Pemrosesan aliran sangat penting untuk analitik data besar secara real-time. EMR Serverless Spark adalah platform andal dan dapat diskalakan yang menyederhanakan pemrosesan data dengan menghilangkan kebutuhan pengelolaan server. Topik ini menjelaskan cara menggunakan EMR Serverless Spark untuk mengirim pekerjaan streaming PySpark, menyoroti kemudahan penggunaan dan pemeliharaannya dalam pemrosesan aliran.
Prasyarat
Anda telah membuat ruang kerja. Untuk informasi selengkapnya, lihat Create a workspace.
Prosedur
Langkah 1: Buat kluster Dataflow dan hasilkan pesan
-
Di halaman EMR on ECS, buat kluster Dataflow real-time yang mencakup layanan Kafka. Untuk informasi selengkapnya, lihat Create a cluster.
-
Login ke node master kluster EMR on ECS. Untuk informasi selengkapnya, lihat Log on to a cluster.
-
Jalankan perintah berikut untuk mengganti direktori:
cd /var/log/emr/taihao_exporter -
Jalankan perintah berikut untuk membuat topik:
# Create a topic named taihaometrics with 10 partitions and a replication factor of 2. kafka-topics.sh --partitions 10 --replication-factor 2 --bootstrap-server core-1-1:9092 --topic taihaometrics --create -
Jalankan perintah berikut untuk mengirim pesan:
# Use kafka-console-producer to send messages to the taihaometrics topic. tail -f metrics.log | kafka-console-producer.sh --broker-list core-1-1:9092 --topic taihaometrics
Langkah 2: Buat koneksi jaringan
-
Buka halaman Network Connection.
-
Di panel navigasi kiri Konsol EMR, pilih .
-
Di halaman Spark, klik nama ruang kerja target Anda.
-
Di halaman EMR Serverless Spark, klik Normal Network Connection di panel navigasi kiri.
-
-
Di halaman Normal Network Connection, klik Create Network Connection.
-
Di kotak dialog Create Network Connection, konfigurasikan parameter berikut lalu klik OK.
Parameter
Deskripsi
Name
Masukkan nama koneksi. Contohnya, connection_to_emr_kafka.
VPC
Pilih VPC tempat kluster EMR on ECS Anda dideploy.
Jika tidak tersedia VPC, klik Create VPC untuk membuka Konsol VPC dan membuat VPC. Untuk informasi selengkapnya, lihat Create and manage a VPC.
vSwitch
Pilih vSwitch yang berada dalam VPC yang sama dengan kluster EMR on ECS Anda.
Jika tidak tersedia vSwitch di zona saat ini, klik vSwitch untuk membuka Konsol VPC dan membuat vSwitch. Untuk informasi selengkapnya, lihat Create and manage a vSwitch.
Saat Status berubah menjadi Succeeded, koneksi jaringan telah berhasil dibuat.
Langkah 3: Tambahkan aturan grup keamanan
-
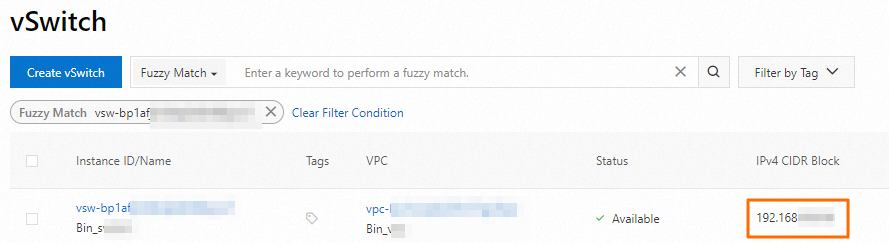
Dapatkan Blok CIDR vSwitch untuk node kluster.
Di halaman Nodes, klik nama grup node untuk menemukan vSwitch terkait. Kemudian, login ke Konsol VPC dan temukan Blok CIDR vSwitch tersebut di halaman vSwitch.
-
Tambahkan aturan grup keamanan.
-
Di halaman Clusters, klik ID kluster target.
-
Di halaman Basic Information, klik tautan di samping Cluster Security Group.
-
Di halaman Security Group Details, pada bagian Rules, klik Add Rule. Konfigurasikan parameter berikut lalu klik OK.
Parameter
Deskripsi
Source
Masukkan Blok CIDR vSwitch dari langkah sebelumnya.
PentingJangan atur nilai ini menjadi 0.0.0.0/0 karena akan membuka akses eksternal ke kluster.
Destination (current instance)
Masukkan port 9092.
-
Langkah 4: Unggah paket JAR ke OSS
Ekstrak kafka.zip dan unggah semua paket JAR dalam arsip tersebut ke OSS. Untuk informasi selengkapnya, lihat Simple upload.
Langkah 5: Unggah file resource
-
Di halaman EMR Serverless Spark, klik Artifacts di panel navigasi kiri.
-
Di halaman Artifacts, klik Upload File.
-
Di kotak dialog Upload File, klik area unggah lalu pilih file pyspark_ss_demo.py.
Langkah 6: Buat dan mulai pekerjaan streaming
-
Di halaman EMR Serverless Spark, klik Development di panel navigasi kiri.
-
Di tab Development, klik ikon
 .
. -
Masukkan nama, pilih sebagai jenis pekerjaan, lalu klik OK.
-
Di tab pengembangan baru, konfigurasikan parameter berikut, gunakan nilai default untuk parameter lainnya, lalu klik Save.
Parameter
Deskripsi
Main Python Resources
Pilih file pyspark_ss_demo.py yang telah Anda unggah pada halaman Resource Upload pada langkah sebelumnya.
Engine Version
Pilih versi Spark. Untuk informasi selengkapnya, lihat Engine versions.
Execution Parameters
Masukkan alamat IP internal node core-1-1 kluster. Anda dapat menemukan alamat IP ini pada halaman Nodes, dalam grup node Core.
Spark Configuration
Tentukan konfigurasi Spark. Berikut contohnya.
spark.jars oss://path/to/commons-pool2-2.11.1.jar,oss://path/to/kafka-clients-2.8.1.jar,oss://path/to/spark-sql-kafka-0-10_2.12-3.3.1.jar,oss://path/to/spark-token-provider-kafka-0-10_2.12-3.3.1.jar spark.emr.serverless.network.service.name connection_to_emr_kafkaCatatan-
spark.jars: Jalur OSS dari paket JAR eksternal yang diperlukan. Ganti jalur contoh dengan jalur OSS ke JAR yang telah Anda unggah di Langkah 4. -
spark.emr.serverless.network.service.name: Nama koneksi jaringan. Ganti nilai contoh dengan nama koneksi jaringan Anda dari Langkah 2.
-
-
Klik Publish.
-
Di kotak dialog Publish, klik OK.
-
Mulai pekerjaan streaming.
-
Klik Go to O&M.
-
Klik START.
-
Langkah 7: Lihat log
-
Klik tab Log Exploration.
-
Di tab Log Exploration, lihat detail eksekusi aplikasi dan hasilnya.

Topik terkait
Untuk contoh alur kerja pengembangan PySpark, lihat PySpark development quick start.