Gunakan editor SQL bawaan di EMR Serverless Spark untuk menulis dan menjalankan pekerjaan Spark SQL secara interaktif. Setelah pekerjaan dijalankan, akses Spark UI untuk memeriksa status eksekusi, penggunaan sumber daya, dan log.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
-
Ruang kerja. Lihat Buat ruang kerja.
-
Instans sesi SQL. Lihat Kelola sesi SQL.
Buat pekerjaan Spark SQL
Parameter DLF Catalog dimuat selama inisialisasi SparkSession. Menyetel parameter terkait Catalog seperti spark.sql.catalog.dlf.warehouse secara dinamis dalam kode PySpark menggunakan spark.conf.set() tidak berlaku. Untuk mengonfigurasi parameter ini dengan benar, tentukan sebagai parameter startup saat Anda mengirimkan pekerjaan. Misalnya, tambahkan spark.sql.catalog.dlf.warehouse=oss://your-bucket/warehouse-path di bagian Configuration konsol EMR Serverless Spark atau gunakan parameter --conf di CLI.
-
Buka halaman pengembangan.
-
Masuk ke Konsol EMR.
-
Di panel navigasi sebelah kiri, pilih EMR Serverless > Spark.
-
Di halaman Spark, klik nama ruang kerja yang dituju.
-
Di halaman EMR Serverless Spark, klik Development di panel navigasi sebelah kiri.
-
-
Buat pekerjaan.
-
Di tab Development, klik ikon
 .
. -
Di kotak dialog, masukkan Name, atur Type menjadi SparkSQL, lalu klik OK.
-
Di pojok kanan atas, pilih katalog data, database, dan instans sesi SQL yang sedang berjalan. Untuk membuat instans sesi SQL baru, pilih Connect to SQL Session dari daftar drop-down. Lihat Kelola sesi SQL untuk detailnya.

-
Masukkan pernyataan SQL di editor.
Contoh 1: Operasi SQL dasar
Buat database, alihkan ke database tersebut, buat tabel, masukkan baris data, lalu kueri datanya.
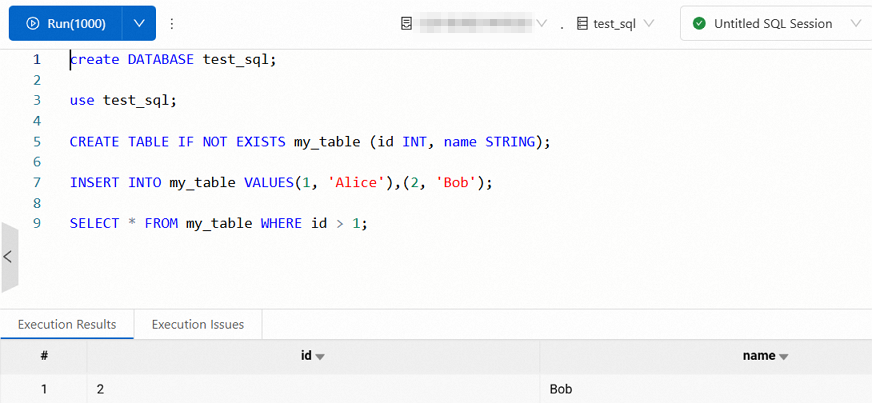
create DATABASE test_sql; use test_sql; CREATE TABLE IF NOT EXISTS my_table (id INT, name STRING); INSERT INTO my_table VALUES(1, 'Alice'),(2, 'Bob'); SELECT * FROM my_table WHERE id > 1;Hasilnya ditampilkan pada gambar berikut.
Contoh 2: Tabel eksternal berbasis CSV
Buat tabel eksternal yang didukung oleh file CSV di Object Storage Service (OSS) dan jalankan kueri analitik. Ganti
oss://<bucketname>/user/dengan path bucket Anda yang sebenarnya.-
Buat tabel eksternal. Definisikan tabel bernama
ordersdengan bidang-bidang berikut:-
order_id: ID pesanan. -
order_date: Timestamp pesanan, misalnya'2025-07-01 10:00:00'. -
order_category: Kategori produk, misalnya'Electronics'atau'Apparel'. -
order_revenue: Jumlah pesanan.
CREATE TABLE orders ( order_id STRING, -- Order ID order_date STRING, -- Order timestamp order_category STRING, -- Product category order_revenue DOUBLE -- Order amount ) USING CSV OPTIONS ( path 'oss://<bucketname>/user/', header 'true' ); -
-
Masukkan data uji.
INSERT OVERWRITE TABLE orders VALUES ('o1', '2025-07-01 10:00:00', 'Electronics', 5999.0), ('o2', '2025-07-02 11:30:00', 'Apparel', 299.0), ('o3', '2025-07-03 14:45:00', 'Electronics', 899.0), ('o4', '2025-07-04 09:15:00', 'Home Goods', 99.0), ('o5', '2025-07-05 16:20:00', 'Electronics', 1999.0), ('o6', '2025-07-06 08:00:00', 'Apparel', 199.0), ('o7', '2025-07-07 12:10:00', 'Electronics', 799.0), ('o8', '2025-07-08 18:30:00', 'Home Goods', 59.0), ('o9', '2025-07-09 20:00:00', 'Electronics', 399.0), ('o10', '2025-07-10 07:45:00', 'Apparel', 599.0), ('o11', '2025-07-11 09:00:00', 'Electronics', 1299.0), ('o12', '2025-07-12 13:20:00', 'Home Goods', 159.0), ('o13', '2025-07-13 17:15:00', 'Apparel', 499.0), ('o14', '2025-07-14 21:30:00', 'Electronics', 999.0), ('o15', '2025-07-15 06:10:00', 'Home Goods', 299.0); -
Jalankan kueri analitik. Kueri berikut mengembalikan kinerja penjualan berdasarkan kategori selama periode 15 hari — jumlah pesanan, total GMV (Gross Merchandise Value), jumlah pesanan rata-rata, dan waktu pesanan terbaru — untuk kategori dengan pendapatan total di atas 1.000, diurutkan berdasarkan GMV secara menurun.
SELECT order_category, COUNT(order_id) AS order_count, SUM(order_revenue) AS gmv, AVG(order_revenue) AS avg_order_amount, MAX(order_date) AS latest_order_date FROM orders WHERE CAST(order_date AS TIMESTAMP) BETWEEN '2025-07-01' AND '2025-07-15' GROUP BY order_category HAVING SUM(order_revenue) > 1000 ORDER BY gmv DESC, order_category ASC;
Contoh 3: Buat tabel Hive Parquet (Tabel Format DLF)
Secara default, EMR Serverless Spark menggunakan Apache Paimon sebagai format tabel. Untuk membuat tabel Hive Parquet, Anda harus mengganti pengaturan default melalui parameter startup pekerjaan.
Parameter startup
Sebelum membuat tabel Hive Parquet, tambahkan parameter konfigurasi Spark berikut untuk mencegah katalog Paimon mengintersepsi pembuatan tabel:
spark.sql.catalog.spark_catalog=org.apache.spark.sql.hive.HiveCatalog spark.sql.defaultFileFormat=parquetAnda dapat menambahkan parameter ini di bagian Configuration konsol EMR Serverless Spark atau gunakan parameter
--confdi CLI.Metode SQL
Gunakan sintaksis
CREATE TABLE ... USING PARQUETuntuk membuat tabel Hive Parquet. Jangan gunakanSTORED AS PARQUET.CREATE TABLE my_parquet_table ( id INT, name STRING, created_at TIMESTAMP ) USING PARQUET;Metode API DataFrame
Gunakan
df.write.format("parquet").saveAsTable(...)untuk menulis data sebagai tabel Hive Parquet.df.write.format("parquet").saveAsTable("my_parquet_table")CatatanJika ruang kerja Anda terikat ke DLF Catalog, kami menyarankan agar Anda membuat tabel menggunakan sesi Spark atau pernyataan SQL untuk memastikan konsistensi dengan katalog metadata.
-
-
(Opsional) Klik tab Version Information di sebelah kanan untuk membandingkan versi. Editor akan menyoroti perbedaan kode SQL antarversi.
-
-
Jalankan dan publikasikan pekerjaan.
-
Klik Run. Hasilnya muncul di tab Execution Results. Jika terjadi error, periksa tab Execution Issues. Panel riwayat eksekusi di sebelah kanan menampilkan catatan dari tiga hari terakhir.
-
Setelah memastikan pekerjaan berjalan dengan benar, klik Publish di pojok kanan atas.
-
Di kotak dialog Publish, masukkan catatan rilis lalu klik OK.
-
Akses Spark UI
Spark UI menampilkan status eksekusi tugas, penggunaan sumber daya, dan informasi log — berguna untuk menganalisis dan mengoptimalkan pekerjaan Spark Anda.
Akses dari hasil eksekusi
Metode ini memerlukan versi engine berikut atau yang lebih baru: esr-4.2.0 (esr-4.x), esr-3.2.0 (esr-3.x), atau esr-2.6.0 (esr-2.x).
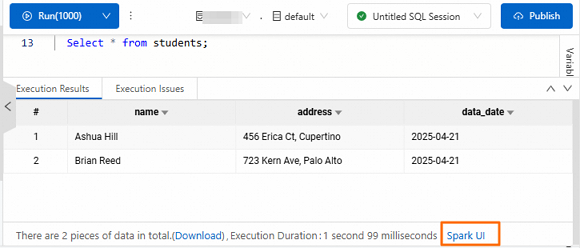
Setelah pernyataan SQL dijalankan, klik Spark UI di bagian bawah tab Execution Results.
Akses dari instans sesi
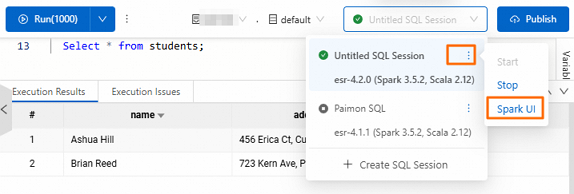
Setelah pernyataan SQL dijalankan, temukan instans sesi lalu pilih ![]() > Spark UI.
> Spark UI.
Pintasan keyboard
| Fungsi | Windows | Mac | Deskripsi |
|---|---|---|---|
| Run current script | Ctrl + Enter |
Control + Enter |
Menjalankan semua pernyataan SQL, atau hanya bagian yang dipilih. Sama seperti mengklik Run. |
| Format SQL | Ctrl + P |
Control + P |
Memformat struktur SQL: menstandarkan indentasi, jeda baris, dan kapitalisasi kata kunci. |
| Find text | Ctrl + F |
Control + F |
Mencari kata kunci dalam skrip saat ini. |
| Save task | Ctrl + S |
Control + S |
Menyimpan pekerjaan yang belum dipublikasikan saat ini untuk mencegah kehilangan data. |
Langkah berikutnya
Jadwalkan pekerjaan agar berjalan secara berkala dengan membuat alur kerja. Lihat Buat alur kerja. Untuk contoh penjadwalan lengkap, lihat Panduan cepat pengembangan Spark SQL.
FAQ
Apakah batas unduh 10.000 baris untuk hasil kueri dapat dilampaui?
Tidak. Unduhan hasil kueri di pengembangan data EMR Serverless Spark dibatasi oleh batas platform tetap. Anda dapat mengunduh maksimal 10.000 baris, dan ukuran file total tidak boleh melebihi 10 MB. Batas ini tidak dapat diubah melalui konfigurasi.
Untuk mengekspor set data yang lebih besar, gunakan salah satu metode berikut:
-
Kirimkan pekerjaan menggunakan spark-submit dan tulis hasilnya ke Object Storage Service (OSS) atau Hadoop Distributed File System (HDFS).
-
Gunakan tugas sinkronisasi offline di DataWorks untuk mengekspor data.
Apakah EMR Serverless Spark menyediakan API publik untuk Spark History?
Ya. EMR Serverless Spark menyediakan API publik. Untuk daftar lengkap operasi API yang tersedia, lihat Ikhtisar API.