Auto Scaling menambahkan dan menghapus node task secara otomatis berdasarkan aturan yang Anda tentukan, sehingga sumber daya komputasi tetap selaras dengan beban kerja aktual Anda. Topik ini menjelaskan cara mengonfigurasi Auto Scaling untuk kluster EMR Hadoop di Konsol EMR.
Prasyarat
Sebelum memulai, pastikan Anda telah:
Memiliki kluster EMR Hadoop. Untuk informasi lebih lanjut, lihat Buat kluster.
Catatan penggunaan
Spesifikasi perangkat keras untuk node penskalaan hanya dapat dimodifikasi saat Auto Scaling dinonaktifkan. Untuk mengubah spesifikasi, nonaktifkan Auto Scaling, lakukan perubahan, lalu aktifkan kembali.
Sistem secara otomatis mencari tipe instans yang sesuai dengan spesifikasi vCPU dan memori yang Anda masukkan, lalu menampilkan hasilnya di bagian Instance Type. Pilih minimal satu tipe instans dari daftar tersebut — kluster akan melakukan penskalaan menggunakan tipe-tipe yang dipilih.
Pilih hingga tiga tipe instans untuk mengurangi risiko kegagalan penskalaan akibat kurangnya resource ECS.
Ukuran minimum data disk adalah 40 GiB, terlepas dari tipe disk (ultra disk atau standard SSD).
Penskalaan berbasis beban bergantung pada CloudMonitor. Saat Anda menyimpan aturan penskalaan berbasis beban, CloudMonitor secara otomatis membuat aturan alert yang sesuai. Jangan memodifikasi, menghapus, atau menonaktifkan aturan alert ini karena dapat mengganggu aktivitas Auto Scaling.
Pilih mode pemicu penskalaan
Sebelum mengonfigurasi aturan, tentukan mode pemicu yang sesuai dengan beban kerja Anda:
| Jika beban kerja Anda... | Gunakan... |
|---|---|
| Mengikuti jadwal yang dapat diprediksi — misalnya, job batch yang berjalan setiap malam atau pelaporan akhir hari | Time-based scaling |
| Berfluktuasi secara tidak terduga sepanjang hari berdasarkan beban kluster aktual | Load-based scaling |
Jika Anda menonaktifkan Auto Scaling, semua aturan akan dihapus. Mengaktifkan kembali Auto Scaling mengharuskan Anda mengonfigurasi ulang aturan tersebut. Jika Anda beralih antar mode pemicu, aturan dari mode sebelumnya menjadi tidak valid, tetapi node yang telah ditambahkan sebelumnya tetap dipertahankan.
Konfigurasikan auto scaling
Langkah 1: Buka tab Auto Scaling
Masuk ke Konsol EMR. Di panel navigasi kiri, klik EMR on ECS.
Di bilah navigasi atas, pilih wilayah tempat kluster Anda berada dan pilih kelompok sumber daya.
Di halaman EMR on ECS, klik nama kluster Anda di kolom Cluster ID/Name.
Klik tab Auto Scaling.
Langkah 2: Buat grup auto scaling
Di tab Configure Scaling, klik Create Auto Scaling Group.
Grup Auto Scaling hanya dapat dikonfigurasi dan dikelola di tab Auto Scaling.
Di kotak dialog Add Auto Scaling Group, masukkan nama di bidang Node Group Name lalu klik OK.
Langkah 3: Buka konfigurasi aturan penskalaan
Di tab Configure Scaling, temukan grup Auto Scaling yang baru saja Anda buat dan klik Configure Rule di kolom Actions.
Langkah 4: Konfigurasikan pengaturan dasar
Di bagian Basic Information, konfigurasikan parameter berikut:
| Parameter | Deskripsi |
|---|---|
| Maximum number of instances | Jumlah maksimum node task dalam grup auto scaling. Jika aturan penskalaan dipicu tetapi grup telah mencapai batas ini, tidak ada node tambahan yang ditambahkan. Nilai maksimum: 1.000. |
| Minimum number of instances | Jumlah minimum node task dalam grup auto scaling. Jika aturan skala-keluar akan menambahkan node lebih sedikit dari jumlah minimum ini, sistem akan menskalakan ke jumlah minimum pada pemicuan pertama. Misalnya, jika jumlah minimum adalah 3 dan aturan menambahkan 1 node setiap hari pukul 00:00, sistem akan menambahkan 3 node pada hari pertama untuk memenuhi jumlah minimum, lalu mengikuti aturan tersebut untuk pemicuan berikutnya. |
| Graceful shutdown | Periode timeout sebelum node task yang menjalankan job YARN didekomisioning. Jika job berjalan lebih lama dari periode timeout ini, atau jika tidak ada job YARN yang berjalan di node tersebut, sistem akan mendekomisioning node tersebut. Nilai maksimum: 3.600 detik. Lihat bagian Catatan penggunaan untuk graceful shutdown di bawah sebelum mengaktifkan pengaturan ini. |
Catatan penggunaan untuk graceful shutdown
Sebelum mengaktifkan graceful shutdown:
Di halaman layanan YARN, atur parameter
yarn.resourcemanager.nodes.exclude-pathmenjadi/etc/ecm/hadoop-conf/yarn-exclude.xml.Setelah mengubah Timeout Period, restart YARN ResourceManager selama jam sepi agar perubahan diterapkan.
Langkah 5: Konfigurasikan tipe instans dan metode penagihan
Di bagian tengah panel Configure Auto Scaling, konfigurasikan Instance Type Selection Mode, Billing Method, dan Instance Type.
Metode penagihan tunggal
Sistem mencocokkan tipe instans dengan spesifikasi vCPU dan memori yang Anda masukkan lalu menampilkannya di bagian Instance Type. Urutan pemilihan tipe instans menentukan prioritasnya. Pilih salah satu metode penagihan berikut:
Pay-as-you-go: Harga per jam yang ditampilkan di bawah setiap spesifikasi disk merupakan jumlah harga layanan EMR dan harga instans ECS.
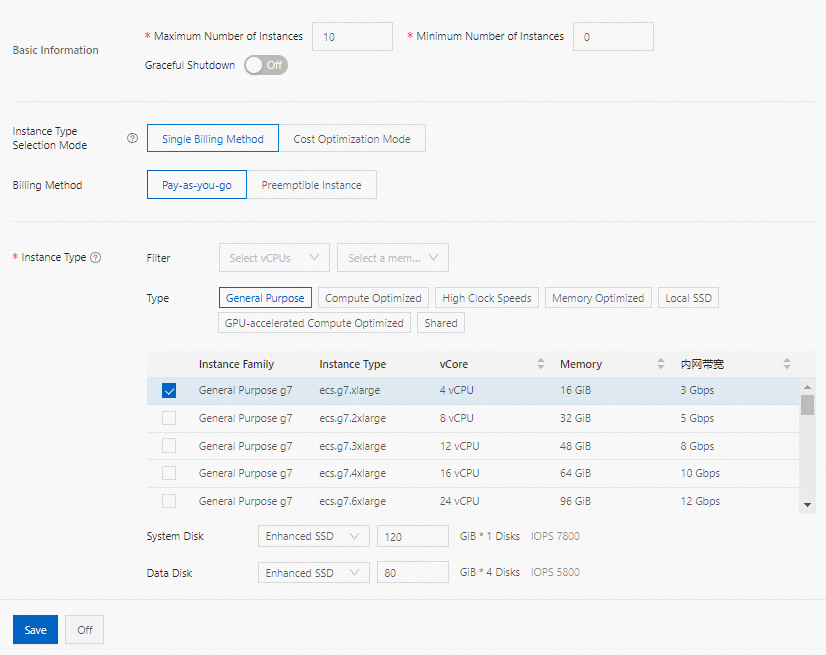
Preemptible instance: Menggunakan urutan prioritas yang sama seperti pay-as-you-go. Harga pay-as-you-go ditampilkan sebagai referensi, dan Anda dapat menetapkan harga maksimum per jam — tipe instans hanya muncul dalam daftar jika harganya sama dengan atau di bawah batas Anda. Untuk informasi lebih lanjut, lihat Apa itu preemptible instances?
PentingInstans preemptible dapat dilepas ketika penawaran gagal atau resource tidak tersedia. Jangan gunakan instans preemptible jika job Anda memiliki persyaratan SLA yang ketat.
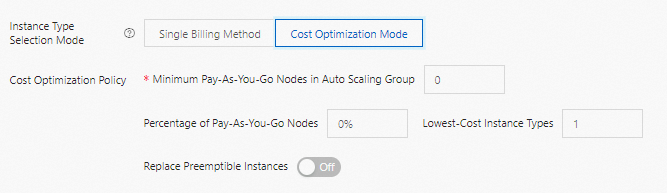
Mode Pengoptimalan Biaya
Mode Pengoptimalan Biaya memungkinkan Anda menentukan armada campuran instans pay-as-you-go dan preemptible untuk menyeimbangkan biaya dan stabilitas.
| Parameter | Deskripsi |
|---|---|
| Minimum pay-as-you-go nodes in auto scaling group | Jumlah minimum instans pay-as-you-go yang harus dipertahankan oleh grup. Ketika jumlah saat ini turun di bawah nilai ini, sistem akan membuat instans pay-as-you-go terlebih dahulu. |
| Percentage of pay-as-you-go nodes | Setelah jumlah minimum terpenuhi, persentase ini menentukan proporsi instans pay-as-you-go baru relatif terhadap ukuran total grup. |
| Lowest-cost instance types | Jumlah tipe instans termurah yang dipertimbangkan saat membuat instans preemptible. Sistem mendistribusikan instans preemptible secara merata di antara tipe-tipe tersebut. Nilai maksimum: 3. |
| Replace preemptible instances | Jika diaktifkan, sistem secara otomatis mengganti instans preemptible dengan instans pay-as-you-go sekitar 5 menit sebelum instans preemptible tersebut ditarik kembali. |
Konfigurasi umum Mode Pengoptimalan Biaya:
Jika Anda membiarkan Minimum pay-as-you-go nodes, Percentage of pay-as-you-go nodes, dan Lowest-cost instance types kosong, grup akan beroperasi sebagai grup penskalaan pengoptimalan biaya umum. Mengonfigurasi parameter-parameter ini akan membuat grup penskalaan pengoptimalan biaya instans campuran. Kedua jenis ini sepenuhnya kompatibel.
Untuk mereplikasi perilaku grup penskalaan pengoptimalan biaya umum menggunakan pengaturan instans campuran:
Hanya instans pay-as-you-go: Atur Minimum ke
0, Persentase ke100%, Lowest-cost instance types ke1.Lebih memilih instans preemptible: Atur Minimum ke
0, Persentase ke0%, Lowest-cost instance types ke1.
Langkah 6: Konfigurasikan mode pemicu dan aturan
Time-based scaling
Time-based scaling menambahkan atau menghapus jumlah tetap node task pada waktu yang dijadwalkan — harian, mingguan, atau bulanan. Gunakan metode ini jika beban kerja Anda mengikuti pola yang dapat diprediksi.
Aturan Auto Scaling dibagi menjadi aturan skala-keluar dan aturan skala-masuk. Konfigurasikan secara terpisah. Tabel berikut menjelaskan parameter untuk aturan skala-keluar (aturan skala-masuk menggunakan parameter yang sama):
| Parameter | Deskripsi |
|---|---|
| Rule name | Nama unik untuk aturan dalam kluster. |
| Execution rule | Execute repeatedly: dipicu pada waktu yang ditentukan sesuai jadwal berulang (harian, mingguan, atau bulanan). Execute only once: dipicu sekali pada waktu yang ditentukan. |
| Execution time | Waktu eksekusi aturan. |
| Rule expiration time | Tanggal dan waktu setelah aturan berhenti berjalan. |
| Retry time range | Rentang waktu sistem mencoba kembali operasi penskalaan yang gagal. Sistem mencoba kembali setiap 30 detik dalam rentang ini hingga operasi berhasil. Nilai valid: 0–21.600 detik. Misalnya, jika operasi penskalaan lain masih berjalan atau dalam masa cooldown saat aturan ini dipicu, sistem akan terus mencoba kembali setiap 30 detik hingga rentang berakhir atau kondisi terpenuhi. |
| Number of adjusted instances | Jumlah node task yang ditambahkan (atau dihapus) setiap kali aturan dipicu. |
| Cooldown time (s) | Interval antara dua aktivitas skala-keluar. Aktivitas skala-keluar dilarang selama masa cooldown. |
Load-based scaling
Load-based scaling menambahkan atau menghapus node task berdasarkan metrik kluster YARN. Gunakan metode ini jika fluktuasi beban kerja sulit diprediksi sebelumnya.
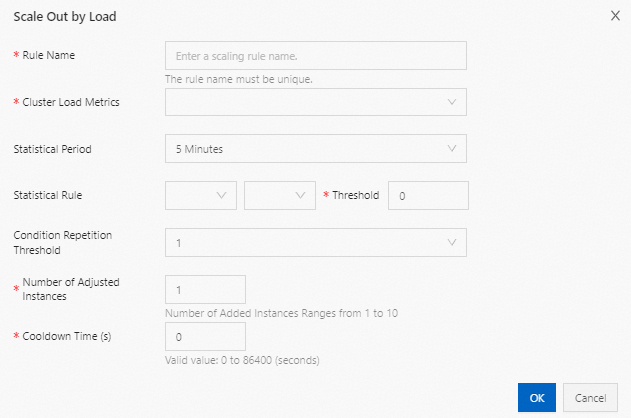
| Parameter | Deskripsi |
|---|---|
| Rule name | Nama unik untuk aturan dalam kluster. |
| Cluster load metrics | Metrik YARN yang menjadi dasar aturan ini. Metrik bersumber dari YARN. Untuk daftar lengkapnya, lihat dokumentasi resmi Hadoop dan tabel referensi metrik YARN di akhir topik ini. |
| Statistical period | Rentang waktu sistem mengevaluasi metrik yang dipilih menggunakan agregasi yang dikonfigurasi (rata-rata, maksimum, atau minimum). |
| Statistical rule | Dimensi agregasi dan kondisi ambang batas yang harus dipenuhi agar aturan dihitung menuju ambang batas pengulangan. |
| Condition repetition threshold | Jumlah periode statistik berturut-turut di mana ambang batas harus dipenuhi sebelum penskalaan dipicu. |
| Number of adjusted instances | Jumlah node task yang ditambahkan (atau dihapus) setiap kali aturan dipicu. |
| Cooldown time (s) | Interval minimum antara dua operasi penskalaan berturut-turut. Selama cooldown, penskalaan tidak dipicu meskipun kondisi ambang batas terpenuhi kembali. Setelah cooldown berakhir, aturan dipicu segera setelah kondisi terpenuhi. |
Langkah 7: Simpan dan aktifkan auto scaling
Klik Save untuk menyimpan konfigurasi Anda.
Menyimpan konfigurasi tidak mengaktifkan Auto Scaling. Untuk mengaktifkan aturan, lihat Aktifkan atau nonaktifkan Auto Scaling (kluster Hadoop).
Referensi metrik YARN
Metrik YARN berikut tersedia untuk aturan penskalaan berbasis beban. Skala-keluar biasanya dipicu ketika metrik permintaan resource (Pending, AllocatedContainers) naik di atas ambang batas; skala-masuk dipicu ketika metrik tersebut turun di bawah ambang batas.
| Metrik auto scaling EMR | Layanan | Deskripsi |
|---|---|---|
| YARN.AvailableVCores | YARN | vCPU yang tersedia |
| YARN.PendingVCores | YARN | vCPU yang diminta tetapi belum dialokasikan |
| YARN.AllocatedVCores | YARN | vCPU yang dialokasikan |
| YARN.ReservedVCores | YARN | vCPU yang dicadangkan |
| YARN.AvailableMemory | YARN | Memori yang tersedia (MB) |
| YARN.PendingMemory | YARN | Memori yang diminta tetapi belum dialokasikan (MB) |
| YARN.AllocatedMemory | YARN | Memori yang dialokasikan (MB) |
| YARN.ReservedMemory | YARN | Memori yang dicadangkan (MB) |
| YARN.AppsRunning | YARN | Aplikasi yang sedang berjalan |
| YARN.AppsPending | YARN | Aplikasi yang tertunda |
| YARN.AppsKilled | YARN | Aplikasi yang dihentikan |
| YARN.AppsFailed | YARN | Aplikasi yang gagal |
| YARN.AppsCompleted | YARN | Aplikasi yang selesai |
| YARN.AppsSubmitted | YARN | Aplikasi yang dikirim |
| YARN.AllocatedContainers | YARN | Kontainer YARN yang dialokasikan |
| YARN.PendingContainers | YARN | Kontainer yang diminta tetapi belum dialokasikan |
| YARN.ReservedContainers | YARN | Kontainer YARN yang dicadangkan |
| YARN.MemoryAvailablePrecentage | YARN | Memori yang tersedia sebagai persentase dari total memori: AvailableMemory / Total Memory |
| YARN.ContainerPendingRatio | YARN | Rasio kontainer tertunda terhadap kontainer yang dialokasikan: PendingContainers / AllocatedContainers |