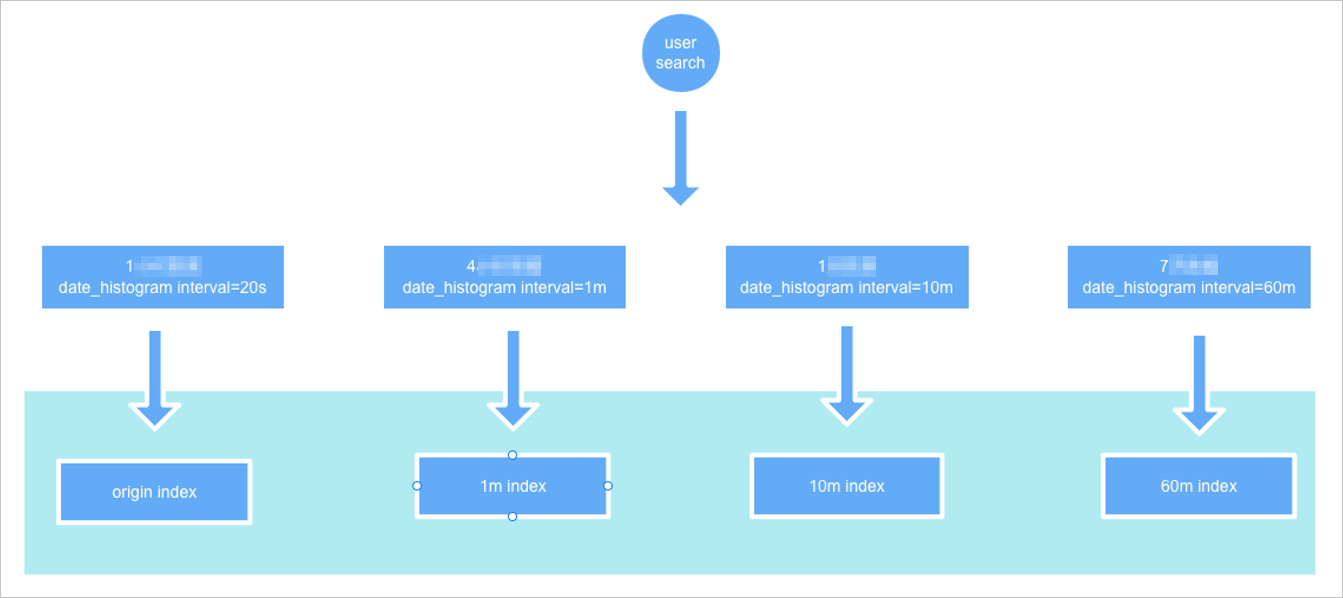
Contoh kueri menggunakan fixed_interval: 120m:
GET test_stream/_search?size=0&request_cache=false
{
"aggs": {
"1": {
"terms": {
"field": "labels.disk_type",
"size": 10
},
"aggs": {
"2": {
"date_histogram": {
"field": "@timestamp",
"fixed_interval": "120m"
}
}
}
}
}
}Contoh respons (mengkueri indeks downsampling 60m):
{
"took" : 15,
"timed_out" : false,
"_shards" : {
"total" : 2,
"successful" : 2,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"1" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [
{
"key" : "disk_type2",
"doc_count" : 9,
"2" : {
"buckets" : [
{
"key_as_string" : "2022-06-20T06:00:00.000Z",
"key" : 1655704800000,
"doc_count" : 9
}
]
}
}
]
}
}
}hits.total.value adalah 1, artinya satu catatan hasil downsampling dikembalikan. doc_count sebesar 9 dalam agregasi menunjukkan bahwa 9 titik data asli digabungkan menjadi catatan tersebut, mengonfirmasi bahwa kueri mengenai indeks downsampling, bukan yang asli.
Sebagai perbandingan, mengatur fixed_interval ke 20s akan mengkueri indeks asli dan mengembalikan hits.total.value: 9, sesuai dengan doc_count: 9.
Indeks downsampling memiliki pengaturan dan pemetaan yang sama dengan indeks asli, kecuali data diagregasi ke dalam bucket waktu berdasarkan interval yang dikonfigurasi.
Uji downsampling dengan indeks demo
Prosedur berikut mendemonstrasikan siklus hidup downsampling lengkap menggunakan rentang waktu yang dikontrol secara manual. Ini berguna untuk pengujian dan validasi. Di lingkungan produksi, plug-in memicu downsampling secara otomatis setelah rollover.
Buat indeks dengan rentang waktu tetap dan konfigurasi downsampling. Nilai
start_timedanend_timemensimulasikan jendela waktu lampau sehingga kondisi pemicu downsampling (waktu saat ini setidaknya dua jam melewatiend_time) langsung terpenuhi.PentingSetelah langkah ini, periksa
end_timedengan menjalankanGET {index}/_settings. Sistem menyesuaikanend_timesetiap 5 menit secara default. Lanjutkan ke langkah berikutnya sebelumend_timediperbarui.PUT _time_stream/test_stream { "template": { "settings": { "index.time_series.start_time": "2022-06-20T00:00:00.000Z", "index.time_series.end_time": "2022-06-21T00:00:00.000Z" } }, "time_stream": { "downsample": [ { "interval": "1m" }, { "interval": "10m" }, { "interval": "60m" } ] } }Tulis dokumen dengan
@timestampdiatur ke nilai dalam rentang[start_time, end_time):POST test_stream/_doc { "@timestamp": 1655706106000, "metrics": { "cpu.idle": 79.67298116109929, "disk_ioutil": 17.630910821570456, "mem.free": 75.79973639970004 }, "labels": { "disk_type": "disk_type2", "namespace": "namespaces1", "clusterId": "clusterId3", "nodeId": "nodeId5" } }Hapus
start_timedanend_timedari indeks, dan pertahankan konfigurasi downsampling:POST _time_stream/test_stream/_update { "time_stream": { "downsample": [ { "interval": "1m" }, { "interval": "10m" }, { "interval": "60m" } ] } }Lakukan rollover pada indeks:
POST test_stream/_rolloverSetelah rollover selesai, lihat indeks downsampling yang dihasilkan:
GET _cat/indices/test_stream?v&s=iOutput yang diharapkan:
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size green open .ds-test_stream-2022.06.21-000001 vhEwKIlwSGO3ax4RKn**** 1 1 9 0 18.5kb 12.1kb green open .ds-test_stream-2022.06.21-000001_interval_10m r9Tsj0v-SyWJDc64oC**** 1 1 1 0 15.8kb 7.9kb green open .ds-test_stream-2022.06.21-000001_interval_1h cKsAlMK-T2-luefNAF**** 1 1 1 0 15.8kb 7.9kb green open .ds-test_stream-2022.06.21-000001_interval_1m L6ocasDFTz-c89KjND**** 1 1 1 0 15.8kb 7.9kb green open .ds-test_stream-2022.06.21-000002 42vlHEFFQrmMAdNdCz**** 1 1 0 0 452b 226bTiga indeks downsampling (
_interval_1m,_interval_10m,_interval_1h) dibuat bersamaan dengan indeks pendukung baru (000002).
Langkah selanjutnya
Ikhtisar API yang didukung oleh aliyun-timestream — referensi API lengkap termasuk catatan penggunaan API downsampling
Integrasikan aliyun-timestream dengan API Prometheus — panduan integrasi API Prometheus lengkap dan detail dukungan PromQL