Anda dapat menyimpan data HBase di OSS-HDFS untuk kluster DataServing guna memisahkan komputasi dari penyimpanan. Data Write-Ahead Logging (WAL) tetap berada di HDFS.
Latar Belakang
OSS-HDFS adalah layanan penyimpanan data lake cloud-native dengan manajemen metadata terpadu, kompatibilitas penuh dengan API HDFS, dan dukungan POSIX yang komprehensif. Layanan ini sangat cocok untuk skenario komputasi data besar dan AI computing dalam arsitektur data lake. Untuk informasi selengkapnya, lihat Apa itu OSS-HDFS?.
Gambar berikut menunjukkan arsitektur HBase di atas OSS-HDFS.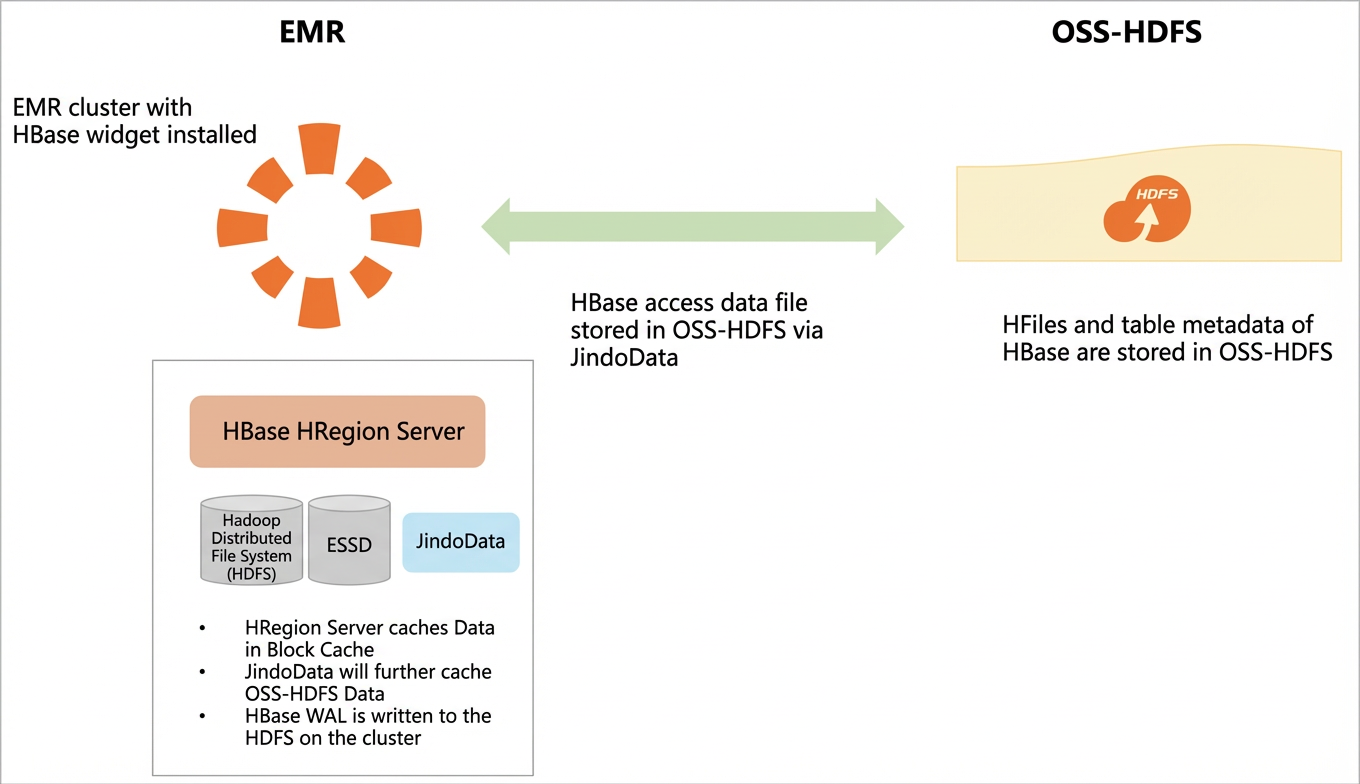
Batasan
Hanya didukung pada kluster DataServing yang menjalankan E-MapReduce 3.42 atau versi lebih baru, atau E-MapReduce 5.8.0 atau versi lebih baru.
Prosedur
-
Aktifkan OSS-HDFS dan berikan izin akses yang diperlukan. Untuk instruksi lengkap, lihat Aktifkan OSS-HDFS dan berikan izin akses.
-
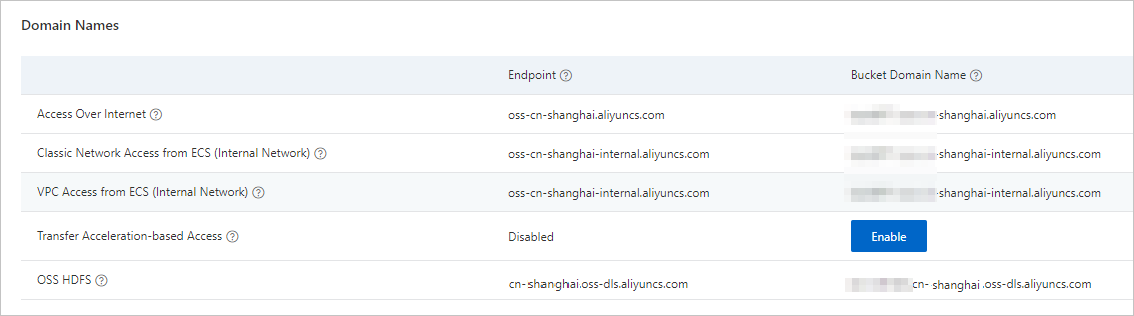
Dapatkan titik akhir layanan OSS-HDFS.
Di Konsol OSS, buka halaman Overview dan salin titik akhir untuk layanan OSS-HDFS. Gunakan titik akhir ini sebagai nilai parameter hbase.rootdir saat membuat kluster HBase E-MapReduce.
-
Gunakan OSS-HDFS.
-
Buat kluster DataServing. Untuk informasi selengkapnya, lihat Buat kluster.
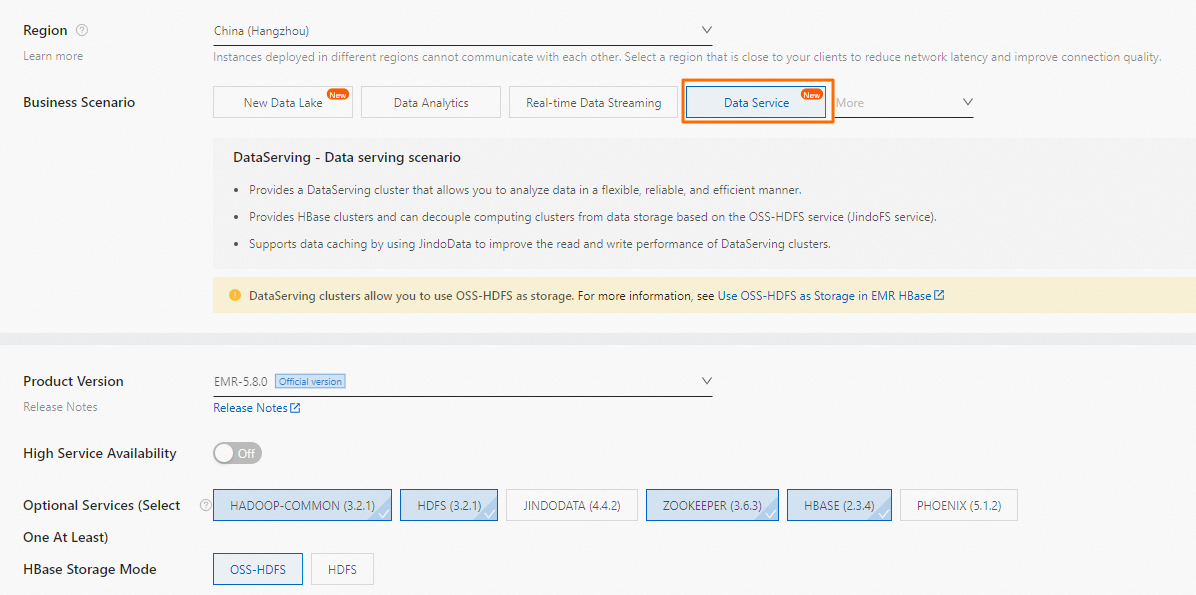 Saat membuat kluster DataServing, konfigurasikan parameter berikut:
Saat membuat kluster DataServing, konfigurasikan parameter berikut:-
Optional Services: Pilih semua layanan kecuali JindoData dan Phoenix.
-
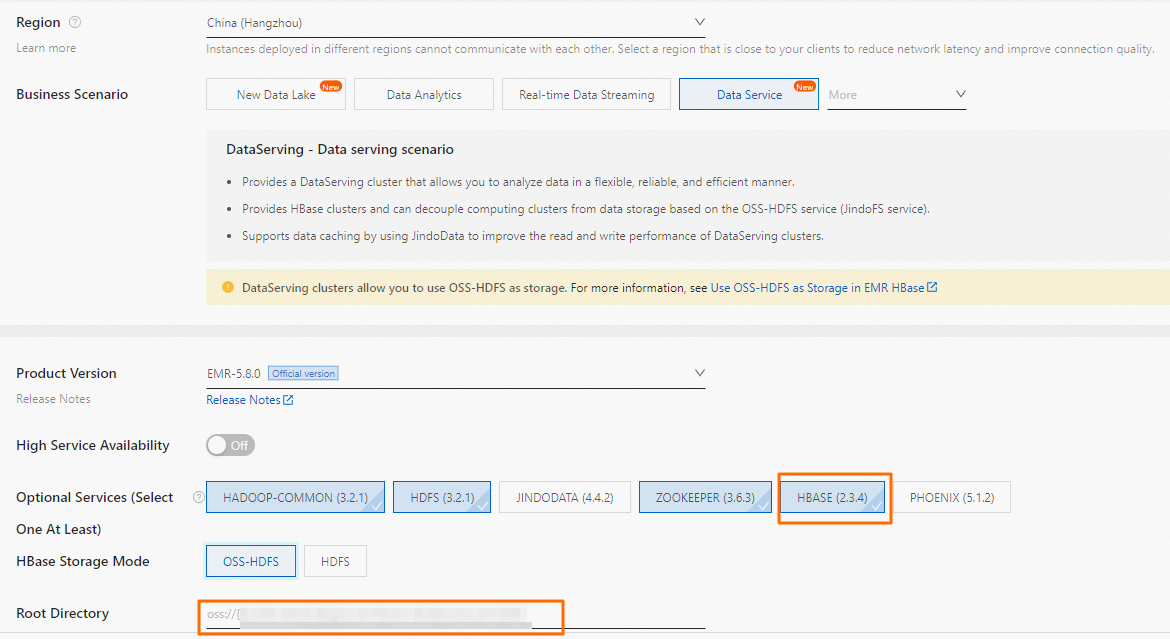
HBase Storage Mode: Pilih OSS-HDFS.
-
Root Directory: Tentukan bucket OSS yang telah mengaktifkan layanan HDFS. Gunakan format oss://${OSS-HDFS_ENDPOINT}/${DIR}. Contohnya, oss://test_bucket.cn-hangzhou.oss-dls.aliyuncs.com/hbase.
CatatanGanti placeholder berikut:
-
${OSS-HDFS_ENDPOINT}: Titik akhir OSS-HDFS yang Anda peroleh di Langkah 2.
-
${DIR}: Direktori root untuk HBase.
-
-
Buat tabel HBase.
-
Login ke kluster DataServing. Untuk informasi selengkapnya, lihat Login ke kluster.
-
Jalankan perintah berikut untuk memulai HBase Shell:
hbase shell -
Jalankan perintah berikut untuk membuat tabel uji bernama
bardengan nama keluarga kolomf:create 'bar','f'Setelah membuat tabel, Anda dapat menjalankan perintah
listuntuk melihat daftar tabel Anda.Contoh output:
TABLE bar 1 row(s) Took 0.0138 seconds
-
-
Keluar dari HBase Shell dan jalankan perintah berikut untuk memverifikasi bahwa data tabel disimpan di OSS-HDFS.
Sintaks:
hadoop fs -ls oss://${OSS-HDFS_ENDPOINT}/${DIR}Contoh:
hadoop fs -ls oss://test_bucket.cn-hangzhou.oss-dls.aliyuncs.com/hbase/data/defaultOutput serupa berikut mengonfirmasi bahwa direktori untuk tabel HBase telah dibuat di OSS-HDFS:
Found 1 items drwxrwxrwx - hbase supergroup 0 2022-07-28 14:45 oss://test_bucket.cn-hangzhou.oss-dls.aliyuncs.com/hbase/data/default/bar
-
-
Opsional: Hentikan dan pulihkan kluster.
Karena OSS-HDFS memisahkan komputasi dari penyimpanan, Anda dapat menghentikan kluster asli dan membuat kluster baru yang membaca data yang sama dari direktori OSS-HDFS yang sama.
Penting-
Kluster baru dan kluster asli harus menggunakan versi HBase yang sama. Ketidaksesuaian versi dapat menyebabkan masalah kompatibilitas yang tidak terduga dan berpotensi membuat kluster baru tidak dapat digunakan.

-
Penulisan data secara bersamaan dari beberapa kluster dapat menyebabkan inkonsistensi metadata atau data, merusak data Anda, dan membuat kluster tidak tersedia.
-
Login ke kluster DataServing. Untuk informasi selengkapnya, lihat Login ke kluster.
-
Mulai HBase Shell.
hbase shell -
Jalankan perintah
flushuntuk menulis semua data dalam memori tabel Anda ke HFile.flush 'bar' -
Jalankan perintah
disablepada tabel Anda untuk mencegah penulisan data baru.disable 'bar' -
Buat kluster baru. Pastikan kluster tersebut menggunakan versi HBase yang sama dengan kluster asli dan dikonfigurasi untuk menggunakan direktori OSS-HDFS yang sama sebagai backend penyimpanannya.
Kluster baru secara otomatis memulihkan data dari OSS-HDFS dan siap digunakan.
-