Saat menjalankan microservices di Enterprise Distributed Application Service (EDAS), Anda memerlukan satu halaman yang menampilkan volume permintaan, latensi, tekanan garbage collection, dan pemanfaatan infrastruktur untuk mendeteksi anomali tanpa harus berpindah antar alat. Halaman Ikhtisar Aplikasi di Konsol EDAS mengkonsolidasikan metrik-metrik tersebut dengan perbandingan minggu-ke-minggu dan hari-ke-hari, membantu Anda mengidentifikasi regresi serta menghubungkan gejala tingkat aplikasi dengan penyebab tingkat sistem.
Buka halaman ikhtisar aplikasi
Masuk ke Konsol EDAS.
Di panel navigasi kiri, pilih Application Management > Applications.
Pada halaman Applications, pilih wilayah di bilah navigasi atas. Dari daftar drop-down Microservices Namespace, pilih ruang mikroservis. Dari daftar drop-down Cluster Type, pilih ECS Clusters. Klik nama aplikasi yang ingin Anda kelola.
Di panel navigasi kiri, pilih Application Monitoring > Application Overview.
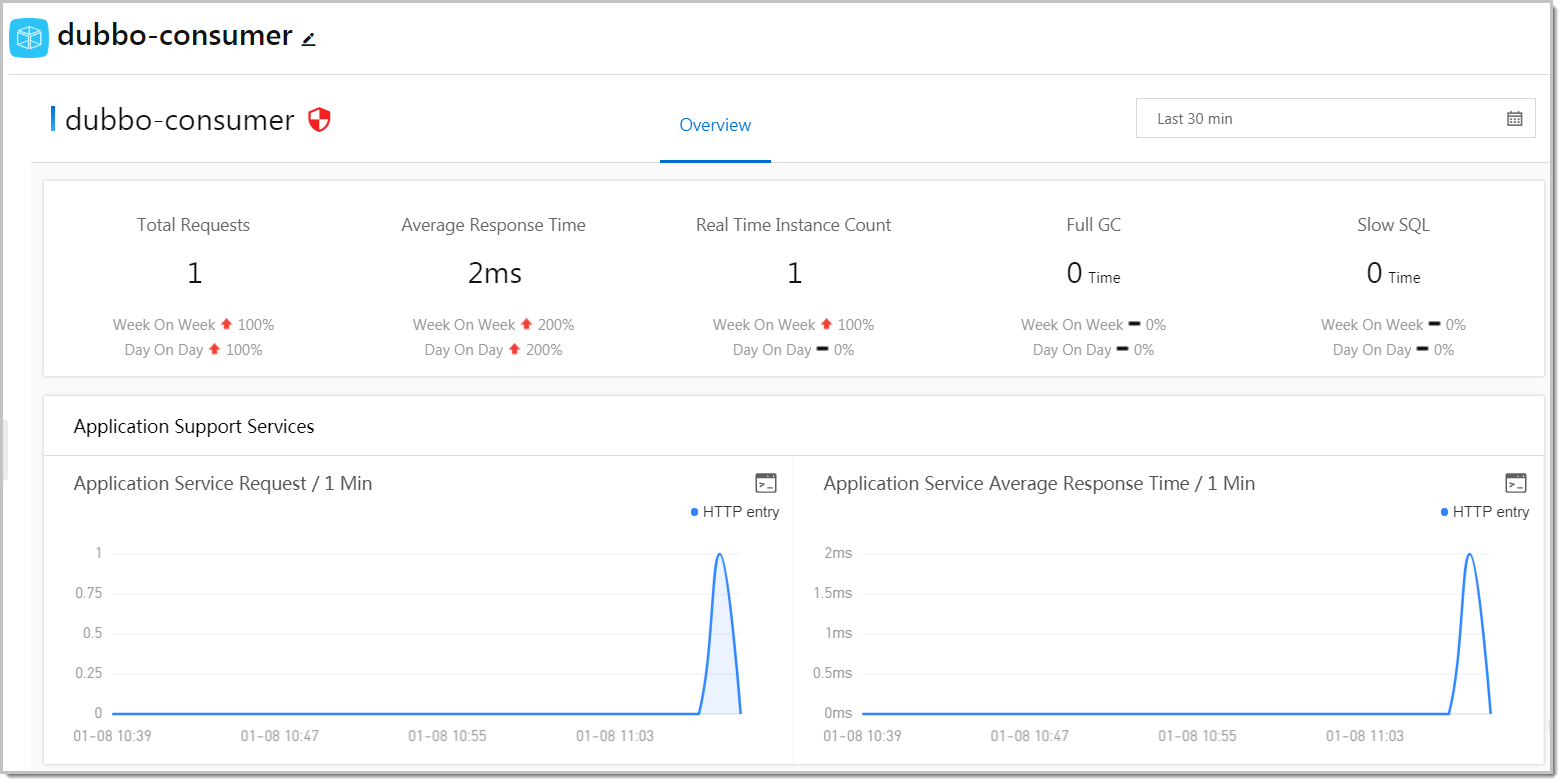
Metrik ringkasan
Lima indikator muncul di bagian atas tab Overview. Setiap indikator mencakup laju perubahan minggu-ke-minggu dan hari-ke-hari sehingga Anda dapat membedakan pola traffic yang diharapkan dari anomali yang tidak terduga.
| Metric | Description | What to investigate |
|---|---|---|
| Total requests | Total volume permintaan inbound untuk rentang waktu yang dipilih. | Lonjakan mendadak dapat mengindikasikan lonjakan traffic. Penurunan mendadak dapat mengindikasikan kegagalan upstream atau masalah routing. |
| Average response time | Latensi rata-rata di seluruh permintaan. | Meningkatnya latensi sering kali menandakan konflik sumber daya atau panggilan downstream yang lambat. Bandingkan dengan pemanfaatan CPU dan waktu respons layanan dependen. |
| Real-time instances | Jumlah instans aplikasi yang sedang berjalan. | Bandingkan dengan kapasitas yang diharapkan. Jumlah yang lebih rendah dari perkiraan dapat menjelaskan meningkatnya waktu respons. |
| Full GCs | Jumlah pengumpulan sampah penuh (full garbage collections). | Full GC yang sering terjadi mengindikasikan tekanan memori dan dapat menyebabkan lonjakan latensi. Korelasikan dengan penggunaan memori di bagian System Info. |
| Slow SQL queries | Jumlah kueri database yang melebihi ambang batas kueri lambat. | Jumlah yang tinggi menunjukkan adanya bottleneck di tingkat database. Tinjau rencana kueri dan pengindeksan. |
Bandingkan laju perubahan minggu-ke-minggu dan hari-ke-hari untuk membedakan pola berulang (seperti puncak traffic mingguan) dari masalah baru. Metrik yang stabil minggu-ke-minggu tetapi memburuk hari-ke-hari mungkin mengarah pada penerapan (deployment) yang baru saja dilakukan.
Investigasi metrik tingkat layanan
Tab Overview menampilkan grafik deret waktu untuk layanan yang disediakan oleh aplikasi Anda maupun layanan yang diandalkannya. Gunakan grafik ini untuk mempersempit apakah masalah performa berasal dari aplikasi Anda sendiri atau dari dependensi downstream.
Application Support Services
Kurva deret waktu untuk layanan yang diekspos aplikasi Anda kepada pemanggil upstream:
| Chart | Description | When to use |
|---|---|---|
| Request count | Volume panggilan inbound dari waktu ke waktu. | Identifikasi lonjakan traffic, penurunan, atau pergeseran distribusi permintaan di berbagai layanan. |
| Average response time | Latensi respons yang dikembalikan aplikasi Anda kepada pemanggil. | Penurunan performa di sini secara langsung memengaruhi konsumen upstream. Jika waktu respons meningkat sementara jumlah permintaan tetap stabil, periksa layanan dependen atau sumber daya sistem. |
Application Dependent Services
Kurva deret waktu untuk layanan yang dipanggil aplikasi Anda:
| Chart | Description | When to use |
|---|---|---|
| Request count | Volume panggilan outbound ke layanan downstream. | Identifikasi layanan downstream mana yang menerima traffic terbanyak dari aplikasi Anda. |
| Average response time | Latensi panggilan downstream. | Lonjakan di sini sering kali menjelaskan meningkatnya waktu respons dalam metrik ringkasan. |
| Application instances | Jumlah instans dari waktu ke waktu. | Korelasikan peristiwa penskalaan instans dengan perubahan performa. Penurunan jumlah instans downstream dapat menyebabkan peningkatan latensi. |
| HTTP status codes | Distribusi kode respons dari layanan dependen. | Perhatikan peningkatan kode 4xx (kesalahan client) atau 5xx (kesalahan server) sebagai indikator kegagalan downstream. |
Memantau sumber daya sistem
Bagian System Info menampilkan kurva deret waktu tingkat infrastruktur. Gunakan metrik ini bersama grafik tingkat aplikasi di atas untuk menentukan apakah masalah performa disebabkan oleh masalah tingkat kode atau keterbatasan sumber daya.
| Chart | Description | What to investigate |
|---|---|---|
| CPU utilization | Persentase CPU yang digunakan di seluruh host aplikasi. | Pemanfaatan tinggi yang berkelanjutan mungkin memerlukan penskalaan horizontal atau optimasi operasi komputasi-intensif. Korelasikan lonjakan CPU dengan peningkatan waktu respons. |
| Memory usage | Persentase memori yang digunakan. | Peningkatan penggunaan memori yang disertai full GC yang sering (lihat metrik ringkasan) mungkin mengindikasikan kebocoran memori. |
| Load | Rata-rata beban sistem. | Bandingkan nilai beban dengan jumlah core CPU yang tersedia. Beban yang secara konsisten lebih tinggi daripada jumlah core menunjukkan bahwa host kelebihan beban. |
Alur kerja pemecahan masalah
Saat melihat anomali dalam metrik ringkasan, gunakan pendekatan berikut untuk mempersempit akar penyebabnya:
Periksa metrik ringkasan. Identifikasi indikator mana yang menyimpang dari garis dasarnya. Misalnya, jika waktu respons rata-rata meningkat sementara total permintaan tetap stabil, kemungkinan besar masalah tersebut tidak terkait traffic.
Periksa layanan dependen. Tinjau grafik Application Dependent Services untuk mencari lonjakan latensi atau peningkatan kode kesalahan. Jika layanan downstream menunjukkan peningkatan respons 5xx, kemungkinan masalah berasal dari sana.
Tinjau sumber daya sistem. Periksa pemanfaatan CPU, penggunaan memori, dan beban. Jika CPU jenuh atau penggunaan memori terus meningkat disertai full GC yang sering, kemungkinan besar masalahnya berada di tingkat sumber daya, bukan tingkat layanan.
Korelasikan lintas lapisan. Bandingkan waktu kemunculan anomali di metrik aplikasi dan metrik sistem. Misalnya, lonjakan waktu respons yang bertepatan dengan lonjakan CPU dan penerapan terbaru mengindikasikan bahwa penerapan tersebut memperkenalkan jalur kode yang intensif sumber daya.