JindoFS adalah sistem file cloud-native untuk E-MapReduce (EMR) yang menggunakan Object Storage Service (OSS) sebagai backend penyimpanannya, dikombinasikan dengan cache pada disk lokal dan layanan metadata khusus. Gunakan JindoFS ketika Anda memerlukan performa metadata setara HDFS serta penyimpanan elastis yang dapat diskalakan secara independen dari klaster komputasi Anda.
Topik ini mencakup EMR V3.20.0 hingga V3.22.0 (V3.22.0 tidak termasuk). Untuk EMR V3.22.0 dan versi setelahnya, lihat Gunakan JindoFS di EMR V3.22.0 hingga V3.26.3.
Cara kerja
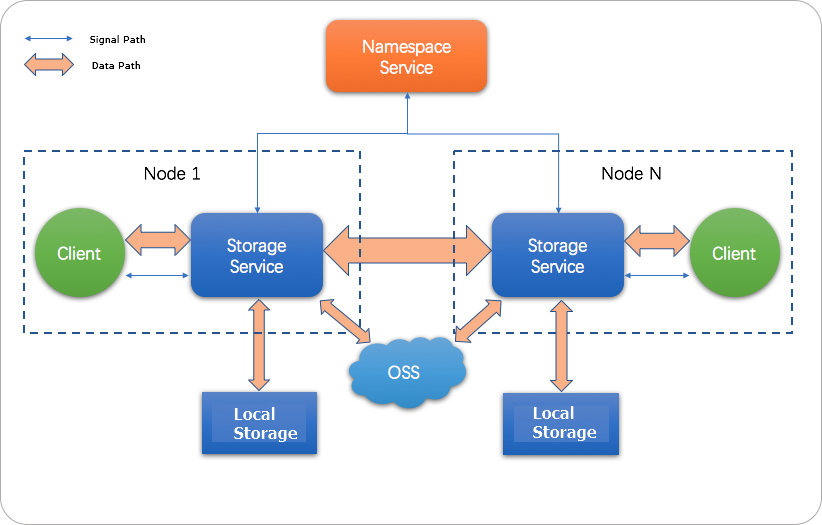
JindoFS menggunakan dua layanan internal untuk memisahkan penyimpanan dari metadata:
-
Storage Service menulis data ke OSS, memastikan keandalan tinggi melalui redundansi bawaan OSS. Data yang sering diakses juga di-cache pada disk lokal klaster untuk mempercepat pembacaan.
-
Namespace Service mengelola metadata file secara lokal. Kueri metadata dialihkan ke Namespace Service alih-alih ke OSS, sehingga performa kueri metadata JindoFS mirip dengan Hadoop Distributed File System (HDFS).
JindoFS mendukung dua mode penyimpanan: block storage mode dan cache mode. Topik ini membahas block storage mode.
Pilih sistem penyimpanan
EMR menyediakan tiga sistem penyimpanan: OssFileSystem, HDFS, dan JindoFS. OssFileSystem dan JindoFS sama-sama menggunakan OSS sebagai backend penyimpanannya.
| Fitur | Hadoop OSS | EMR OssFileSystem | EMR HDFS | EMR JindoFS |
|---|---|---|---|---|
| Kapasitas penyimpanan | Sangat besar | Sangat besar | Tergantung skala klaster | Sangat besar |
| Keandalan | Tinggi | Tinggi | Tinggi | Tinggi |
| Faktor throughput | Server | I/O disk cache | I/O disk | I/O disk |
| Efisiensi kueri metadata | Rendah | Sedang | Tinggi | Tinggi |
| Scale-out | Mudah | Mudah | Mudah | Mudah |
| Scale-in | Mudah | Mudah | Penonaktifan node diperlukan | Mudah |
| Lokalitas data | Tidak ada | Lemah | Kuat | Sedang |
Kapan menggunakan JindoFS (block storage mode):
-
Volume kueri metadata tinggi: JindoFS memberikan performa metadata setara HDFS, sehingga cocok untuk beban kerja yang sering melakukan list, stat, atau rename file.
-
Data berskala besar dengan klaster elastis: Penyimpanan dapat diskalakan secara independen dari klaster. Skalakan klaster naik atau turun tanpa perlu decommission node atau migrasi data.
-
Beban kerja Write Once Read Many (WORM): Cache pada disk lokal mempercepat pembacaan berulang pada dataset tetap.
-
Lokalitas data penting: JindoFS menyimpan cadangan lokal pada node yang awalnya menulis data tersebut, sehingga mengurangi I/O jaringan saat pembacaan berikutnya.
Prasyarat
Sebelum memulai, pastikan Anda telah:
-
Membuat klaster EMR yang menjalankan V3.20.0 hingga V3.22.0 (V3.22.0 tidak termasuk), dengan SmartData dan Bigboot dipilih saat pembuatan klaster. Untuk petunjuknya, lihat Buat klaster.
-
Membuat bucket OSS. Simpan bucket tersebut di wilayah yang sama dengan klaster EMR Anda untuk memastikan performa dan stabilitas tinggi, serta mengaktifkan akses tanpa password tanpa perlu mengonfigurasi pasangan AccessKey.
Bigboot menyediakan layanan manajemen data terdistribusi dan manajemen komponen. SmartData dibangun di atas Bigboot untuk mengekspos JindoFS ke lapisan aplikasi.
Konfigurasi JindoFS
Tersedia dua metode konfigurasi. Gunakan metode pasca-pembuatan jika klaster sudah ada, atau metode pra-pembuatan untuk mengotomatiskan konfigurasi saat startup klaster.
Konfigurasi setelah pembuatan klaster
-
Di Konsol EMR, buka halaman konfigurasi Bigboot untuk klaster Anda.
-
Atur parameter berikut. Parameter yang diberi bingkai merah di konsol bersifat wajib.
CatatanJindoFS mendukung multiple namespace. Contoh dalam topik ini menggunakan namespace bernama
test.Parameter Deskripsi Contoh oss.access.bucketNama bucket OSS yang digunakan sebagai backend penyimpanan JindoFS. my-emr-bucketoss.data-dirDirektori dalam bucket tempat JindoFS menyimpan data. Direktori ini dibuat otomatis saat penulisan pertama — jangan buat sebelumnya. jindoFS-1oss.access.endpointTitik akhir wilayah tempat bucket OSS berada. oss-cn-hangzhou-internal.aliyuncs.comoss.access.keyID AccessKey untuk akses OSS. Kosongkan jika bucket berada di wilayah yang sama dengan klaster (akses tanpa password). — oss.access.secretRahasia AccessKey untuk akses OSS. Kosongkan jika bucket berada di wilayah yang sama dengan klaster (akses tanpa password). — 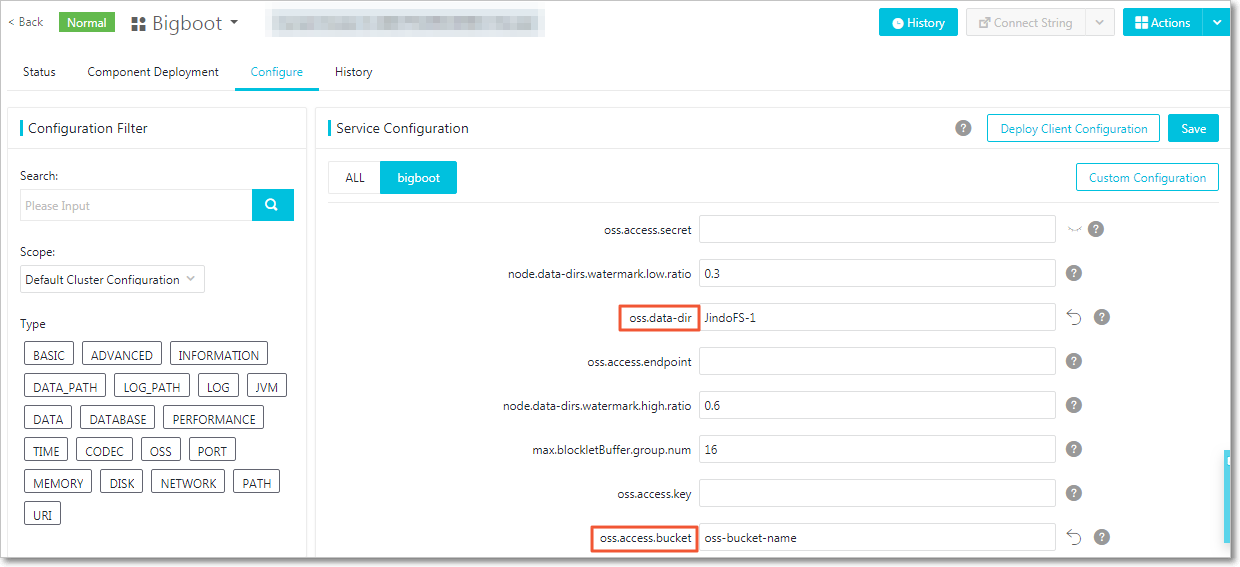
-
Simpan dan deploy konfigurasi.
-
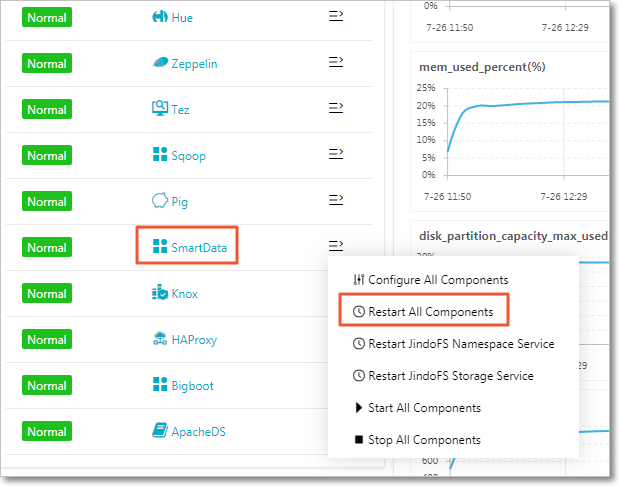
Restart semua komponen SmartData agar perubahan berlaku.


Konfigurasi saat pembuatan klaster
Teruskan parameter Bigboot sebagai konfigurasi kustom saat membuat klaster. Klaster akan menerapkan pengaturan tersebut secara otomatis setelah startup.
-
Di halaman pembuatan klaster, aktifkan Custom Software Settings.
-
Di bagian Advanced Settings, tambahkan JSON berikut. Ganti nilai-nilainya dengan nama bucket OSS dan direktori data Anda.
[ { "ServiceName": "BIGBOOT", "FileName": "bigboot", "ConfigKey": "oss.data-dir", "ConfigValue": "jindoFS-1" }, { "ServiceName": "BIGBOOT", "FileName": "bigboot", "ConfigKey": "oss.access.bucket", "ConfigValue": "oss-bucket-name" } ]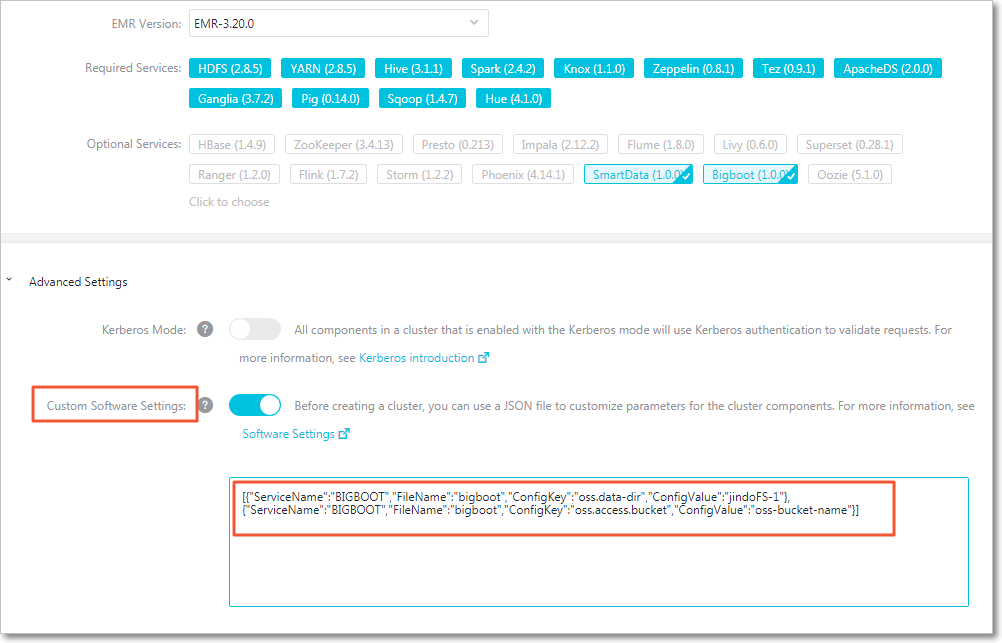
-
Selesaikan pembuatan klaster. SmartData akan restart secara otomatis dan menerapkan konfigurasi.

Gunakan JindoFS
JindoFS menggunakan awalan URI jfs://, dengan sintaks perintah yang sama seperti HDFS.
List direktori:
hadoop fs -ls jfs:///Buat direktori:
hadoop fs -mkdir jfs:///test-dirUnggah file:
hadoop fs -put test.log jfs:///test-dir/Data hanya dapat dibaca dari JindoFS ketika pekerjaan Hadoop, Hive, dan Spark sedang berjalan di klaster EMR.
Manage disk space
JindoFS menyimpan cache data pada disk lokal untuk mempercepat pembacaan. Karena kapasitas disk lokal terbatas, JindoFS secara otomatis menghapus data dingin menggunakan mekanisme high-watermark/low-watermark.
Konfigurasikan parameter watermark di Bigboot:
| Parameter | Deskripsi |
|---|---|
node.data-dirs.watermark.high.ratio |
Batas atas penggunaan disk space per data disk (0–1). Saat penggunaan mencapai rasio ini, JindoFS mulai menghapus blok lokal yang paling jarang diakses. |
node.data-dirs.watermark.low.ratio |
Batas bawah penggunaan disk space per data disk (0–1). Penghapusan berlanjut hingga penggunaan turun ke rasio ini. |
Secara default, JindoFS menggunakan total kapasitas semua data disk. Atur rasio high di atas rasio low — nilai yang terbalik akan menyebabkan error konfigurasi.
Konfigurasi kebijakan penyimpanan
JindoFS menyediakan empat kebijakan penyimpanan yang mengontrol jumlah salinan file yang disimpan di OSS dan pada disk lokal. Kebijakan default adalah WARM.
| Kebijakan | Cadangan OSS | Cadangan lokal | Paling cocok untuk |
|---|---|---|---|
| COLD | Ya | Tidak ada | Data arsip yang jarang diakses |
| WARM | Ya | 1 | Beban kerja tujuan umum (default) |
| HOT | Ya | Multiple | Data panas yang sering dibaca |
| TEMP | Tidak | 1 | Data sementara; I/O lebih cepat, keandalan lebih rendah |
File baru mewarisi kebijakan penyimpanan dari direktori induknya.
Tetapkan kebijakan penyimpanan:
jindo dfsadmin -R -setStoragePolicy <path> <policy>-
<path>: Direktori target. -
<policy>: Salah satu dariCOLD,WARM,HOT, atauTEMP. -
-R: Menerapkan kebijakan secara rekursif ke semua subdirektori.
Dapatkan kebijakan penyimpanan saat ini:
jindo dfsadmin -getStoragePolicy <path>Arsipkan data dingin (hapus blok lokal):
Gunakan perintah archive untuk secara eksplisit menghapus blok lokal sambil tetap menyimpan salinan di OSS. Ini berguna untuk tabel partisi di mana partisi lama tidak lagi sering diakses.
jindo dfsadmin -archive <path>Sebagai contoh, jika Hive mempartisi tabel berdasarkan hari, jalankan perintah archive mingguan pada direktori yang berusia lebih dari tujuh hari untuk membebaskan ruang disk lokal tanpa menghapus data dari OSS.