Spark Load memindahkan beban prapemrosesan data ke kluster Spark eksternal sebelum mengimpor data ke StarRocks. Pendekatan ini mengurangi beban komputasi pada kluster StarRocks dan direkomendasikan untuk migrasi awal atau impor skala besar dalam kisaran terabyte (TB).
Akun pengguna harus memiliki izin USAGE-PRIV pada resource Spark sebelum mengirimkan pekerjaan impor apa pun.
Cara kerja
Spark Load adalah metode impor asinkron. Kirim pekerjaan menggunakan protokol MySQL dan periksa hasilnya dengan SHOW LOAD.
Gambar berikut menunjukkan alur kerjanya.
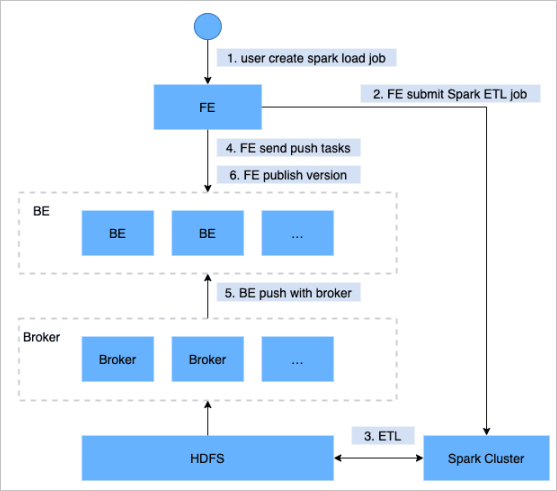
Kirim pekerjaan Spark Load ke node frontend.
Node frontend menjadwalkan dan mengirimkan pekerjaan ekstrak, transformasi, dan muat (ETL) ke kluster Spark.
Kluster Spark menjalankan pekerjaan ETL: membuat kamus global bitmap, serta mempartisi, mengurutkan, dan mengagregasi data.
Setelah pekerjaan ETL selesai, node frontend mengidentifikasi direktori data yang telah dipraproses untuk setiap partisi dan menjadwalkan node backend untuk menjalankan pekerjaan dorong (push).
Node backend menggunakan Broker untuk membaca data dari Hadoop Distributed File System (HDFS) dan mengonversinya ke format yang disimpan secara internal oleh StarRocks.
Node frontend menerbitkan versi StarRocks baru dan menandai pekerjaan impor sebagai selesai.
Konsep utama
Spark ETL Program Spark yang melakukan operasi ETL pada data sebelum impor. Program ini menangani pembuatan kamus global, partisi data, pengurutan, dan agregasi.
Broker Proses tanpa status yang membungkus antarmuka sistem file, memungkinkan StarRocks membaca file dari sistem penyimpanan jarak jauh seperti HDFS.
Kamus global Struktur data yang memetakan nilai mentah ke bilangan bulat terenkripsi. Kamus global digunakan untuk menghitung sebelumnya kolom bitmap sebelum impor. Kolom bitmap StarRocks menggunakan roaring bitmaps, yang memerlukan input bilangan bulat.
Alur kerja kamus global
Kolom bitmap di StarRocks memerlukan input bilangan bulat. Kamus global menangani konversi ini:
Baca data sumber dan simpan dalam tabel Hive sementara (
hive-table).Hilangkan duplikasi nilai dari
hive-tableke tabel bernamadistinct-value-table.Buat tabel kamus (
dict-table) dengan satu kolom untuk nilai mentah dan satu kolom untuk bilangan bulat terenkripsi.Lakukan LEFT JOIN antara
distinct-value-tabledengandict-table, terapkan fungsi jendela untuk mengenkripsi nilai mentah baru, lalu tulis hasilnya kembali kedict-table.Lakukan JOIN antara
dict-tabledenganhive-tableuntuk mengganti nilai mentah dengan bilangan bulat terenkripsinya.Meneruskan data
hive-tableyang telah dikodekan ke langkah-langkah ETL berikutnya dan mengimpornya ke StarRocks.
Kamus global hanya didukung saat mengimpor dari tabel Hive.
Prapemrosesan data
Setelah kamus global dibuat (jika berlaku), Spark melakukan prapemrosesan data:
Baca data dari file HDFS atau tabel Hive.
Terapkan pemetaan bidang dan perhitungan berbasis ekspresi. Hasilkan bidang
bucket-idberdasarkan informasi partisi.Bangun pohon rollup dari metadata rollup di tabel StarRocks.
Jelajahi pohon rollup dan agregasi data lapis demi lapis, dengan setiap lapis dihitung dari lapis sebelumnya.
Distribusikan data yang telah diagregasi ke bucket berdasarkan
bucket-iddan tulis ke HDFS.Broker membaca file HDFS dan mendorong data ke node backend StarRocks.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
Kluster EMR dengan kluster Spark yang sedang berjalan dan YARN ResourceManager
Broker yang dikonfigurasi di StarRocks (
ALTER SYSTEM ADD BROKER)Izin
USAGE-PRIVyang diberikan pada resource Spark eksternalSpark 2.4.5 atau versi 2.x terbaru yang telah diunduh dan disimpan di node frontend
Hadoop 2.5.2 atau versi 2.x terbaru yang telah diunduh dan disimpan di node frontend
Menyiapkan Spark Load
Lakukan langkah-langkah berikut secara berurutan: buat resource Spark eksternal → konfigurasikan klien Spark → konfigurasikan klien YARN → kirim pekerjaan impor.
Langkah 1: Buat resource Spark eksternal
Daftarkan kluster Spark sebagai resource eksternal di StarRocks agar node frontend dapat mengirimkan pekerjaan ETL ke kluster tersebut.
Sintaks
CREATE EXTERNAL RESOURCE "resource_name"
PROPERTIES
(
"type" = "spark",
"spark.master" = "yarn",
"spark.submit.deployMode" = "<cluster|client>",
"spark.hadoop.fs.defaultFS" = "hdfs://<namenode-host>:<port>",
"spark.hadoop.yarn.resourcemanager.address" = "<resourcemanager-host>:8032",
"working_dir" = "hdfs://<namenode-host>:<port>/tmp/starrocks",
"broker" = "<broker-name>",
"broker.username" = "<username>",
"broker.password" = "<password>"
);Properti resource
| Properti | Wajib | Deskripsi |
|---|---|---|
type | Ya | Diatur ke spark. |
spark.master | Ya | Diatur ke yarn. |
spark.submit.deployMode | Ya | Mode deploy untuk program Spark. Nilai yang valid: cluster, client. |
spark.hadoop.fs.defaultFS | Ya | Diperlukan ketika spark.master adalah yarn. |
spark.hadoop.yarn.resourcemanager.address | Tidak | Alamat YARN ResourceManager, dalam format host:port. |
spark.hadoop.yarn.resourcemanager.ha.enabled | Tidak | Diatur ke true untuk mengaktifkan Ketersediaan tinggi pada ResourceManager. Nilai default: true. |
spark.hadoop.yarn.resourcemanager.ha.rm-ids | Tidak | ID logis ResourceManagers (untuk HA). |
spark.hadoop.yarn.resourcemanager.hostname.rm-id | Tidak | Hostname yang sesuai dengan setiap ID logis. Konfigurasikan salah satu dari ini atau spark.hadoop.yarn.resourcemanager.address.rm-id. |
spark.hadoop.yarn.resourcemanager.address.rm-id | Tidak | Alamat (host:port) yang sesuai dengan setiap ID logis. Konfigurasikan salah satu dari ini atau spark.hadoop.yarn.resourcemanager.hostname.rm-id. |
working_dir | Ya (untuk ETL) | Direktori HDFS tempat resource Spark ETL ditempatkan sementara. Contoh: hdfs://host:port/tmp/starrocks. |
broker | Ya (untuk ETL) | Nama Broker yang akan digunakan. Jalankan ALTER SYSTEM ADD BROKER untuk menambahkannya terlebih dahulu. |
broker.property_key | Tidak | Properti autentikasi yang digunakan Broker untuk membaca file perantara ETL. |
Untuk daftar lengkap opsi konfigurasi Spark, lihat dokumentasi Konfigurasi Spark.
Contoh
Mode kluster Yarn (standar):
CREATE EXTERNAL RESOURCE "spark0"
PROPERTIES
(
"type" = "spark",
"spark.master" = "yarn",
"spark.submit.deployMode" = "cluster",
"spark.jars" = "xxx.jar,yyy.jar",
"spark.files" = "/tmp/aaa,/tmp/bbb",
"spark.executor.memory" = "1g",
"spark.yarn.queue" = "queue0",
"spark.hadoop.yarn.resourcemanager.address" = "resourcemanager_host:8032",
"spark.hadoop.fs.defaultFS" = "hdfs://namenode_host:9000",
"working_dir" = "hdfs://namenode_host:9000/tmp/starrocks",
"broker" = "broker0",
"broker.username" = "user0",
"broker.password" = "password0"
);Mode kluster Yarn dengan Ketersediaan tinggi YARN:
CREATE EXTERNAL RESOURCE "spark1"
PROPERTIES
(
"type" = "spark",
"spark.master" = "yarn",
"spark.submit.deployMode" = "cluster",
"spark.hadoop.yarn.resourcemanager.ha.enabled" = "true",
"spark.hadoop.yarn.resourcemanager.ha.rm-ids" = "rm1,rm2",
"spark.hadoop.yarn.resourcemanager.hostname.rm1" = "host1",
"spark.hadoop.yarn.resourcemanager.hostname.rm2" = "host2",
"spark.hadoop.fs.defaultFS" = "hdfs://namenode_host:9000",
"working_dir" = "hdfs://namenode_host:9000/tmp/starrocks",
"broker" = "broker1"
);Mode Ketersediaan tinggi HDFS:
CREATE EXTERNAL RESOURCE "spark2"
PROPERTIES
(
"type" = "spark",
"spark.master" = "yarn",
"spark.hadoop.yarn.resourcemanager.address" = "resourcemanager_host:8032",
"spark.hadoop.fs.defaultFS" = "hdfs://myha",
"spark.hadoop.dfs.nameservices" = "myha",
"spark.hadoop.dfs.ha.namenodes.myha" = "mynamenode1,mynamenode2",
"spark.hadoop.dfs.namenode.rpc-address.myha.mynamenode1" = "nn1_host:rpc_port",
"spark.hadoop.dfs.namenode.rpc-address.myha.mynamenode2" = "nn2_host:rpc_port",
"spark.hadoop.dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"working_dir" = "hdfs://myha/tmp/starrocks",
"broker" = "broker2",
"broker.dfs.nameservices" = "myha",
"broker.dfs.ha.namenodes.myha" = "mynamenode1,mynamenode2",
"broker.dfs.namenode.rpc-address.myha.mynamenode1" = "nn1_host:rpc_port",
"broker.dfs.namenode.rpc-address.myha.mynamenode2" = "nn2_host:rpc_port",
"broker.dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
);Mengelola sumber daya
-- Menampilkan semua resource
SHOW RESOURCES;
SHOW PROC "/resources";
-- Memberikan atau mencabut USAGE-PRIV
GRANT USAGE_PRIV ON RESOURCE "spark0" TO "user0"@"%";
GRANT USAGE_PRIV ON RESOURCE "spark0" TO ROLE "role0";
GRANT USAGE_PRIV ON RESOURCE * TO "user0"@"%";
GRANT USAGE_PRIV ON RESOURCE * TO ROLE "role0";
REVOKE USAGE_PRIV ON RESOURCE "spark0" FROM "user0"@"%";
REVOKE USAGE_PRIV ON RESOURCE "spark0" FROM ROLE "role0";Dengan akun biasa,SHOW RESOURCEShanya menampilkan resource yang memiliki izinUSAGE-PRIVuntuk akun tersebut. Akun root dan admin melihat semua resource.
Melepaskan sumber daya
DROP RESOURCE "resource_name";Langkah 2: Konfigurasikan klien Spark
Node frontend menggunakan spark-submit untuk mengirimkan pekerjaan Spark Load, sehingga klien Spark harus diinstal pada host node frontend.
Unduh Spark 2.4.5 atau versi 2.x terbaru dan letakkan di node frontend. Lalu konfigurasikan parameter berikut dalam file konfigurasi node frontend (fe.conf):
Tetapkan direktori home Spark Atur
spark_home_default_dirke direktori tempat Anda meletakkan klien Spark. Nilai default adalahlib/spark2xdi bawah direktori root node frontend. Parameter ini tidak boleh kosong.Paket dependensi Spark Kemas semua file JAR dari folder
jars/klien Spark ke dalam satu file ZIP. Aturspark_resource_pathke path file ZIP tersebut. Jika dibiarkan kosong, node frontend akan mencarilib/spark2x/jars/spark-2x.zipdi direktori root-nya—jika tidak ditemukan, akan muncul error. Saat pekerjaan Spark Load dikirimkan, paket dependensi diunggah ke lokasi staging jarak jauh diworking_dir/{cluster_id}/. Lokasi staging dinamai dalam format--spark-repository--{resource-name}. Contoh struktur direktori:---spark-repository--spark0/ |---archive-1.0.0/ | |---lib-990325d2c0d1d5e45bf675e54e44fb16-spark-dpp-1.0.0-jar-with-dependencies.jar | |---lib-7670c29daf535efe3c9b923f778f61fc-spark-2x.zip |---archive-1.1.0/ | |---lib-64d5696f99c379af2bee28c1c84271d5-spark-dpp-1.1.0-jar-with-dependencies.jar | |---lib-1bbb74bb6b264a270bc7fca3e964160f-spark-2x.zipNama default paket dependensi adalah
spark-2x.zip. Node frontend juga mengunggah dependensi Dynamic Partition Pruning (DPP). Setelah diunggah, paket-paket ini digunakan kembali untuk pekerjaan selanjutnya.
Langkah 3: Konfigurasikan klien YARN
Node frontend menjalankan perintah YARN untuk memeriksa status aplikasi dan menghentikan aplikasi, sehingga klien YARN juga harus diinstal pada node frontend.
Unduh Hadoop 2.5.2 atau versi 2.x terbaru dan konfigurasikan parameter berikut dalam fe.conf:
Tetapkan path eksekusi YARN Atur
yarn_client_pathke path file biner YARN. Default-nya adalahlib/yarn-client/hadoop/bin/yarndi bawah direktori root node frontend.(Opsional) Tetapkan direktori konfigurasi YARN Saat node frontend memeriksa status aplikasi atau menghentikan aplikasi, secara default akan menghasilkan
core-site.xmldanyarn-site.xmldilib/yarn-config/. Untuk mengubah lokasi ini, aturyarn_config_dir.
Mengimpor data
Buat pekerjaan impor
Sumber data yang didukung: file CSV dan tabel Hive.
LOAD LABEL db_name.label_name
(data_desc, ...)
WITH RESOURCE resource_name
[resource_properties]
[PROPERTIES (key1=value1, ...)]Dengan data_desc adalah salah satu dari:
-- Dari file HDFS
DATA INFILE ("file_path", ...)
[NEGATIVE]
INTO TABLE tbl_name
[PARTITION (p1, p2)]
[COLUMNS TERMINATED BY separator]
[(col1, ...)]
[COLUMNS FROM PATH AS (col2, ...)]
[SET (k1=f1(xx), k2=f2(xx))]
[WHERE predicate]
-- Dari tabel Hive
DATA FROM TABLE hive_external_tbl
[NEGATIVE]
INTO TABLE tbl_name
[PARTITION (p1, p2)]
[SET (k1=f1(xx), k2=f2(xx))]
[WHERE predicate]Untuk sintaks lengkap, jalankan HELP SPARK LOAD.
Parameter utama
| Parameter | Deskripsi |
|---|---|
label | Pengenal unik untuk pekerjaan impor dalam database. Spesifikasinya sama dengan Broker Load. |
| Deskripsi data | Mendukung file CSV dan tabel Hive sebagai sumber data. Spesifikasi lainnya sama dengan Broker Load. |
| Properti pekerjaan | Sama dengan opt_properties dalam Broker Load. |
| Properti resource Spark | Penggantian resource Spark per pekerjaan. Hanya berlaku untuk pekerjaan ini dan tidak mengubah konfigurasi resource tingkat kluster. |
Contoh 1: Impor dari file CSV HDFS
LOAD LABEL db1.label1
(
DATA INFILE("hdfs://emr-header-1.cluster-xxx:9000/user/starRocks/test/ml/file1")
INTO TABLE tbl1
COLUMNS TERMINATED BY ","
(tmp_c1, tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
),
DATA INFILE("hdfs://emr-header-1.cluster-xxx:9000/user/starRocks/test/ml/file2")
INTO TABLE tbl2
COLUMNS TERMINATED BY ","
(col1, col2)
WHERE col1 > 1
)
WITH RESOURCE 'spark0'
(
"spark.executor.memory" = "2g",
"spark.shuffle.compress" = "true"
)
PROPERTIES
(
"timeout" = "3600"
);Contoh 2: Impor dari tabel Hive dengan kamus global
Gunakan pendekatan ini ketika tabel StarRocks target memiliki kolom agregasi bitmap. Fungsi bitmap_dict() memetakan nilai kolom Hive mentah ke bilangan bulat terenkripsi melalui kamus global.
Buat resource Hive eksternal:
CREATE EXTERNAL RESOURCE hive0 PROPERTIES ( "type" = "hive", "hive.metastore.uris" = "thrift://emr-header-1.cluster-xxx:9083" );Buat tabel Hive eksternal:
CREATE EXTERNAL TABLE hive_t1 ( k1 INT, K2 SMALLINT, k3 VARCHAR(50), uuid VARCHAR(100) ) ENGINE=hive PROPERTIES ( "resource" = "hive0", "database" = "tmp", "table" = "t1" );Kirim pekerjaan impor:
LOAD LABEL db1.label1 ( DATA FROM TABLE hive_t1 INTO TABLE tbl1 SET ( uuid=bitmap_dict(uuid) ) ) WITH RESOURCE 'spark0' ( "spark.executor.memory" = "2g", "spark.shuffle.compress" = "true" ) PROPERTIES ( "timeout" = "3600" );
Lihat pekerjaan impor
SHOW LOAD ORDER BY createtime DESC LIMIT 1\GContoh output:
*************************** 1. row ***************************
JobId: 76391
Label: label1
State: FINISHED
Progress: ETL:100%; LOAD:100%
Type: SPARK
EtlInfo: unselected.rows=4; dpp.abnorm.ALL=15; dpp.norm.ALL=28133376
TaskInfo: cluster:cluster0; timeout(s):10800; max_filter_ratio:5.0E-5
ErrorMsg: N/A
CreateTime: 2019-07-27 11:46:42
EtlStartTime: 2019-07-27 11:46:44
EtlFinishTime: 2019-07-27 11:49:44
LoadStartTime: 2019-07-27 11:49:44
LoadFinishTime: 2019-07-27 11:50:16
URL: http://1.1.*.*:8089/proxy/application_1586619723848_0035/
JobDetails: {"ScannedRows":28133395,"TaskNumber":1,"FileNumber":1,"FileSize":200000}Bidang output
| Bidang | Deskripsi |
|---|---|
State | Status pekerjaan. Transisi: PENDING → ETL → LOADING → FINISHED (atau CANCELLED jika gagal). |
Progress | Persentase progres ETL dan LOAD. Progres LOAD dihitung sebagai: tablet yang diimpor di semua replika / total tablet × 100%. Pekerjaan mencapai 99% sebelum impor berlaku, lalu melompat ke 100%. Progres tidak selalu linier. |
Type | Jenis impor. Menampilkan SPARK untuk pekerjaan Spark Load. |
CreateTime | Waktu pekerjaan impor dibuat. |
EtlStartTime | Waktu pekerjaan memasuki status ETL. |
EtlFinishTime | Waktu pekerjaan meninggalkan status ETL. |
LoadStartTime | Waktu pekerjaan memasuki status LOADING. |
LoadFinishTime | Waktu pekerjaan selesai. |
JobDetails | Detail termasuk baris yang dipindai, jumlah tugas, jumlah file, dan ukuran data total. Contoh: {"ScannedRows":139264,"TaskNumber":1,"FileNumber":1,"FileSize":940754064}. |
URL | URL untuk antarmuka web aplikasi Spark. Buka di browser untuk melihat detail pekerjaan. |
Untuk referensi parameter lengkap, lihat Broker Load.
Untuk sintaks lengkap, jalankan HELP SHOW LOAD.
Lihat log pekerjaan
Log Spark Load disimpan di log/spark_launcher_log/ di bawah direktori root node frontend, dengan nama dalam format spark-launcher-{load-job-id}-{label}.log. Log disimpan selama tiga hari secara default dan dihapus saat metadata impor terkait dipurge.
Batalkan pekerjaan impor
Batalkan pekerjaan yang tidak berada dalam status FINISHED atau CANCELLED:
CANCEL LOAD WHERE LABEL = "label1";Untuk sintaks lengkap, jalankan HELP CANCEL LOAD.
Konfigurasi sistem
Parameter berikut dalam fe.conf mengontrol perilaku Spark Load di tingkat sistem.
| Parameter | Default | Deskripsi |
|---|---|---|
enable_spark_load | false | Mengaktifkan Spark Load dan pembuatan resource eksternal. Atur ke true untuk mengaktifkan. |
spark_load_default_timeout_second | 259200 (3 hari) | Timeout default untuk pekerjaan impor, dalam detik. |
spark_home_default_dir | fe/lib/spark2x | Direktori tempat klien Spark disimpan. |
spark_resource_path | (kosong) | Path ke file ZIP dependensi Spark yang telah dikemas. |
spark_launcher_log_dir | fe/log/spark-launcher-log | Direktori tempat log pengiriman klien Spark disimpan. |
yarn_client_path | fe/lib/yarn-client/hadoop/bin/yarn | Path ke biner klien YARN. |
yarn_config_dir | fe/lib/yarn-config | Direktori tempat file konfigurasi perintah YARN dihasilkan. |
Praktik terbaik
Gunakan Spark Load untuk impor data dalam kisaran puluhan GB hingga TB dari HDFS. Untuk dataset yang lebih kecil, Stream Load atau Broker Load lebih tepat—keduanya memiliki overhead penyiapan yang lebih rendah dan waktu respons lebih cepat.
Untuk kode contoh end-to-end lengkap, lihat 03_sparkLoad2StarRocks.md di GitHub.
Langkah selanjutnya
Broker Load — metode impor alternatif untuk dataset yang lebih kecil
Resource Management — kelola resource Spark eksternal di StarRocks