Konektivitas jaringan memungkinkan Anda menghubungkan ruang kerja EMR Serverless Spark ke virtual private cloud (VPC) Anda sehingga pekerjaan Spark dapat mengakses sumber data dan layanan di dalam VPC tersebut. Panduan ini menjelaskan cara menghubungkan pekerjaan Spark SQL dan JAR ke Hive Metastore (HMS) dengan mengonfigurasi koneksi jaringan.
Setelah Anda menghubungkan ruang kerja ke VPC, pekerjaan Spark akan mengarahkan lalu lintas melalui VPC tersebut. Jika pekerjaan Anda juga perlu mengakses titik akhir publik (misalnya, OSS melalui jaringan publik), deploy Internet NAT gateway di VPC tersebut dan konfigurasikan SNAT. Tanpa langkah ini, titik akhir publik tidak dapat dijangkau. Untuk informasi lebih lanjut, lihat Gunakan fitur SNAT dari Internet NAT gateway untuk mengakses internet.
Prasyarat
Sebelum memulai, pastikan Anda telah:
-
Membuat kluster DataLake di halaman EMR on ECS yang mencakup layanan Hive dan menggunakan Built-in MySQL untuk Metadata. Untuk informasi lebih lanjut, lihat Buat kluster.
Zona yang didukung
vSwitch hanya tersedia di zona tertentu.
Langkah 1: Tambahkan koneksi jaringan
-
Login ke Konsol EMR.
-
Pada panel navigasi kiri, pilih EMR Serverless > Spark.
-
Di halaman Spark, klik nama ruang kerja.
-
Pada panel navigasi kiri, klik Network Connection.
-
Di halaman Network Connection, klik Network Connection.
-
Pada kotak dialog Create Network Connection, konfigurasikan parameter berikut, lalu klik OK. Koneksi siap digunakan ketika Status berubah menjadi Berhasil.
Parameter Deskripsi Name Masukkan nama untuk koneksi tersebut. VPC Pilih VPC yang sama dengan kluster EMR Anda. Jika tidak ada VPC yang tersedia, klik Create VPC untuk membuat satu di Konsol VPC. Untuk informasi lebih lanjut, lihat VPCs and vSwitches. vSwitch Pilih vSwitch dalam VPC yang sama dengan kluster EMR Anda. vSwitch tersebut harus berada di zona yang didukung (lihat Zona yang didukung). Jika tidak ada vSwitch yang tersedia di zona yang diperlukan, buat satu di Konsol VPC. Untuk informasi lebih lanjut, lihat Create and manage vSwitches. 
Langkah 2: Tambahkan aturan grup keamanan ke kluster EMR
Saat pekerjaan Spark dijalankan, lalu lintas mengalir dari blok CIDR vSwitch ke dalam VPC Anda. Untuk mengizinkan lalu lintas tersebut mencapai layanan HMS, tambahkan aturan inbound ke grup keamanan kluster EMR.
-
Ambil blok CIDR dari vSwitch yang Anda pilih di Langkah 1. Login ke Konsol VPC dan buka halaman vSwitches untuk menemukan blok CIDR tersebut.
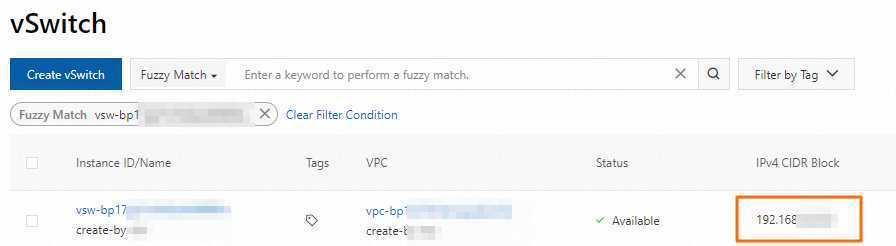
-
Login ke Konsol EMR on ECS.
-
Di halaman EMR on ECS, klik ID kluster.
-
Di tab Basic Information, pada bagian Security, klik tautan di sebelah Cluster Security Group.
-
Di halaman Security Group Details, buka bagian Rules, lalu klik Add Rule. Konfigurasikan parameter berikut, lalu klik OK.
PentingJangan mengatur Authorization Object ke
0.0.0.0/0. Aturan yang terlalu permisif membuka kluster Anda terhadap serangan dari internet publik.Parameter Nilai Protocol TCP (default). Untuk autentikasi Kerberos, pilih UDP dan buka port 88. Untuk informasi lebih lanjut, lihat Aktifkan otentikasi Kerberos. Source Blok CIDR dari vSwitch pada langkah 1. Destination (Current Instance) Tentukan port tujuan untuk mengizinkan akses. Misalnya, 9083.
(Opsional) Langkah 3: Siapkan tabel Hive
Lewati langkah ini jika Anda sudah memiliki tabel Hive untuk dikueri.
-
Gunakan SSH untuk login ke node master kluster EMR Anda. Untuk informasi lebih lanjut, lihat Login ke kluster.
-
Masukkan command line Hive:
hive -
Buat tabel:
CREATE TABLE my_table (id INT, name STRING); -
Masukkan data sampel:
INSERT INTO my_table VALUES (1, 'John'); INSERT INTO my_table VALUES (2, 'Jane'); -
Verifikasi data:
SELECT * FROM my_table;
(Opsional) Langkah 4: Bangun dan unggah artefak JAR
Lewati langkah ini jika Anda berencana menggunakan pekerjaan Spark SQL.
-
Buat proyek Maven di mesin lokal Anda dengan kelas berikut:
-
Bangun file JAR:
mvn packagePerintah ini menghasilkan
sparkDataFrame-1.0-SNAPSHOT.jardi direktoritarget/. -
Unggah file JAR ke ruang kerja Anda:
-
Di halaman EMR Serverless Spark untuk ruang kerja Anda, klik Artifacts di panel navigasi kiri.
-
Di halaman Artifacts, klik Upload File dan unggah
sparkDataFrame-1.0-SNAPSHOT.jar.
-
Langkah 5: Buat dan jalankan pekerjaan
Pekerjaan JAR
-
Di halaman EMR Serverless Spark, klik Development di panel navigasi kiri.
-
Klik New, masukkan nama, pilih Application(Batch) > JAR, lalu klik OK.
-
Di editor pekerjaan, konfigurasikan parameter berikut. Biarkan semua parameter lain pada nilai default-nya. Untuk Spark Configuration, masukkan konfigurasi berikut, ganti
<hms-private-ip>dengan Alamat IP pribadi dari node master HMS:Parameter Nilai Main JAR Resource Pilih sparkDataFrame-1.0-SNAPSHOT.jar.Main Class com.example.DataFrameExampleNetwork Connection Pilih koneksi jaringan yang dibuat di Langkah 1. Spark Configuration Lihat di bawah. spark.hadoop.hive.metastore.uris thrift://<hms-private-ip>:9083 spark.hadoop.hive.imetastoreclient.factory.class org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClientFactoryUntuk menemukan Alamat IP pribadi, buka halaman Nodes kluster EMR dan perluas kelompok node emr-master.
-
Klik Run.
-
Setelah pekerjaan selesai, buka Execution Records di bagian bawah halaman, lalu klik Logs untuk melihat output di tab Log Exploration.
Pekerjaan Spark SQL
-
Buat dan mulai sesi Spark SQL. Untuk informasi lebih lanjut, lihat Kelola sesi SQL. Saat mengonfigurasi sesi, atur hal berikut:
-
Network Connection: Pilih koneksi jaringan yang dibuat di Langkah 1.
-
Spark Configuration: Masukkan konfigurasi berikut, ganti
<hms-private-ip>dengan Alamat IP pribadi dari node master HMSspark.hadoop.hive.metastore.uris thrift://<hms-private-ip>:9083 spark.hadoop.hive.imetastoreclient.factory.class org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClientFactoryUntuk menemukan Alamat IP pribadi, buka halaman Nodes kluster EMR dan klik ikon
 di sebelah kelompok node emr-master.
di sebelah kelompok node emr-master.
-
-
Di halaman EMR Serverless Spark, klik Development di panel navigasi kiri.
-
Klik ikon
 untuk membuat file baru.
untuk membuat file baru. -
Di kotak dialog New, masukkan nama (misalnya,
users_task), biarkan jenisnya sebagai SparkSQL, lalu klik OK. -
Pilih catalog, database, dan instans sesi SQL. Masukkan kueri berikut, lalu klik Run:
Saat menerapkan kode SQL yang menggunakan metastore eksternal ke alur kerja, tentukan tabel dalam format
db.table_namedan pilih database default dalam formatcatalog_id.defaultdari opsi Catalog.SELECT * FROM default.my_table;Hasil muncul di bagian Execution Results di bagian bawah halaman.
