JindoFS adalah file system yang kompatibel dengan Hadoop (HCFS) yang dibangun di atas Alibaba Cloud Object Storage Service (OSS), dirancang untuk mengintegrasikan OSS dengan ekosistem big data open source. JindoFS menawarkan tiga mode penyimpanan—mode client-only (SDK), mode cache, dan mode block storage—masing-masing dioptimalkan untuk kebutuhan kinerja, biaya, dan operasional yang berbeda.
Untuk sebagian besar workload data lake dan pelatihan AI, gunakan mode client-only (SDK) atau mode cache. Gunakan mode block storage ketika workload Anda memerlukan semantik POSIX penuh, operasi rename atomik, atau manajemen metadata yang independen dari OSS.
Latar belakang: perbedaan antara object storage dan file system
OSS menyimpan data sebagai objek, bukan dalam struktur file system hirarkis. Hal ini menjadikan object storage sangat scalable dan hemat biaya, tetapi menimbulkan kesenjangan bagi workload yang bergantung pada semantik file POSIX—seperti rename atomik, seek cepat, atau operasi append. JindoFS menjembatani kesenjangan ini dengan menerapkan semantik file system di atas OSS. Masing-masing dari ketiga mode tersebut memiliki trade-off yang berbeda dalam hal kesederhanaan, kinerja, dan beban operasional.
Mode hanya klien (SDK)
Mode client-only menyediakan antarmuka yang kompatibel dengan Hadoop ke OSS tanpa layanan terdistribusi apa pun. Mode ini berfungsi serupa dengan OSS FileSystem atau S3A FileSystem di komunitas Hadoop, mengoptimalkan cara engine komputasi seperti Apache Hive dan Apache Spark mengakses data OSS.
File tetap disimpan sebagai objek di OSS—JindoFS hanya menambahkan koneksi sisi klien, ekstensi, dan akses yang dioptimalkan untuk ekosistem Hadoop. Untuk mengaktifkan mode ini, unggah paket JAR JindoFS SDK ke direktori classpath.
Mode ini memiliki beban operasional terendah dan skalabilitas tertinggi, sehingga sangat cocok untuk analitik batch dan workload di mana kesederhanaan serta skalabilitas elastis lebih penting daripada caching.
Mode cache
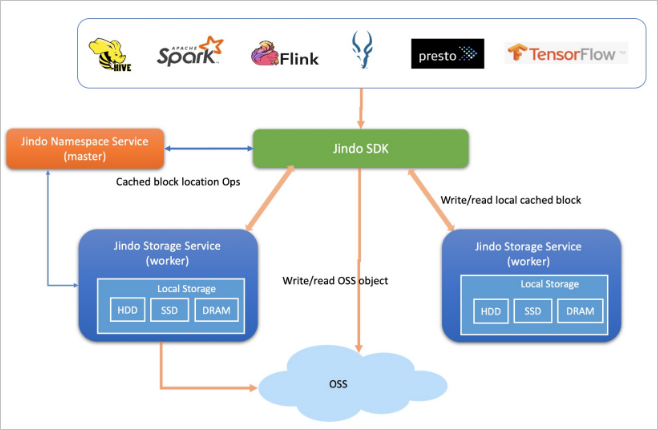
Mode cache memperluas mode client-only (SDK) dengan caching data terdistribusi menggunakan lapisan caching Jindo. Mode ini mendukung caching metadata dan caching data terdistribusi, serta menjaga kompatibilitas dan sinkronisasi penuh data dengan OSS. Data panas—sekitar 20% dari total data—di-cache secara lokal di memori, SSD, atau disk dasar, tergantung pada konfigurasi kluster Anda.
Mode cache mendukung dua pola akses:
oss://<oss_bucket>/<oss_dir>/— Akses OSS secara langsung dengan caching opsional yang diaktifkan. Akses lintas layanan didukung. Ini adalah metode default.jfs://<your_namespace>/<path_of_file>— Akses data melalui namespace JindoFS dengan caching diaktifkan. Akses lintas layanan tidak didukung.
Mode ini sangat cocok untuk analitik data skala besar dan akselerasi pelatihan AI di mana throughput menjadi prioritas dan pola akses data panas dapat diprediksi.
Mode block storage
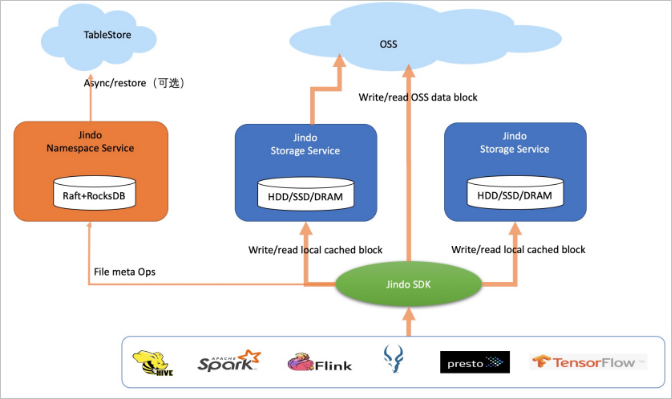
Mode block storage menyimpan file sebagai blok di OSS, bukan sebagai objek. JindoFS mengelola direktori dan metadata file secara independen melalui Namespace Service dan Storage Service-nya, sehingga memberikan perilaku yang mirip dengan Apache Hadoop HDFS. Data di-cache secara lokal—data hangat dan data panas bersama-sama mencakup sekitar 60% dari total data.
Mode block storage mendukung antarmuka penyimpanan tingkat tinggi termasuk operasi rename atomik, truncate, append, flush, sync, dan snapshot. Antarmuka ini memungkinkan Apache Flink, Apache HBase, Apache Kafka, dan Apache Kudu menulis langsung ke OSS sebagaimana mereka menulis ke file system native. Kompresi transparan juga didukung untuk data dingin guna mengurangi biaya penyimpanan.
Format akses: jfs://<your_namespace>/<path_of_file> (akses lintas layanan tidak didukung).
Mode ini sangat cocok untuk workload yang memerlukan semantik POSIX penuh, kinerja kueri metadata tinggi, atau integrasi langsung dengan mesin pemrosesan aliran.
Pilih mode yang sesuai
Perbedaan utama antar mode terletak pada cara file disimpan di OSS dan bagaimana metadata dikelola:
Mode client-only dan mode cache menyimpan file sebagai objek di OSS. Manajemen metadata mensimulasikan perilaku HDFS.
Mode block storage menyimpan file sebagai blok di OSS dan mengelola metadata secara independen, sehingga memberikan semantik yang lebih mirip HDFS.
Tabel berikut membandingkan ketiga mode tersebut berdasarkan dimensi utama.
| Dimensi | Mode client-only (SDK) | Cache Mode | Mode block storage |
|---|---|---|---|
| Paling cocok untuk | Analitik batch, penyimpanan data lake, workload yang memerlukan skalabilitas maksimum dan operasional minimal | Analitik skala besar, akselerasi pelatihan AI, workload sensitif throughput dengan pola data panas yang dapat diprediksi | Workload yang memerlukan semantik POSIX penuh, pemrosesan aliran (Flink, HBase, Kafka, Kudu), atau manajemen metadata independen dari OSS |
| Biaya penyimpanan | Seluruh data di OSS. Mendukung kelas penyimpanan Archive. | Seluruh data di OSS. Data panas di-cache (~20% dari total). Mendukung kelas penyimpanan Archive. | Seluruh data di OSS. Data hangat dan panas di-cache (~60% dari total). Mendukung kelas penyimpanan Archive. Mendukung kompresi transparan. |
| Skalabilitas | Tinggi | Relatif tinggi | Sedang |
| Throughput | Bergantung pada bandwidth OSS. Paling optimal untuk pembacaan batch sekuensial. | Bergantung pada bandwidth OSS ditambah bandwidth cache data panas. Paling optimal untuk akses berulang ke dataset panas. | Bergantung pada bandwidth OSS ditambah bandwidth cache data hangat dan panas. Paling optimal untuk IO sekuensial dan acak campuran dengan tingkat hit cache lokal yang tinggi. |
| Metadata | Mensimulasikan manajemen metadata HDFS; tidak ada penyimpanan berbasis direktori atau semantik file; mendukung data skala exabyte | Mensimulasikan manajemen metadata HDFS dengan caching data file; mendukung data skala exabyte | Kinerja metadata tertinggi; kompatibilitas mendekati HDFS; mendukung lebih dari 1 miliar file |
| Pemeliharaan | Rendah | Sedang — memerlukan O&M sistem cache | Relatif tinggi — memerlukan O&M Namespace Service dan Storage Service |
| Keamanan | Otentikasi Pasangan Kunci Akses, otentikasi RAM, log akses OSS, enkripsi data OSS | Otentikasi Pasangan Kunci Akses, otentikasi RAM, log akses OSS, enkripsi data OSS | Otentikasi Pasangan Kunci Akses, perintah UNIX atau Apache Ranger untuk pengelolaan izin, AuditLog, enkripsi data |
| Format akses | oss://<oss_bucket>/<oss_dir>/ — akses lintas layanan didukung | oss://<oss_bucket>/<oss_dir>/ (akses lintas layanan didukung) atau jfs://<your_namespace>/<path_of_file> (akses lintas layanan tidak didukung) | jfs://<your_namespace>/<path_of_file> — akses lintas layanan tidak didukung |
FAQ
Mode apa yang harus saya gunakan untuk data lake tipikal?
Mode client-only (SDK) atau mode cache. Keduanya sepenuhnya kompatibel dengan semantik object storage OSS, mendukung pemisahan komputasi dan penyimpanan secara lengkap, serta dapat diskalakan secara fleksibel. Mode cache menambahkan caching lokal untuk data panas, yang meningkatkan throughput untuk analitik dan pelatihan AI yang intensif akses.
Mengapa mode block storage mendukung lebih banyak file daripada HDFS?
Mode block storage dapat menangani lebih dari 1 miliar file, dibandingkan dengan batas maksimum sekitar 400 juta file untuk HDFS. Mode ini tidak memiliki batasan memori on-heap (HDFS dibatasi oleh ukuran heap JVM), sehingga kinerjanya tetap lebih stabil di bawah beban berat. Mode block storage juga memerlukan O&M yang ringan—kerusakan disk atau kegagalan node tidak menyebabkan kehilangan data karena semua data memiliki satu cadangan di OSS, dan node dapat ditambah atau dihapus secara bebas.
Apa keunggulan unik mode block storage?
Mode block storage mengelola metadata file dan data file secara independen dari OSS, sehingga memungkinkannya mendukung antarmuka penyimpanan tingkat tinggi yang tidak dapat disediakan secara native oleh object storage: transaksi rename atomik, penulisan lokal berkinerja tinggi, truncate, append, flush, sync, dan snapshot. Antarmuka ini diperlukan untuk menghubungkan engine data besar seperti Apache Flink, Apache HBase, Apache Kafka, dan Apache Kudu langsung ke OSS.
Mode penyimpanan blok juga menawarkan keunggulan biaya: dengan menyimpan cache 60% data secara lokal (data hangat dan panas), sebagian besar operasi baca dilayani dari kluster lokal alih-alih OSS, sehingga mengurangi biaya egress dan latensi untuk data yang sering diakses.