Gunakan node EMR Hive di DataWorks untuk mengubah data mentah OSS menjadi set data profil pengguna. Tutorial ini memandu Anda melalui alur tiga tahap: membersihkan log web mentah, menggabungkannya dengan catatan pengguna, dan mengagregasi hasilnya ke dalam tabel ADS yang siap dikonsumsi.
Ikhtisar alur:
| Tahap | Node | Input | Output |
|---|---|---|---|
| Bersihkan (ODS → DWD) | dwd_log_info_di_emr | ods_raw_log_d_emr | Catatan log terstruktur dengan bidang region, device, dan identity |
| Gabungkan (DWD → DWS) | dws_user_info_all_di_emr | dwd_log_info_di_emr + ods_user_info_d_emr | Log dan demografi pengguna yang digabungkan |
| Ringkas (DWS → ADS) | ads_user_info_1d_emr | dws_user_info_all_di_emr | Profil pengguna harian dengan jumlah page view (PV) |
Ketergantungan node: dwd_log_info_di_emr → dws_user_info_all_di_emr → ads_user_info_1d_emr
Prasyarat
Sebelum memulai, pastikan Anda telah:
Menyinkronkan data sumber seperti yang dijelaskan dalam Sinkronkan data.
Menyiapkan bucket Object Storage Service (OSS) untuk lingkungan tersebut (dirujuk pada Langkah 2).
Langkah 1: Rancang alur kerja
Pada panel Scheduled Workflow halaman DataStudio, klik ganda alur kerja tersebut. Pada tab konfigurasi alur kerja, klik EMR Hive di bagian EMR. Di kotak dialog Create Node, atur Name, lalu klik Confirm.
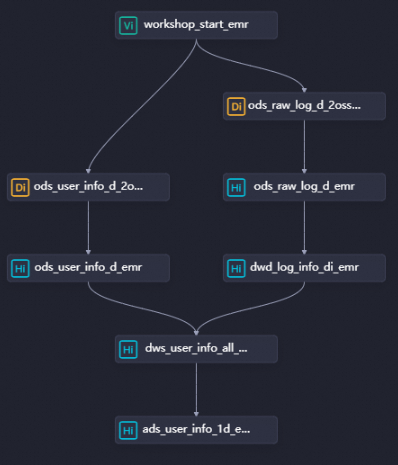
Buat tiga node EMR Hive berikut, lalu konfigurasikan ketergantungannya seperti yang ditunjukkan pada gambar:
dwd_log_info_di_emr— membersihkan data log OSS mentahdws_user_info_all_di_emr— menggabungkan log yang telah dibersihkan dengan informasi dasar penggunaads_user_info_1d_emr— menghasilkan data profil pengguna akhir
Langkah 2: Daftarkan UDF untuk pencarian IP ke region
Log mentah menyimpan alamat IP pengunjung, tetapi alur memerlukan label region. Daftarkan User-Defined Function (UDF) yang menerjemahkan alamat IP menjadi nama region.
Unggah resource JAR
Unduh paket ip2region-emr.jar.
Pada halaman DataStudio, temukan alur kerja WorkShop, klik kanan EMR, lalu pilih Create Resource > EMR JAR. Konfigurasikan parameter berikut di kotak dialog. Atur parameter lain sesuai kebutuhan Anda atau gunakan nilai default.
Parameter Nilai Storage path Bucket OSS yang telah Anda siapkan File JAR yang diunduh ip2region-emr.jar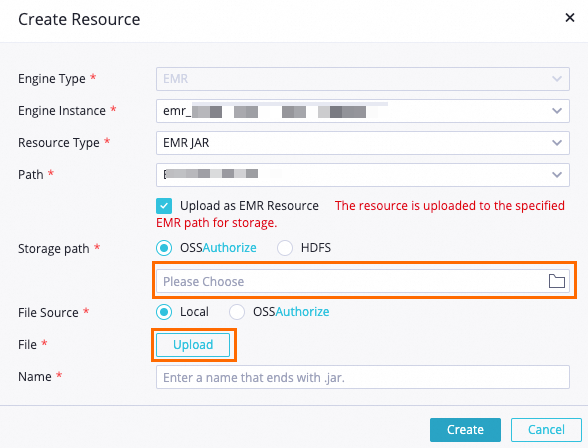
Klik ikon
 di bilah alat untuk melakukan commit resource ke proyek EMR di lingkungan pengembangan.
di bilah alat untuk melakukan commit resource ke proyek EMR di lingkungan pengembangan.
Daftarkan fungsi
Pada halaman DataStudio, temukan alur kerja WorkShop, klik kanan EMR, lalu pilih Create Function.
Di kotak dialog Create Function, atur Name menjadi
getregion, lalu klik Create. Konfigurasikan parameter berikut pada tab yang muncul. Atur parameter lain sesuai kebutuhan Anda atau gunakan nilai default.Parameter Nilai Resource ip2region-emr.jarClass Name org.alidata.emr.udf.Ip2Region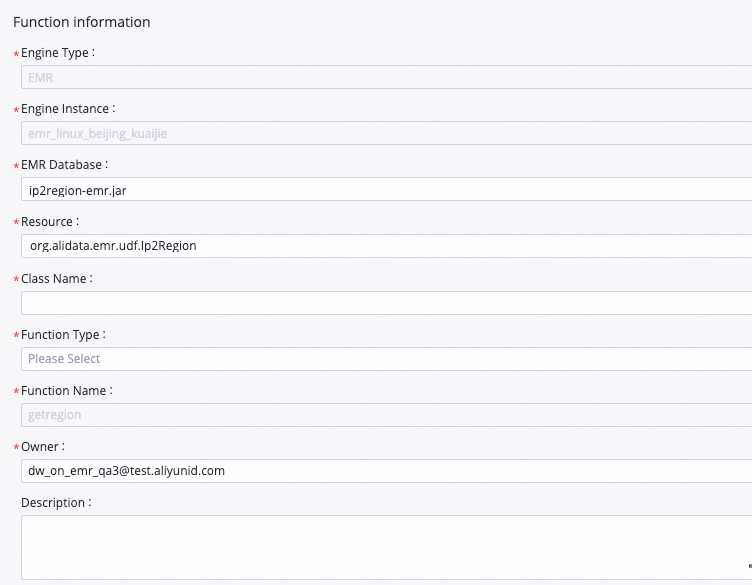
Klik ikon
di bilah alat untuk melakukan commit fungsi ke proyek EMR di lingkungan pengembangan.
Setelah langkah ini, Anda dapat memanggil getregion(ip) dalam pernyataan HiveQL apa pun di dalam proyek.
Langkah 3: Konfigurasikan node EMR Hive
Jika beberapa mesin komputasi EMR dikaitkan dengan DataStudio di ruang kerja Anda, pilih mesin komputasi yang sesuai untuk setiap node. Jika hanya satu mesin komputasi yang dikaitkan, lewati pemilihan ini.
Konfigurasikan dwd_log_info_di_emr (membersihkan log mentah)
Node ini mengurai tabel log mentah (ods_raw_log_d_emr) dan menulis catatan terstruktur ke dwd_log_info_di_emr. Setiap baris log mentah merupakan satu string tunggal yang dipisahkan oleh ##@@, dengan urutan bidang: ip, uid, time, request, status, bytes, referer, agent.
Tambahkan kode HiveQL
Klik ganda node dwd_log_info_di_emr untuk membuka tab konfigurasinya. Masukkan pernyataan berikut:
-- Buat tabel lapisan DWD untuk data log yang telah dibersihkan.
CREATE TABLE IF NOT EXISTS dwd_log_info_di_emr (
ip STRING COMMENT 'Alamat IP pengunjung',
uid STRING COMMENT 'ID Pengguna',
`time` STRING COMMENT 'Cap waktu permintaan (yyyymmddhh:mi:ss)',
status STRING COMMENT 'Kode status HTTP yang dikembalikan oleh server',
bytes STRING COMMENT 'Byte yang dikembalikan ke klien',
region STRING COMMENT 'Region yang diturunkan dari alamat IP melalui UDF',
method STRING COMMENT 'Metode HTTP (GET, POST, dll.)',
url STRING COMMENT 'Path URL permintaan',
protocol STRING COMMENT 'Versi HTTP',
referer STRING COMMENT 'URL perujuk (hanya domain)',
device STRING COMMENT 'Jenis perangkat: android, iphone, ipad, macintosh, windows_phone, windows_pc, atau unknown',
identity STRING COMMENT 'Jenis akses: crawler, feed, user, atau unknown'
)
PARTITIONED BY (dt STRING);
ALTER TABLE dwd_log_info_di_emr ADD IF NOT EXISTS PARTITION (dt='${bizdate}');
SET hive.vectorized.execution.enabled = false;
-- Urai dan bersihkan data log mentah untuk tanggal bisnis saat ini.
-- Setiap baris mentah adalah satu string dengan bidang yang dipisahkan oleh ##@@.
-- Urutan bidang: [0]=ip, [1]=uid, [2]=tm, [3]=request, [4]=status, [5]=bytes, [6]=referer, [7]=agent
INSERT OVERWRITE TABLE dwd_log_info_di_emr PARTITION (dt='${bizdate}')
SELECT
ip
, uid
, tm
, status
, bytes
, getregion(ip) AS region -- UDF: menerjemahkan IP ke nama region
, regexp_substr(request, '(^[^ ]+ )') AS method -- Mengekstrak metode HTTP dari string permintaan
, regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') AS url -- Mengekstrak path URL dari string permintaan
, regexp_extract(request, '.* ([^ ]+$)') AS protocol -- Mengekstrak versi HTTP dari string permintaan
, regexp_extract(referer, '^[^/]+://([^/]+){1}') AS referer -- Menghapus path; hanya menyimpan domain perujuk
, CASE
WHEN lower(agent) RLIKE 'android' THEN 'android'
WHEN lower(agent) RLIKE 'iphone' THEN 'iphone'
WHEN lower(agent) RLIKE 'ipad' THEN 'ipad'
WHEN lower(agent) RLIKE 'macintosh' THEN 'macintosh'
WHEN lower(agent) RLIKE 'windows phone' THEN 'windows_phone'
WHEN lower(agent) RLIKE 'windows' THEN 'windows_pc'
ELSE 'unknown'
END AS device -- Diturunkan dari string User-Agent
, CASE
WHEN lower(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler'
WHEN lower(agent) RLIKE 'feed'
OR regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') RLIKE 'feed' THEN 'feed'
WHEN lower(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)'
AND agent RLIKE '^[Mozilla|Opera]'
AND regexp_extract(request, '^[^ ]+ (.*) [^ ]+$') NOT RLIKE 'feed' THEN 'user'
ELSE 'unknown'
END AS identity -- Diturunkan dari string User-Agent dan path URL
FROM (
-- Pisahkan setiap baris log mentah menjadi bidang individual menggunakan delimiter ##@@.
SELECT
SPLIT(col, '##@@')[0] AS ip
, SPLIT(col, '##@@')[1] AS uid
, SPLIT(col, '##@@')[2] AS tm
, SPLIT(col, '##@@')[3] AS request
, SPLIT(col, '##@@')[4] AS status
, SPLIT(col, '##@@')[5] AS bytes
, SPLIT(col, '##@@')[6] AS referer
, SPLIT(col, '##@@')[7] AS agent
FROM ods_raw_log_d_emr
WHERE dt = '${bizdate}'
) a;Konfigurasikan properti penjadwalan
| Item konfigurasi | Nilai |
|---|---|
| Add Parameter (di bagian Scheduling Parameter) | Nama: bizdate / Nilai: $[yyyymmdd-1] |
| Dependencies | Atur tabel output menjadi workspacename.dwd_log_info_di_emr |
Scheduling Cycle diatur ke Day. Lewati kolom Scheduled time — waktu eksekusi diwariskan dari node root workshop_start_emr, yang memicu semua node turunan setelah pukul 00.30 setiap hari.Setelah Anda menyimpan pengaturan ini, node dwd_log_info_di_emr akan berjalan secara otomatis begitu node leluhur ods_raw_log_d_emr selesai menyinkronkan data dari OSS.
Simpan konfigurasi node
Klik ikon ![]() di bilah alat atas untuk menyimpan node.
di bilah alat atas untuk menyimpan node.
Konfigurasikan dws_user_info_all_di_emr (gabungkan log dengan catatan pengguna)
Node ini menggabungkan data log yang telah dibersihkan dengan tabel demografi pengguna dan menulis catatan gabungan ke dws_user_info_all_di_emr.
Tambahkan kode HiveQL
Klik ganda node dws_user_info_all_di_emr untuk membuka tab konfigurasinya. Masukkan pernyataan berikut:
-- Buat tabel lapisan DWS yang menggabungkan perilaku log dan demografi pengguna.
CREATE TABLE IF NOT EXISTS dws_user_info_all_di_emr (
uid STRING COMMENT 'ID Pengguna',
gender STRING COMMENT 'Jenis kelamin',
age_range STRING COMMENT 'Rentang usia',
zodiac STRING COMMENT 'Zodiak',
region STRING COMMENT 'Region yang diturunkan dari alamat IP',
device STRING COMMENT 'Jenis perangkat',
identity STRING COMMENT 'Jenis akses: crawler, feed, user, atau unknown',
method STRING COMMENT 'Metode HTTP',
url STRING COMMENT 'Path URL permintaan',
referer STRING COMMENT 'Domain perujuk',
`time` STRING COMMENT 'Cap waktu permintaan (yyyymmddhh:mi:ss)'
)
PARTITIONED BY (dt STRING);
ALTER TABLE dws_user_info_all_di_emr ADD IF NOT EXISTS PARTITION (dt='${bizdate}');
-- Gabungkan data log yang telah dibersihkan (kiri) dengan demografi pengguna (kanan) berdasarkan uid.
-- COALESCE menangani kasus di mana uid muncul di log tetapi tidak ada di tabel pengguna.
INSERT OVERWRITE TABLE dws_user_info_all_di_emr PARTITION (dt='${bizdate}')
SELECT
COALESCE(a.uid, b.uid) AS uid
, b.gender
, b.age_range
, b.zodiac
, a.region
, a.device
, a.identity
, a.method
, a.url
, a.referer
, a.`time`
FROM (
SELECT * FROM dwd_log_info_di_emr WHERE dt = '${bizdate}'
) a
LEFT OUTER JOIN (
SELECT * FROM ods_user_info_d_emr WHERE dt = '${bizdate}'
) b ON a.uid = b.uid;Konfigurasikan properti penjadwalan
| Item konfigurasi | Nilai |
|---|---|
| Add Parameter (di bagian Scheduling Parameter) | Nama: bizdate / Nilai: $[yyyymmdd-1] |
| Dependencies | Atur tabel output menjadi workspacename.dws_user_info_all_di_emr |
Scheduling Cycle diatur ke Day. Lewati kolom Scheduled time — waktu eksekusi ditentukan oleh node root workshop_start_emr.Setelah Anda menyimpan pengaturan ini, node dws_user_info_all_di_emr akan berjalan secara otomatis begitu kedua node leluhur (ods_user_info_d_emr dan dwd_log_info_di_emr) selesai.
Simpan konfigurasi node
Klik ikon ![]() di bilah alat atas untuk menyimpan node.
di bilah alat atas untuk menyimpan node.
Konfigurasikan ads_user_info_1d_emr (hasilkan profil pengguna)
Node ini mengagregasi data yang telah digabungkan menjadi profil pengguna harian, dikelompokkan berdasarkan uid, dan menulis hasilnya ke ads_user_info_1d_emr.
Tambahkan kode HiveQL
Klik ganda node ads_user_info_1d_emr untuk membuka tab konfigurasinya. Masukkan pernyataan berikut:
-- Buat tabel lapisan ADS untuk profil pengguna harian.
CREATE TABLE IF NOT EXISTS ads_user_info_1d_emr (
uid STRING COMMENT 'ID Pengguna',
region STRING COMMENT 'Region yang diturunkan dari alamat IP',
device STRING COMMENT 'Jenis perangkat',
pv BIGINT COMMENT 'Jumlah page view',
gender STRING COMMENT 'Jenis kelamin',
age_range STRING COMMENT 'Rentang usia',
zodiac STRING COMMENT 'Zodiak'
)
PARTITIONED BY (dt STRING);
ALTER TABLE ads_user_info_1d_emr ADD IF NOT EXISTS PARTITION (dt='${bizdate}');
-- Agregasi perilaku per pengguna untuk tanggal bisnis saat ini.
-- COUNT(0) menghitung semua baris log per uid sebagai total page view.
INSERT OVERWRITE TABLE ads_user_info_1d_emr PARTITION (dt='${bizdate}')
SELECT
uid
, MAX(region)
, MAX(device)
, COUNT(0) AS pv
, MAX(gender)
, MAX(age_range)
, MAX(zodiac)
FROM dws_user_info_all_di_emr
WHERE dt = '${bizdate}'
GROUP BY uid;Konfigurasikan properti penjadwalan
| Item konfigurasi | Nilai |
|---|---|
| Add Parameter (di bagian Scheduling Parameter) | Nama: bizdate / Nilai: $[yyyymmdd-1] |
| Dependencies | Atur tabel output menjadi workspacename.ads_user_info_1d_emr |
Scheduling Cycle diatur ke Day. Lewati kolom Scheduled time — waktu eksekusi ditentukan oleh node root workshop_start_emr.Setelah Anda menyimpan pengaturan ini, node ads_user_info_1d_emr akan berjalan secara otomatis begitu dws_user_info_all_di_emr selesai.
Simpan konfigurasi node
Klik ikon ![]() di bilah alat atas untuk menyimpan node.
di bilah alat atas untuk menyimpan node.
Langkah 4: Uji dan commit alur kerja
Pada tab konfigurasi alur kerja, klik ikon
 untuk menjalankan alur kerja.
untuk menjalankan alur kerja.Saat ikon
 muncul di samping semua node, klik ikon
muncul di samping semua node, klik ikon  untuk melakukan commit.
untuk melakukan commit.Pada kotak dialog Commit, pilih node yang akan di-commit, masukkan deskripsi, dan pilih Ignore I/O Inconsistency Alerts.
Klik Confirm.
Pada halaman Deployment Package Creation, deploy node tersebut.
Langkah 5: Jalankan node di lingkungan produksi
Node yang telah di-deploy menghasilkan instans yang dijadwalkan untuk hari berikutnya. Gunakan fitur pengisian ulang data untuk memicu eksekusi langsung dan memverifikasi bahwa alur berfungsi dari awal hingga akhir di lingkungan produksi.
Klik Operation Center di pojok kanan atas (atau di bilah alat atas tab konfigurasi alur kerja).
Di panel navigasi kiri, pilih Auto Triggered Node O&M > Auto Triggered Nodes. Klik nama node beban nol
workshop_start_emr.Di grafik asiklik terarah (DAG) di sebelah kanan, klik kanan node
workshop_start_emr, lalu pilih Run > Current and Descendant Nodes Retroactively.Di panel Backfill Data, pilih node yang akan diisi ulang datanya, atur parameter Data Timestamp, lalu klik Submit and Redirect. Halaman instans pengisian ulang data akan terbuka.
Klik Refresh hingga semua node menunjukkan status sukses.
Lanjutan
Untuk memantau kualitas data yang dihasilkan oleh node-node ini, konfigurasikan aturan kualitas data di DataWorks. Untuk informasi lebih lanjut tentang pengisian ulang data dan pengelolaan instans pengisian ulang, lihat Pengisian ulang data dan tampilkan instans pengisian ulang data (versi baru).