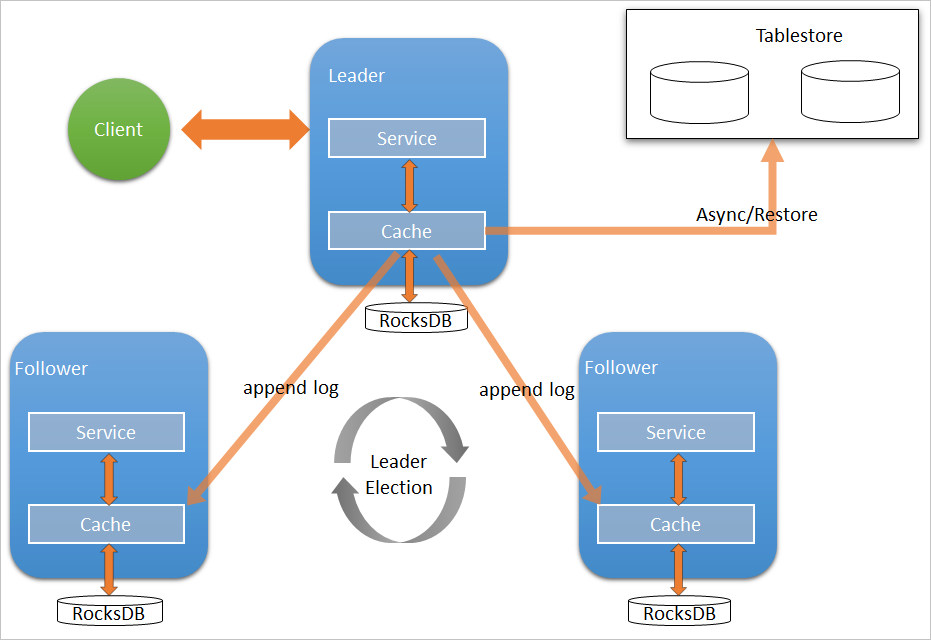
E-MapReduce (EMR) V3.27.0 dan versi yang lebih baru mendukung Raft-RocksDB-Tablestore sebagai backend penyimpanan metadata untuk JindoFS Namespace Service. Arsitektur ini menyediakan ketersediaan tinggi di tiga node master dan, secara opsional, cadangan penuh di luar kluster di Tablestore yang tetap tersedia meskipun kluster dihentikan.
Cara kerja
Arsitektur Raft-RocksDB-Tablestore terdiri atas tiga lapisan:
| Lapisan | Peran | Tanggung jawab |
|---|---|---|
| Konsensus Raft | Tiga node master membentuk grup Raft | Mereplikasi penulisan metadata ke mayoritas node sebelum mengonfirmasi keberhasilan. Dapat menoleransi satu kegagalan node tanpa kehilangan data. |
| Penyimpanan lokal RocksDB | Setiap node master | Menyimpan metadata secara lokal. Operasi baca dan tulis dilakukan ke RocksDB lokal, sehingga latensi tetap rendah. |
| Cadangan jarak jauh Tablestore | Penyimpanan opsional di luar kluster | EMR mengunggah perubahan metadata ke Tablestore secara asinkron dalam waktu nyata, membuat replika lengkap yang tetap ada setelah kluster dihentikan. |
Tiga node master diperlukan karena Raft membutuhkan kuorum (mayoritas) untuk melakukan commit penulisan. Dengan tiga node, kluster dapat menoleransi satu kegagalan node. Jumlah node kurang dari tiga tidak dapat membentuk grup Raft yang valid.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Membuat instans Tablestore. Kami merekomendasikan penggunaan instans kinerja tinggi yang telah mengaktifkan fitur transaksi. Untuk informasi selengkapnya, lihat Buat instans.
Memiliki kluster EMR dengan tiga node master. Untuk informasi selengkapnya, lihat Buat kluster.
Konfigurasikan Raft-RocksDB sebagai backend penyimpanan lokal
Langkah 1: Hentikan semua komponen SmartData
Masuk ke Konsol EMR Alibaba Cloud.
Pada bilah navigasi atas, pilih wilayah tempat kluster Anda berada dan pilih kelompok sumber daya.
Klik tab Cluster Management.
Temukan kluster Anda dan klik Details pada kolom Actions.
Pada panel navigasi kiri, pilih Cluster Service > SmartData.
Pada pojok kanan atas, pilih Stop All Components dari daftar drop-down Actions.
Langkah 2: Konfigurasikan parameter Namespace Service
Konfigurasikan parameter Namespace Service untuk mode penyimpanan blok. Untuk informasi selengkapnya, lihat Gunakan JindoFS dalam mode penyimpanan blok.
Langkah 3: Konfigurasikan parameter Raft pada tab bigboot
Pada panel navigasi kiri, pilih Cluster Service > SmartData.
Klik tab Configure.
Pada bagian Service Configuration, klik tab bigboot.
Atur parameter berikut:
Parameter Deskripsi Contoh namespace.backend.typeJenis penyimpanan backend untuk Namespace Service. Atur ke raft. Nilai yang valid:rocksdb,ots,raft. Default:rocksdb.raftnamespace.backend.raft.initial-confAlamat tiga node master tempat instans Raft berjalan. Tiga node diperlukan agar Raft dapat mencapai kuorum — kluster dapat menoleransi satu kegagalan node. Anda tidak dapat menggunakan jumlah node yang lebih sedikit. emr-header-1:8103:0,emr-header-2:8103:0,emr-header-3:8103:0jfs.namespace.server.rpc-addressAlamat tiga node master yang digunakan klien untuk mengakses instans Raft. emr-header-1:8101,emr-header-2:8101,emr-header-3:8101
Langkah 4 (opsional): Konfigurasikan Tablestore sebagai backend cadangan jarak jauh
Lewati langkah ini jika Anda tidak memerlukan pencadangan metadata di luar kluster.
Pada tab bigboot, atur parameter berikut:
| Parameter | Deskripsi | Contoh |
|---|---|---|
namespace.ots.instance | Nama instans Tablestore. | emr-jfs |
namespace.ots.accessKey | ID AccessKey yang digunakan untuk mengakses Tablestore. | kkkkkk |
namespace.ots.accessSecret | Rahasia AccessKey yang digunakan untuk mengakses Tablestore. | XXXXXX |
namespace.ots.endpoint | Titik akhir instans Tablestore. Gunakan titik akhir VPC agar trafik tetap berada dalam jaringan pribadi. | http://emr-jfs.cn-hangzhou.vpc.tablestore.aliyuncs.com |
namespace.backend.raft.async.ots.enabled | Aktifkan unggahan asinkron ke Tablestore. Atur ke true. Anda harus mengatur ini sebelum inisialisasi SmartData selesai. Jika inisialisasi telah selesai, metadata telah ditulis ke RocksDB lokal dan pengaturan ini tidak berpengaruh. | true |
Langkah 5: Simpan konfigurasi dan mulai semua komponen
Pada pojok kanan atas bagian Service Configuration, klik Save.
Pada kotak dialog Confirm Changes, masukkan deskripsi dan aktifkan Auto-update Configuration.
Klik OK.
Pada pojok kanan atas, pilih Start All Components dari daftar drop-down Actions.
Pulihkan metadata dari Tablestore
Jika Anda mengonfigurasi Tablestore sebagai backend cadangan jarak jauh, Tablestore menyimpan replika lengkap metadata JindoFS. Setelah kluster EMR asli dihentikan atau dirilis, Anda dapat memulihkan metadata ke kluster baru untuk mengakses kembali file-file aslinya.
Langkah 1 (opsional): Persiapkan pemulihan
Catat statistik metadata kluster asli agar Anda dapat memverifikasi hasil pemulihan nanti:
hadoop fs -count jfs://test/ 1596 1482809 25 jfs://test/ (Jumlah folder) (Jumlah file)Hentikan semua pekerjaan yang sedang berjalan di kluster asli. Tunggu 30–120 detik agar EMR menyinkronkan semua metadata ke Tablestore. Jalankan perintah berikut untuk memeriksa status sinkronisasi:
jindo jfs -metaStatus -detailSaat output menampilkan
_synced=1untuk node Leader, semua metadata telah disinkronkan ke Tablestore.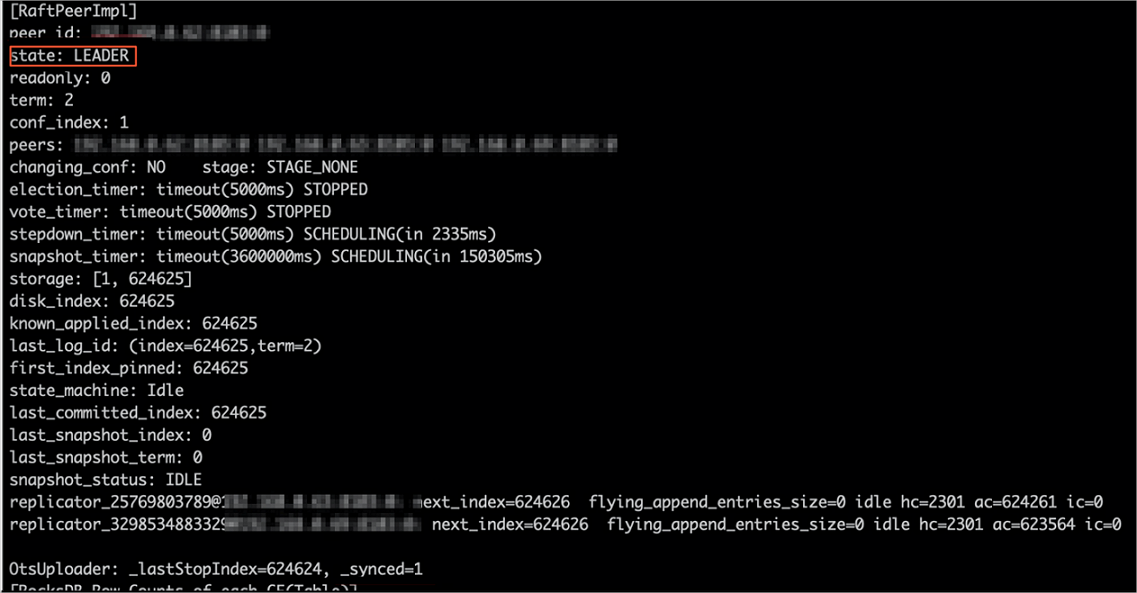
Hentikan atau rilis kluster asli. Pastikan tidak ada kluster lain yang mengakses instans Tablestore sebelum melanjutkan.
Jika Anda menghentikan kluster sebelum sinkronisasi selesai (_synced=1 belum muncul), metadata yang ditulis setelah titik sinkronisasi terakhir tidak akan tersedia setelah pemulihan. Selalu konfirmasi sinkronisasi sebelum menghentikan kluster.
Langkah 2: Buat kluster EMR baru
Buat kluster EMR di wilayah yang sama dengan instans Tablestore. Lalu hentikan semua komponen SmartData. Untuk detailnya, lihat Langkah 1 dalam Konfigurasikan Raft-RocksDB sebagai backend penyimpanan lokal.
Langkah 3: Atur parameter pemulihan
Pada tab bigboot untuk layanan SmartData, atur parameter berikut:
| Parameter | Deskripsi | Nilai yang diperlukan |
|---|---|---|
namespace.backend.raft.async.ots.enabled | Nonaktifkan unggahan asinkron ke Tablestore selama pemulihan. Mengatur nilai ini ke false mencegah penulisan ke Tablestore saat metadata sedang dipulihkan, sehingga menghindari inkonsistensi data. | false |
namespace.backend.raft.recovery.mode | Aktifkan pemulihan metadata dari Tablestore. | true |
Langkah 4: Simpan konfigurasi dan mulai semua komponen
Pada pojok kanan atas bagian Service Configuration, klik Save.
Pada kotak dialog Confirm Changes, masukkan deskripsi dan aktifkan Auto-update Configuration.
Klik OK.
Pada pojok kanan atas, pilih Start All Components dari daftar drop-down Actions.
Langkah 5: Pantau progres pemulihan
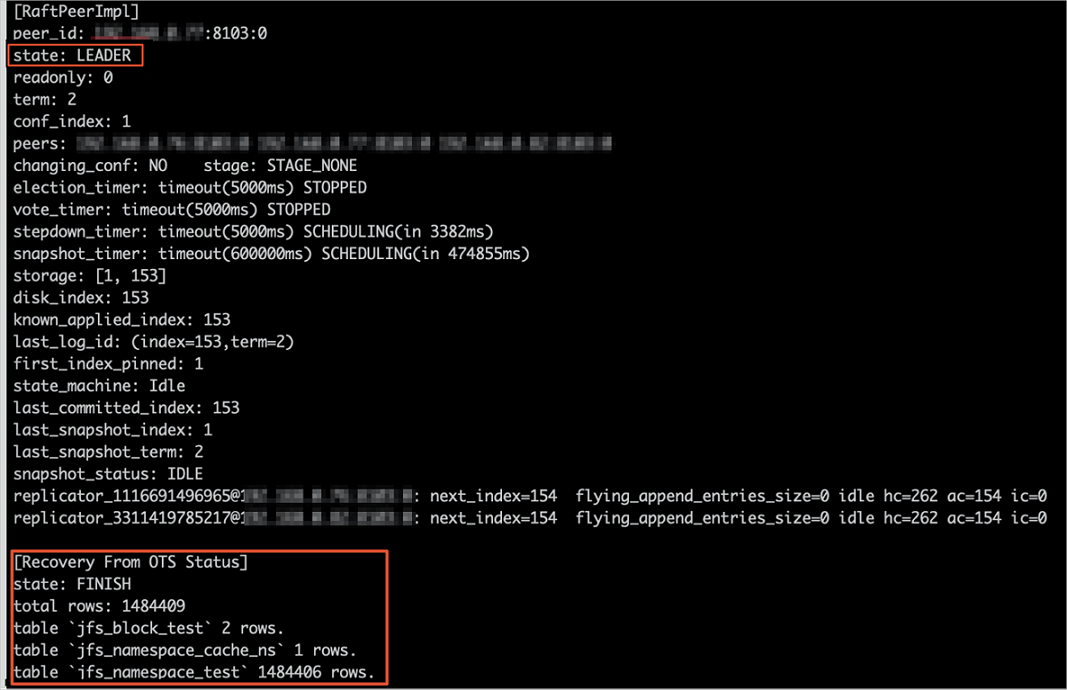
Setelah SmartData dimulai, EMR secara otomatis menarik metadata dari Tablestore ke Raft-RocksDB lokal. Jalankan perintah berikut untuk memeriksa progres:
jindo jfs -metaStatus -detailSaat status node Leader adalah FINISH, pemulihan selesai.
Kluster bersifat read-only selama pemulihan. Operasi tulis akan mengembalikan error berikut: Ini merupakan perilaku yang diharapkan. Kluster menerapkan mode read-only untuk mencegah penulisan baru menimpa data yang belum dipulihkan, yang dapat menyebabkan inkonsistensi.
java.io.IOException: ErrorCode : 25021 , ErrorMsg: Namespace is under recovery mode, and is read-only.Langkah 6 (opsional): Verifikasi jumlah file dan folder
Jalankan perintah berikut untuk memastikan metadata konsisten dengan kluster asli:
# Verifikasi jumlah file dan folder sesuai dengan kluster asli
[hadoop@emr-header-1 ~]$ hadoop fs -count jfs://test/
1596 1482809 25 jfs://test/
# Baca isi file
[hadoop@emr-header-1 ~]$ hadoop fs -cat jfs://test/testfile
this is a test file
# Daftar direktori
[hadoop@emr-header-1 ~]$ hadoop fs -ls jfs://test/
Found 3 items
drwxrwxr-x - root root 0 2020-03-25 14:54 jfs://test/emr-header-1.cluster-50087
-rw-r----- 1 hadoop hadoop 5 2020-03-25 14:50 jfs://test/haha-12096RANDOM.txt
-rw-r----- 1 hadoop hadoop 20 2020-03-25 15:07 jfs://test/testfileLangkah 7: Keluar dari mode pemulihan
Setelah memverifikasi metadata, aktifkan kembali unggahan asinkron ke Tablestore dan nonaktifkan mode pemulihan.
Pada tab bigboot, perbarui parameter berikut:
| Parameter | Deskripsi | Nilai yang diperlukan |
|---|---|---|
namespace.backend.raft.async.ots.enabled | Aktifkan kembali unggahan asinkron agar kluster baru mulai mencadangkan ke Tablestore. | true |
namespace.backend.raft.recovery.mode | Nonaktifkan mode pemulihan agar kluster menjadi dapat ditulis. | false |
Lalu restart kluster:
Klik tab Cluster Management.
Temukan kluster tersebut. Pada kolom Actions, klik More dan pilih Restart.
Referensi cepat: perintah utama
| Tugas | Perintah |
|---|---|
| Periksa status sinkronisasi dan pemulihan metadata | jindo jfs -metaStatus -detail |
| Hitung jumlah file dan folder | hadoop fs -count jfs://test/ |
| Baca file | hadoop fs -cat jfs://test/<filename> |
| Daftar direktori | hadoop fs -ls jfs://test/ |
FAQ
Apa yang terjadi jika saya menghentikan kluster asli sebelum sinkronisasi selesai?
Metadata yang ditulis setelah checkpoint terakhir yang disinkronkan tidak akan tersedia setelah pemulihan. Untuk meminimalkan kehilangan data, selalu pastikan bahwa _synced=1 muncul untuk node Leader dalam output jindo jfs -metaStatus -detail sebelum menghentikan kluster.
Bisakah saya menggunakan dua node master alih-alih tiga?
Tidak. Raft memerlukan kuorum (mayoritas node) untuk melakukan commit penulisan. Dengan dua node, satu kegagalan menyebabkan tidak adanya mayoritas, sehingga grup Raft tidak dapat berfungsi. Tiga adalah jumlah minimum node untuk grup Raft yang valid yang dapat menoleransi satu kegagalan.
Mengapa kluster bersifat read-only selama pemulihan?
Mode pemulihan mencegah operasi tulis untuk menghindari penimpaan data yang belum dipulihkan dari Tablestore. Jika penulisan diizinkan, metadata yang dipulihkan kemudian dapat bertentangan dengan atau menimpa data yang lebih baru, menyebabkan inkonsistensi. Kluster secara otomatis keluar dari mode read-only setelah Anda menyelesaikan Langkah 7 dan me-restart kluster.
Apa yang terjadi jika pemulihan gagal di tengah proses?
Jika pemulihan terganggu, restart kluster baru dengan namespace.backend.raft.recovery.mode=true lagi. EMR melanjutkan penarikan metadata dari Tablestore. Periksa progres dengan jindo jfs -metaStatus -detail dan tunggu hingga status node Leader mencapai FINISH sebelum melanjutkan.
Bisakah beberapa kluster berbagi instans Tablestore yang sama?
Tidak. Sebelum memulai pemulihan di kluster baru, hentikan atau rilis semua kluster yang mengakses instans Tablestore tersebut. Beberapa kluster yang menulis atau membaca dari instans Tablestore yang sama secara bersamaan dapat merusak cadangan metadata.