Mesin native JindoTable mempercepat kueri Spark, Hive, dan Presto pada file ORC dan Parquet yang disimpan di JindoFS atau Object Storage Service (OSS). Fitur ini dinonaktifkan secara default.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
-
Kluster E-MapReduce (EMR) yang menjalankan V3.35.0 atau versi lebih baru, atau V4.9.0 atau versi lebih baru
-
File ORC atau Parquet yang disimpan di JindoFS atau OSS
Untuk petunjuk membuat kluster EMR, lihat Create a cluster.
Engine dan format yang didukung
Mesin native mendukung kombinasi engine dan format file berikut:
| Engine | ORC | Parquet |
|---|---|---|
| Spark2 | Supported | Supported |
| Presto | Supported | Unsupported |
| Hive2 | Unsupported | Supported |
Batasan
-
Data bertipe binary tidak didukung.
-
Tabel terpartisi yang nilai kolom kunci partisinya disimpan dalam file tidak didukung.
-
Mendefinisikan skema dengan
spark.read.schema(userDefinedSchema) tidak diperbolehkan karena skema tersebut dapat bertentangan dengan skema file yang sudah ada. -
Data bertipe date harus dalam format
YYYY-MM-DDdan berada dalam rentang1400-01-01hingga9999-12-31. -
Kueri pada kolom case-sensitive dalam tabel yang sama tidak dapat dipercepat. Misalnya, jika sebuah tabel memiliki kolom
IDdan kolomid, kueri pada kolom-kolom tersebut tidak dapat dipercepat.
Aktifkan akselerasi kueri untuk Spark
Akselerasi kueri menggunakan memori off-heap. Tambahkan --conf spark.executor.memoryOverhead=4g ke tugas Spark Anda untuk mengalokasikan memori yang cukup bagi mesin native.
Konfigurasikan parameter global
Untuk menerapkan akselerasi kueri ke semua pekerjaan Spark dalam suatu kluster, atur parameter spark.sql.extensions secara global:
-
Masuk ke Alibaba Cloud EMR console.
-
Pada bilah navigasi atas, pilih wilayah tempat kluster Anda berada dan pilih kelompok sumber daya.
-
Klik tab Cluster Management.
-
Temukan kluster Anda dan klik Details di kolom Actions.
-
Pada panel navigasi kiri, pilih Cluster Service > Spark.
-
Klik tab Configure.
-
Temukan parameter
spark.sql.extensionsdan atur nilainya menjadi:io.delta.sql.DeltaSparkSessionExtension,com.aliyun.emr.sql.JindoTableExtension -
Klik Save di pojok kanan atas bagian Service Configuration.
-
Pada kotak dialog Confirm Changes, masukkan Description lalu klik OK.
-
Pilih Actions > Restart ThriftServer di pojok kanan atas.
-
Pada kotak dialog Cluster Activities, masukkan Description lalu klik OK.
-
Pada pesan Confirm, klik OK.
Konfigurasikan parameter tingkat pekerjaan
Untuk mengaktifkan akselerasi kueri pada satu pekerjaan Spark Shell atau Spark SQL, tambahkan parameter startup berikut saat mengirimkan pekerjaan:
spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension,com.aliyun.emr.sql.JindoTableExtensionUntuk detail konfigurasi, lihat Configure a Spark Shell job dan Configure a Spark SQL job.
Verifikasi bahwa akselerasi aktif
-
Buka antarmuka web UI Spark History Server.
-
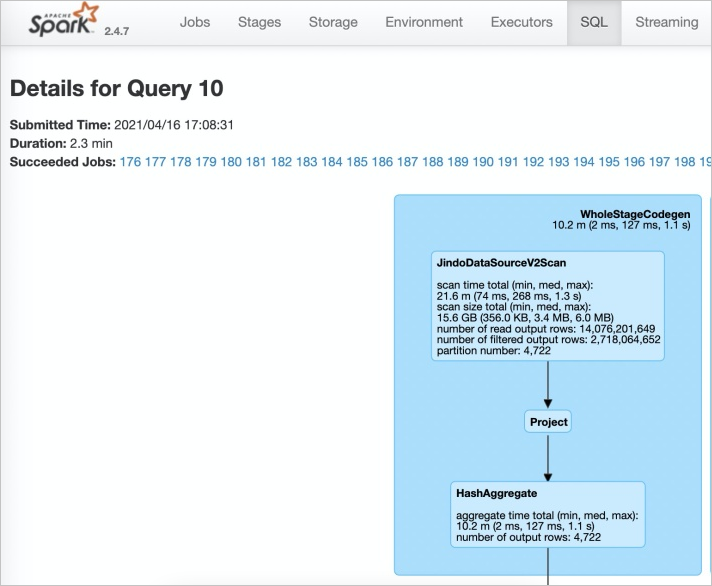
Pada tab SQL, buka tugas eksekusi untuk pekerjaan Anda. Jika JindoDataSourceV2Scan muncul dalam rencana eksekusi, akselerasi kueri aktif. Jika tidak muncul, periksa konfigurasi Anda pada langkah-langkah di atas.
Aktifkan akselerasi kueri untuk Presto
Presto menyertakan katalog bawaan bernama hive-acc. Terhubung ke katalog ini untuk mengaktifkan akselerasi kueri:
presto --server https://emr-header-1.cluster-xxx:7778/ --catalog hive-acc --schema defaultGanti emr-header-1.cluster-xxx dengan hostname node emr-header-1 Anda.
Tipe data kompleks (MAP, STRUCT, dan ARRAY) tidak didukung saat menggunakan fitur ini di Presto.
Aktifkan akselerasi kueri untuk Hive
Jika penjadwalan pekerjaan yang stabil menjadi prioritas utama, biarkan fitur ini dinonaktifkan di Hive.
EMR Hive V2.3.7 (EMR V3.35.0) menyertakan Plugin JindoTable yang mempercepat kueri Parquet. Atur parameter hive.jindotable.native.enabled untuk mengaktifkannya.
Opsi 1: Atur parameter dalam pekerjaan Hive Anda
set hive.jindotable.native.enabled=true;Opsi 2: Atur parameter pada halaman konfigurasi Hive (Hive on MapReduce dan Hive on Tez)
-
Pada halaman konfigurasi Hive, klik tab hive-site.xml.
-
Tambahkan parameter kustom
hive.jindotable.native.enableddan atur nilainya menjaditrue. -
Simpan konfigurasi dan restart Hive.
Tipe data kompleks (MAP, STRUCT, dan ARRAY) tidak didukung saat menggunakan fitur ini di Hive.