Pertanyaan umum mengenai metode impor data, penyetelan performa, dan penyelesaian error untuk StarRocks pada EMR.
Masalah umum
Bagaimana cara memilih metode impor?
Lihat Ikhtisar untuk perbandingan semua metode impor yang tersedia.
Apa saja faktor yang memengaruhi performa impor?
Faktor utamanya adalah:
Memori server: Semakin banyak tablet, semakin besar konsumsi memori. Ikuti panduan Bagaimana cara menentukan jumlah tablet? untuk memperkirakan ukuran tablet.
I/O disk dan bandwidth jaringan: Rentang bandwidth jaringan yang sesuai adalah 50–100 Mbit/s.
Ukuran batch dan frekuensi:
Untuk Stream Load, atur ukuran batch menjadi 10–100 MB.
Untuk Broker Load, tidak ada batasan ukuran batch — gunakan untuk batch besar.
Jaga frekuensi impor tetap rendah. Untuk HDD SATA serial (Serial Advanced Technology Attachment), jangan melebihi satu pekerjaan impor per detik.
"close index channel failed" atau "too many tablet versions"
Penyebab: Frekuensi impor tinggi mencegah proses compaction mengimbangi, sehingga jumlah versi data yang belum digabung melebihi batas default sebesar 1.000.
Perbaikan: Gunakan salah satu atau kedua pendekatan berikut:
Kurangi frekuensi impor: Tingkatkan ukuran batch agar jumlah pekerjaan impor per satuan waktu berkurang.
Percepat compaction: Atur parameter berikut dalam file be.conf di setiap node backend (BE):
cumulative_compaction_num_threads_per_disk = 4
base_compaction_num_threads_per_disk = 2
cumulative_compaction_check_interval_seconds = 2"Label Already Exists"
Deskripsi: Pekerjaan impor dengan label yang sama sedang berjalan atau telah selesai dalam database yang sama.
Penyebab: Penyebab paling umum adalah perilaku retry klien HTTP. Stream Load mengimpor data melalui HTTP. Ketika StarRocks tidak mengembalikan respons cukup cepat, beberapa klien HTTP secara otomatis mencoba ulang permintaan yang sama. StarRocks kemudian menolak permintaan kedua karena permintaan pertama masih berlangsung.
Perbaikan: Selidiki sumber label duplikat:
Cari log node frontend (FE) utama berdasarkan label. Jika label muncul dua kali, artinya klien mengirim dua permintaan.
Jalankan
SHOW LOAD WHERE LABEL = "xxx"untuk memeriksa apakah sudah ada pekerjaan dengan status FINISHED yang menggunakan label tersebut.
Label tidak dibatasi oleh metode impor tertentu. Dua pekerjaan yang menggunakan metode berbeda (misalnya, Stream Load dan Broker Load) dapat bentrok jika menggunakan label yang sama.
Untuk mencegah retry, perkirakan durasi impor berdasarkan ukuran data dan atur timeout klien HTTP melebihi durasi tersebut.
"ETL_QUALITY_UNSATISFIED; msg:quality not good enough to cancel"
Jalankan SHOW LOAD, temukan URL dalam output, lalu buka URL tersebut untuk melihat error spesifik. Error umum meliputi:
| Error | Makna |
|---|---|
convert csv string to INT failed | Nilai kolom tidak dapat dikonversi ke tipe data target (misalnya, abc ke kolom numerik). |
the length of input is too long than schema | String melebihi panjang yang ditentukan dalam skema kolom, atau nilai INT melebihi 4 byte. |
actual column number is less than schema column number | Setelah dipisahkan berdasarkan delimiter, jumlah kolom yang dihasilkan lebih sedikit daripada yang diharapkan — biasanya terjadi ketidaksesuaian delimiter. |
actual column number is more than schema column number | Setelah dipisahkan, jumlah kolom yang dihasilkan lebih banyak daripada yang didefinisikan dalam skema. |
the frac part length longer than schema scale | Bagian desimal dari nilai kolom DECIMAL melebihi skala yang ditentukan. |
the int part length longer than schema precision | Bagian integer dari nilai kolom DECIMAL melebihi presisi yang ditentukan. |
there is no corresponding partition for this key | Nilai kunci partisi berada di luar semua rentang partisi yang ditentukan. |
Timeout RPC selama impor data
Periksa parameter write_buffer_size dalam be.conf. Parameter ini menetapkan ukuran maksimum blok memori untuk node BE (default: 100 MB). Jika nilainya terlalu besar, dapat terjadi timeout panggilan prosedur jarak jauh (RPC). Sesuaikan write_buffer_size relatif terhadap parameter tablet_writer_rpc_timeout_sec. Lihat Konfigurasi parameter untuk detail selengkapnya.
"Value count does not match column count"
Penyebab: Delimiter dalam perintah impor Anda tidak sesuai dengan delimiter dalam data sumber. Misalnya:
Error: Value count does not match column count. Expect 3, but got 1. Row: 2023-01-01T18:29:00Z,cpu0,80.99Dalam kasus ini, data sumber menggunakan koma (,) sebagai delimiter, tetapi perintah impor menentukan tab (\t). StarRocks membaca ketiga field yang dipisahkan koma sebagai satu kolom tunggal.
Perbaikan: Ubah delimiter dalam perintah impor agar sesuai dengan data sumber, lalu coba lagi.
"ERROR 1064 (HY000): Failed to find enough host in all backends. need: 3"
Tambahkan "replication_num" = "1" ke properti tabel saat membuat tabel.
"Too many open files" dalam log BE
Tingkatkan batas handle file sistem.
Kurangi
base_compaction_num_threads_per_diskdancumulative_compaction_num_threads_per_disk(default: masing-masing 1). Lihat Ubah item konfigurasi.Jika masalah berlanjut, lakukan scale out kluster atau kurangi frekuensi impor.
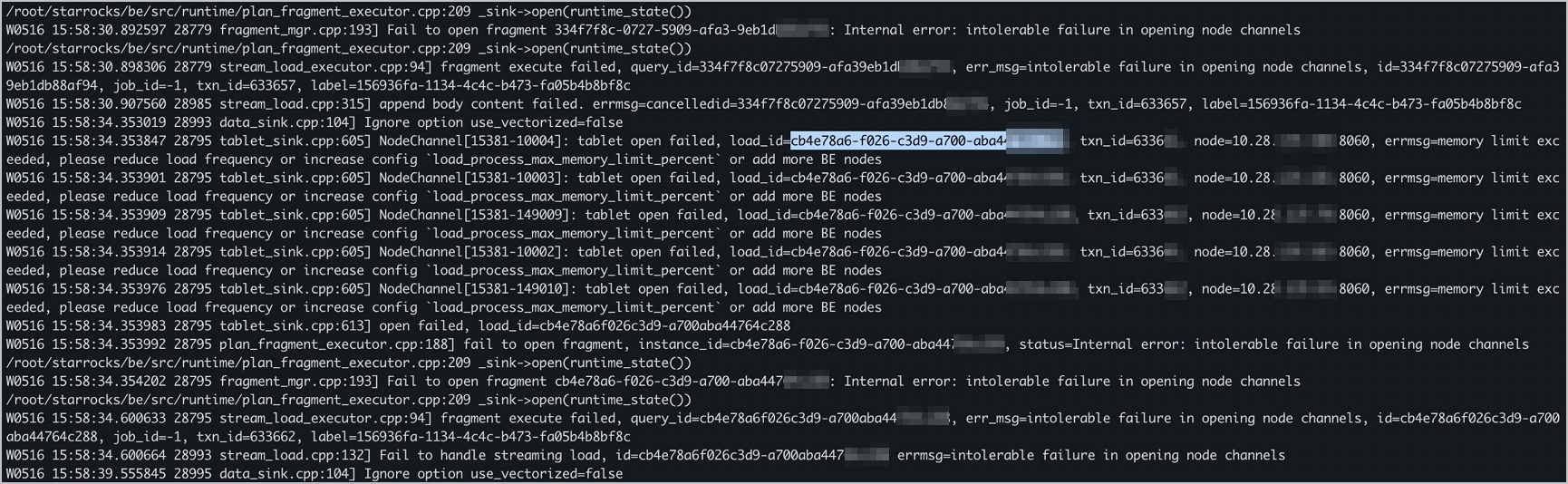
"increase config load_process_max_memory_limit_percent"
Periksa dan tingkatkan load_process_max_memory_limit_bytes dan load_process_max_memory_limit_percent. Lihat Ubah item konfigurasi.
Stream Load
Apakah Stream Load dapat mengenali nama kolom di baris pertama?
Tidak. Stream Load memperlakukan baris pertama sebagai data biasa — tidak dapat mengenali atau melewati header kolom.
Jika file sumber Anda memiliki nama kolom di baris pertama, gunakan salah satu pendekatan berikut:
Modifikasi tool ekspor agar mengekspor tanpa header kolom.
Hapus baris pertama sebelum mengimpor:
sed -i '1d' filenameFilter baris header dengan menambahkan
-H "where: column_name != 'Column Name'"ke pernyataan Stream Load. StarRocks mengonversi string header ke tipe data target dan menyaringnya. Jika konversi gagal,nulldikembalikan — pastikan kolom yang terpengaruh tidak memiliki kendalaNOT NULL.Izinkan satu baris error dengan menambahkan
-H "max_filter_ratio:0.01". Ini memungkinkan baris pertama gagal tanpa membatalkan pekerjaan.ErrorURLdalam respons tetap akan menandai error tersebut, tetapi impor berhasil. Pertahankan nilai ini rendah untuk menghindari menyembunyikan error data nyata.
Apakah saya perlu mengonversi tipe data kolom kunci partisi selama Stream Load?
Ya, tetapi StarRocks menangani konversinya. Definisikan tipe kolom target dalam skema tabel dan gunakan ekspresi kolom dalam pernyataan Stream Load.
Misalnya, jika file CSV Anda memiliki kolom DATE dengan nilai dalam format 202106.00 dan tabel mengharapkan tipe DATE, petakan seperti ini:
-H "columns: NO,DATE_1, VERSION, PRICE, DATE=LEFT(DATE_1,6)"DATE_1 adalah placeholder sementara untuk nilai mentah. LEFT(DATE_1,6) mengekstraksi enam karakter pertama dan menetapkan hasilnya ke DATE. Cantumkan semua kolom sumber berdasarkan nama sementaranya sebelum memanggil fungsi konversi apa pun. Fungsi konversi harus berupa fungsi skalar (non-agregat dan non-window).
"body exceed max size: 10737418240, limit: 10737418240"
Penyebab: File sumber melebihi batas Stream Load sebesar 10 GB.
Perbaikan:
Pisahkan file menjadi bagian-bagian lebih kecil:
seq -w 0 nAtau tingkatkan batas dengan memperbarui
streaming_load_max_mb:curl -XPOST http://<be_host>:<http_port>/api/update_config?streaming_load_max_mb=<file_size>Lihat Konfigurasi parameter untuk parameter BE lainnya.
Routine Load
Bagaimana cara meningkatkan performa impor Routine Load?
Metode 1: Tingkatkan paralelisme tugas
Ini meningkatkan penggunaan CPU dan dapat menghasilkan lebih banyak versi data.
Paralelisme tugas dibatasi oleh:
min(alive_be_number, partition_number, desired_concurrent_number, max_routine_load_task_concurrent_num)| Parameter | Deskripsi | Default |
|---|---|---|
alive_be_number | Jumlah node BE aktif | — |
partition_number | Jumlah partisi Kafka yang dikonsumsi | — |
desired_concurrent_number | Paralelisme yang diharapkan per pekerjaan Routine Load | 3 |
max_routine_load_task_concurrent_num | Paralelisme maksimum per pekerjaan Routine Load (parameter dinamis FE) | 5 |
Jika alive_be_number dan partition_number keduanya melebihi desired_concurrent_number dan max_routine_load_task_concurrent_num, tingkatkan keduanya untuk meningkatkan paralelisme.
Contoh: 7 partisi, 5 node BE aktif, max_routine_load_task_concurrent_num = 5. Ubah desired_concurrent_number dari 3 menjadi 5. Paralelisme efektif: min(5, 7, 5, 5) = 5.
Untuk pekerjaan baru: atur
desired_concurrent_numberdalamCREATE ROUTINE LOAD.Untuk pekerjaan yang sudah ada: perbarui dengan
ALTER ROUTINE LOAD.
Untuk max_routine_load_task_concurrent_num, lihat Konfigurasi parameter.
Metode 2: Tingkatkan data yang dikonsumsi per tugas
Ini meningkatkan latensi impor.
Setiap tugas Routine Load mengonsumsi data hingga mencapai batas yang ditetapkan oleh max_routine_load_batch_size (byte) atau routine_load_task_consume_second (detik). Untuk mendiagnosis batas mana yang mengikat, periksa be/log/be.INFO:
I0325 20:27:50.410579 15259 data_consumer_group.cpp:131] consumer group done: 41448fb1a0ca59ad-30e34dabfa7e47a0. consume time(ms)=3261, received rows=179190, received bytes=9855450, eos: 1, left_time: -261, left_bytes: 514432550, blocking get time(us): 3065086, blocking put time(us): 24855Jika
left_bytes >= 0: batas waktu (routine_load_task_consume_second) yang mengikat. Tingkatkanroutine_load_task_consume_second.Jika
left_bytes < 0: batas byte (max_routine_load_batch_size) yang mengikat. Tingkatkanmax_routine_load_batch_size.
Lihat Konfigurasi parameter untuk detail selengkapnya.
Setelah menjalankan SHOW ROUTINE LOAD, status pekerjaan adalah PAUSED atau CANCELLED. Apa yang harus saya lakukan?
Status: PAUSED — "Broker: Offset out of range"
Penyebab: Offset konsumen tidak lagi ada di partisi Kafka.
Perbaikan: Jalankan SHOW ROUTINE LOAD dan periksa bidang Progress untuk offset terbaru. Jika pesan pada offset tersebut telah hilang, maka:
Offset diatur ke titik masa depan saat pekerjaan dibuat.
Kafka membersihkan pesan sebelum dikonsumsi. Sesuaikan
log.retention.hoursdanlog.retention.bytesberdasarkan kecepatan impor Anda.
Status: PAUSED — jumlah baris error melebihi batas
Penyebab: Jumlah baris error melebihi max_error_number.
Perbaikan: Periksa ReasonOfStateChanged dan ErrorLogUrls:
Jika format data dapat diperbaiki, perbaiki lalu jalankan
RESUME ROUTINE LOAD.Jika format data tidak dapat diurai oleh StarRocks, tingkatkan
max_error_number:Jalankan
SHOW ROUTINE LOADuntuk memeriksa nilai saat ini.Jalankan
ALTER ROUTINE LOADuntuk menaikkannya.Jalankan
RESUME ROUTINE LOAD.
Status: CANCELLED
Penyebab: Terjadi pengecualian yang tidak dapat dipulihkan (misalnya, tabel target dihapus).
Perbaikan: Periksa ReasonOfStateChanged dan ErrorLogUrls. Pekerjaan dengan status CANCELLED tidak dapat dilanjutkan — buat pekerjaan baru.
Apakah Routine Load menjamin semantik tepat-sekali saat mengimpor dari Kafka?
Ya. Setiap tugas impor dijalankan sebagai transaksi terpisah. Jika transaksi gagal, node FE tidak memperbarui offset konsumen partisi. Saat node FE menjadwalkan ulang tugas, tugas dimulai dari offset terakhir yang disimpan, sehingga menjamin pengiriman tepat-sekali.
"Broker: Offset out of range"
Jalankan SHOW ROUTINE LOAD untuk mendapatkan offset terbaru dan verifikasi bahwa pesan pada offset tersebut ada di Kafka. Penyebab umum:
Offset masa depan ditentukan saat pekerjaan dibuat.
Kafka menghapus pesan sebelum pekerjaan impor mengonsumsinya. Sesuaikan
log.retention.hoursdanlog.retention.bytesagar sesuai dengan kecepatan impor Anda.
Broker Load
Apakah saya dapat menjalankan ulang pekerjaan Broker Load yang berstatus FINISHED?
Tidak. Label pekerjaan yang telah selesai tidak dapat digunakan kembali, hal ini mencegah impor duplikat. Untuk mengimpor kembali data yang sama, jalankan SHOW LOAD untuk melihat konfigurasi pekerjaan asli dan buat pekerjaan baru dengan label baru.
Bidang tanggal 8 jam lebih lambat dari yang diharapkan setelah mengimpor data HDFS
Penyebab: Tabel atau pekerjaan impor dibuat dengan zona waktu UTC+8, tetapi server berjalan di UTC+0. StarRocks menambahkan 8 jam ke nilai yang disimpan.
Perbaikan: Hapus parameter timezone saat membuat tabel StarRocks.
"ErrorMsg: type:ETL_RUN_FAIL; msg:Cannot cast '\<slot 6\>' from VARCHAR to ARRAY\<VARCHAR(30)\>"
Cause: Nama kolom dalam file ORC tidak sesuai dengan nama kolom dalam tabel StarRocks. Ketika nama berbeda, StarRocks memanggil pernyataan SET dan memanggil fungsi cast() untuk inferensi tipe, yang dapat gagal.
Perbaikan: Pastikan nama kolom dalam file ORC sesuai persis dengan nama kolom dalam tabel target. Hal ini memungkinkan StarRocks melewati pernyataan SET dan fungsi cast.
Tidak ada error saat membuat pekerjaan Broker Load, tetapi tidak ada data yang muncul
Broker Load bersifat asinkron. Pernyataan CREATE LOAD yang berhasil hanya berarti pekerjaan telah diajukan, bukan telah selesai. Jalankan SHOW LOAD untuk memeriksa status pekerjaan dan pesan error, lalu sesuaikan parameter dan ajukan ulang jika diperlukan.
"failed to send batch" atau "TabletWriter add batch with unknown id"
Penyebab: Terjadi timeout penulisan data.
Perbaikan: Tingkatkan variabel sistem query_timeout dan parameter BE streaming_load_rpc_max_alive_time_sec. Lihat Konfigurasi parameter.
"LOAD-RUN-FAIL; msg:OrcScannerAdapter::init_include_columns. col name = xxx not found"
Saat mengimpor file Parquet atau ORC, nama kolom dalam header file harus sesuai dengan nama dalam tabel StarRocks. Jika berbeda, gunakan pemetaan kolom dalam klausa SET:
(tmp_c1,tmp_c2)
SET
(
id=tmp_c2,
name=tmp_c1
)Jika file ORC dihasilkan oleh versi Hive lama dengan header (_col0, _col1, _col2, ...), konfigurasikan pemetaan kolom secara eksplisit melalui SET.
Pekerjaan impor macet dan tidak selesai
Dalam log fe.log node FE, cari ID pekerjaan impor menggunakan label pekerjaan. Lalu cari ID pekerjaan tersebut dalam log be.INFO node BE untuk mengidentifikasi penyebabnya.
Bagaimana cara mengakses kluster HDFS berkeandalan tinggi?
Konfigurasikan parameter berikut untuk mengaktifkan failover otomatis NameNode:
| Parameter | Deskripsi |
|---|---|
dfs.nameservices | Nama layanan HDFS. Tetapkan nama kustom, misalnya my_ha. |
dfs.ha.namenodes.xxx | Daftar nama NameNode yang dipisahkan koma. Ganti xxx dengan nilai dfs.nameservices. Contoh: my_nn. |
dfs.namenode.rpc-address.xxx.nn | Alamat RPC setiap NameNode. Ganti nn dengan nama NameNode. Format: Hostname:Port. |
dfs.client.failover.proxy.provider | Penyedia proxy failover. Default: org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider. |
Contoh konfigurasi menggunakan autentikasi simple:
(
"username"="user",
"password"="passwd",
"dfs.nameservices" = "my-ha",
"dfs.ha.namenodes.my-ha" = "my_namenode1,my_namenode2",
"dfs.namenode.rpc-address.my-ha.my-namenode1" = "nn1-host:rpc_port",
"dfs.namenode.rpc-address.my-ha.my-namenode2" = "nn2-host:rpc_port",
"dfs.client.failover.proxy.provider" = "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)Anda juga dapat menulis pengaturan ini ke hdfs-site.xml. Jika menggunakan proses broker untuk mengakses HDFS, cukup tentukan path file dan informasi autentikasi.
Bagaimana cara mengonfigurasi ViewFs dalam Federasi HDFS?
Salin core-site.xml dan hdfs-site.xml dari konfigurasi ViewFs ke direktori broker/conf.
Jika pengaturan mencakup sistem file kustom, salin file .jar terkait ke direktori broker/lib.
"Can't get Kerberos realm" saat mengakses kluster EMR yang diaktifkan Kerberos
Verifikasi bahwa
/etc/krb5.confada di setiap mesin broker.Jika error tetap muncul, tambahkan
-Djava.security.krb5.conf:/etc/krb5.confke variabelJAVA_OPTSdalam skrip startup broker.
INSERT INTO
Mengapa memasukkan satu baris dengan INSERT INTO memakan waktu 50–100 ms?
INSERT INTO dirancang untuk impor batch. Waktu untuk memasukkan satu baris sama dengan waktu untuk batch karena operasi selalu membuka transaksi penuh. Hindari menggunakan INSERT INTO untuk memuat baris individual dalam beban kerja OLAP (online analytical processing).
"index channel has intolerable failure" saat menjalankan INSERT INTO SELECT
Penyebab: Timeout RPC Stream Load.
Perbaikan: Perbarui parameter berikut dalam be.conf dan restart kluster:
| Parameter | Deskripsi | Default |
|---|---|---|
streaming_load_rpc_max_alive_time_sec | Timeout RPC untuk Stream Load | 1200 detik |
tablet_writer_rpc_timeout_sec | Timeout untuk TabletWriter | 600 detik |
"execute timeout" saat menjalankan INSERT INTO SELECT pada dataset besar
Penyebab: Kueri melebihi timeout sesi.
Perbaikan: Tingkatkan query_timeout untuk sesi (default: 600 detik):
SET query_timeout = <value>;Sinkronisasi real-time dari MySQL ke StarRocks
"Could not execute SQL statement. Reason: ValidationException: One or more required options are missing" saat menjalankan pekerjaan Flink
Penyebab: Beberapa aturan (misalnya, [table-rule.1] dan [table-rule.2]) didefinisikan dalam file config_prod.conf StarRocks-migrate-tools (SMT), tetapi bidang wajib tidak lengkap untuk satu atau beberapa aturan.
Perbaikan: Periksa bahwa setiap aturan memiliki database, tabel, dan konektor Flink yang dikonfigurasi.
Bagaimana Flink merestart tugas yang gagal?
Flink menggunakan mekanisme checkpointing yang dikombinasikan dengan kebijakan restart. Untuk mengaktifkan checkpointing dengan kebijakan restart fixed-delay, tambahkan berikut ke flink-conf.yaml:
# Interval checkpoint dalam milidetik
execution.checkpointing.interval: 300000
state.backend: filesystem
state.checkpoints.dir: file:///tmp/flink-checkpoints-directory| Parameter | Deskripsi |
|---|---|
execution.checkpointing.interval | Interval antar checkpoint dalam milidetik. Harus lebih besar dari 0 untuk mengaktifkan checkpointing. |
state.backend | Tempat state disimpan. Lihat State backends. |
state.checkpoints.dir | Direktori tempat checkpoint disimpan. |
Bagaimana cara menghentikan pekerjaan Flink dan memulihkannya ke status sebelumnya?
Gunakan titik simpan (savepoint). Titik simpan adalah snapshot konsisten dari status eksekusi pekerjaan streaming, yang dipicu secara manual. Lihat Savepoints.
Hentikan pekerjaan dan buat titik simpan:
bin/flink stop --type [native/canonical] --savepointPath [:targetDirectory] :jobId| Parameter | Deskripsi |
|---|---|
jobId | ID pekerjaan Flink. Dapatkan dari flink list -running atau UI web Flink. |
targetDirectory | Direktori untuk titik simpan. Atur state.savepoints.dir dalam flink-conf.yml untuk mengonfigurasi default: state.savepoints.dir: [file:// atau hdfs://]/home/user/savepoints_dir |
Untuk memulihkan pekerjaan, tentukan titik simpan saat mengajukan ulang:
./flink run -c com.starrocks.connector.flink.tools.ExecuteSQL -s savepoints_dir/savepoints-xxxxxxxx flink-connector-starrocks-xxxx.jar -f flink-create.all.sqlKonektor Flink
Impor gagal saat menggunakan semantik tepat-sekali
Jika Anda melihat error seperti:
{
"Status": "Fail",
"Message": "timeout by txn manager",
"WriteDataTimeMs": 120278,
...
}Penyebab: Nilai sink.properties.timeout lebih kecil daripada interval checkpoint Flink.
Perbaikan: Tingkatkan sink.properties.timeout sehingga melebihi interval checkpoint.
Setelah menggunakan flink-connector-jdbc_2.11, timestamp di StarRocks 8 jam lebih awal daripada di Flink
Atur server-time-zone ke Asia/Shanghai pada tabel sink Flink dan tambahkan &serverTimezone=Asia/Shanghai ke parameter url:
CREATE TABLE sk (
sid int,
local_dtm TIMESTAMP,
curr_dtm TIMESTAMP
)
WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://192.168.**.**:9030/sys_device?characterEncoding=utf-8&serverTimezone=Asia/Shanghai',
'table-name' = 'sink',
'driver' = 'com.mysql.jdbc.Driver',
'username' = 'sr',
'password' = 'sr123',
'server-time-zone' = 'Asia/Shanghai'
);Kafka pada kluster StarRocks berhasil diimpor, tetapi Kafka pada mesin lain gagal
Jika Anda melihat:
failed to query wartermark offset, err: Local: Bad message formatPenyebab: StarRocks tidak dapat menyelesaikan hostname Kafka.
Perbaikan: Tambahkan hostname Kafka ke /etc/hosts di setiap node kluster StarRocks.
Memori node BE terisi penuh dan CPU mencapai 100% meskipun tidak ada kueri yang berjalan
Node BE mengumpulkan statistik secara berkala dan mengelola memori berdasarkan konfigurasinya. Secara default, StarRocks mengembalikan memori ke sistem operasi (OS) hanya setelah memori yang digunakan melebihi tc_use_memory_min (default: 10737418240 byte, sekitar 10 GiB).
Untuk mengubah ambang batas ini, perbarui tc_use_memory_min dalam konfigurasi BE. Di Konsol EMR, buka tab Configure pada halaman layanan StarRocks dan pilih tab be.conf. Lihat Konfigurasi parameter.
Mengapa node BE menunda pengembalian memori ke OS?
Alokasi memori mahal. Saat StarRocks meminta sejumlah besar memori dari OS, sistem menyisakan kapasitas tambahan untuk penggunaan di masa depan. Memori yang tidak digunakan dikembalikan ke OS secara bertahap, bukan segera. Untuk memvalidasi perilaku ini, pantau penggunaan memori dalam periode panjang di lingkungan pengujian Anda untuk memastikan memori akhirnya dilepaskan.
Sistem tidak dapat mengurai dependensi konektor Flink
Penyebab: File /etc/maven/settings.xml tidak dikonfigurasi untuk menggunakan repositori publik Alibaba Cloud, sehingga beberapa dependensi tidak dapat diselesaikan.
Perbaikan: Atur alamat repositori publik Alibaba Cloud ke https://maven.aliyun.com/repository/public dalam /etc/maven/settings.xml.
Apakah sink.buffer-flush.interval-ms tetap berlaku saat interval checkpoint diatur?
Ya. Operasi flush tidak dibatasi oleh interval checkpoint. Flush dipicu ketika salah satu ambang batas berikut tercapai:
sink.buffer-flush.max-rows
sink.buffer-flush.max-bytes
sink.buffer-flush.interval-msInterval checkpoint mengontrol semantik tepat-sekali. Parameter sink.buffer-flush.interval-ms mengontrol perilaku flush setidaknya-sekali. Keduanya beroperasi secara independen.
DataX
Apakah saya dapat memperbarui data yang diimpor oleh DataX?
Ya. StarRocks versi terbaru mendukung pembaruan data dalam tabel yang dibuat dengan model primary key menggunakan DataX. Tambahkan bidang _op di bagian reader file konfigurasi JSON.
Bagaimana cara menangani kata kunci DataX untuk menghindari error impor?
Apit kata kunci dengan backtick (` ``).
Spark Load
"When running with master 'yarn' either HADOOP-CONF-DIR or YARN-CONF-DIR must be set in the environment"
Konfigurasikan variabel lingkungan HADOOP-CONF-DIR dalam skrip spark-env.sh klien Spark.
"Cannot run program 'xxx/bin/spark-submit': error=2, No such file or directory"
Penyebab: Parameter spark_home_default_dir tidak ada atau mengarah ke direktori yang salah.
Perbaikan: Atur ke direktori root klien Spark yang benar.
"File xxx/jars/spark-2x.zip does not exist"
Penyebab: Parameter spark-resource-path tidak mengarah ke file ZIP yang telah dipaketkan.
Perbaikan: Verifikasi bahwa path sesuai dengan nama file aktual.
"yarn client does not exist in path: xxx/yarn-client/hadoop/bin/yarn"
Penyebab: Tidak ada file yang dapat dieksekusi yang dikonfigurasi untuk yarn-client-path.
Perbaikan: Atur ke path biner klien YARN yang benar.