Buat Spark cluster menggunakan Instance ECS yang ditingkatkan dengan eRDMA dan jalankan Benchmark untuk mengukur kinerja pemrosesan beban dengan latensi ultra-rendah.
Latar Belakang
Benchmark adalah alat benchmarking kinerja yang mengukur waktu eksekusi beban, laju transmisi, throughput, dan pemanfaatan resource.
Langkah 1: Siapkan lingkungan
Siapkan kluster Hadoop, instal driver yang diperlukan, dan konfigurasikan eRDMA sebelum menjalankan pengujian Benchmark.
-
Siapkan lingkungan Hadoop. Lewati langkah ini jika kluster Hadoop sudah tersedia.
-
Kebutuhan perangkat keras dan perangkat lunak
Siapkan versi Hadoop, versi Spark, dan Instance ECS berikut:
-
Versi Hadoop: Hadoop 3.2.1.
-
Versi Spark: Spark 3.2.1.
-
Instance ECS
-
Tipe instans: Lihat Overview.
-
vCPU per instans: 16.
-
Jumlah instans: empat—satu node master dan tiga node pekerja.
-
-
-
Instalasi
-
-
Login ke node master. Lihat Login ke instans Linux menggunakan Workbench.
-
Konfigurasikan eRDMA.
-
Instal driver yang diperlukan. Lihat Aktifkan eRDMA pada instans tingkat enterprise.
-
Konfigurasikan pengaturan jaringan.
-
Buka file
hosts:vim /etc/hosts -
Tekan I untuk masuk ke mode Insert dan ubah isi file:
192.168.201.83 poc-t5m0 master1 192.168.201.84 poc-t5w0 192.168.201.86 poc-t5w1 192.168.201.85 poc-t5w2CatatanGanti alamat IP dengan alamat antarmuka eRDMA (ERI) aktual Anda.
-
Tekan Esc, ketik
:wq, lalu tekan Enter untuk menyimpan dan keluar.
-
-
Konfigurasikan pengaturan YARN.
CatatanLewati sublangkah ini jika NIC default dari Instance ECS mendukung eRDMA.
-
Buka file yarn-env.sh:
cd /opt/hadoop-3.2.1/etc/hadoop vim yarn-env.sh -
Tekan I untuk masuk ke mode Insert dan tambahkan konten berikut:
RDMA_IP=`ip addr show eth1 | grep "inet\b" | awk '{print $2}' | cut -d/ -f1` export YARN_NODEMANAGER_OPTS="-Dyarn.nodemanager.hostname=$RDMA_IP"CatatanGanti eth1 dengan nama ERI aktual Anda.
-
Tekan Esc, ketik
:wq, lalu tekan Enter untuk menyimpan dan keluar.
-
-
Konfigurasikan Spark.
CatatanLewati sublangkah ini jika NIC default dari Instance ECS mendukung eRDMA.
-
Buka file spark-env.sh:
cd /opt/spark-3.2.1-bin-hadoop3.2/conf vim spark-env.sh -
Tekan I untuk masuk ke mode Insert dan tambahkan konten berikut:
export SPARK_LOCAL_IP=`/sbin/ip addr show eth1 | grep "inet\b" | awk '{print $2}' | cut -d/ -f1`CatatanGanti eth1 dengan nama ERI aktual Anda.
-
Tekan Esc, ketik
:wq, lalu tekan Enter untuk menyimpan dan keluar.
-
-
-
Jalankan HDFS dan YARN:
$HADOOP_HOME/sbin/start-all.sh
Langkah 2: Unduh paket instalasi Benchmark
Unduh dan ekstrak paket instalasi Benchmark untuk mendapatkan plug-in Spark eRDMA dan dependensinya.
-
Unduh paket instalasi Benchmark:
wget https://mracc-release.oss-cn-beijing.aliyuncs.com/erdma-spark/spark-erdma-jverbs.tar.gz -
Ekstrak paket
spark-erdma-jverbs.tar.gz:tar -zxvf spark-erdma-jverbs.tar.gzPaket tersebut berisi komponen-komponen berikut:
-
erdmalib: library native yang diperlukan oleh plug-in spark-erdma, sesuai dengan libdisni.so.
-
plugin-sparkrdma: plug-in Spark RDMA dan library dependensi, sesuai dengan spark-eRDMA-1.0-for-spark-3.2.1.jar dan disni-2.1-jar-with-dependencies.jar.
-
Langkah 3: Jalankan pengujian Benchmark
Konfigurasikan entri rute IP dan pengaturan Spark, hasilkan data uji, lalu jalankan pengujian Benchmark.
-
Ubah entri rute IP.
CatatanLewati langkah ini jika NIC default dari Instance ECS Anda mendukung eRDMA.
route del -net 192.168.201.0 netmask 255.255.255.0 metric 0 dev eth0 && \ route add -net 192.168.201.0 netmask 255.255.255.0 metric 1000 dev eth0CatatanGanti alamat IP dengan alamat gateway ERI aktual Anda.
-
Konfigurasikan Spark.
-
Buka file spark-jverbs-erdma.conf:
vim /opt/spark-3.2.1-bin-hadoop3.2/conf/spark-jverbs-erdma.conf -
Tekan I untuk masuk ke mode Insert dan ubah isi file:
spark.master yarn spark.deploy-mode client #driver spark.driver.cores 4 spark.driver.memory 19g #executor spark.executor.instances 12 spark.executor.memory 10g spark.executor.cores 4 spark.executor.heartbeatInterval 60s #shuffle spark.task.maxFailures 4 spark.default.parallelism 36 spark.sql.shuffle.partitions 192 spark.shuffle.compress true spark.shuffle.spill.compress true #other spark.network.timeout 3600 spark.sql.broadcastTimeout 3600 spark.eventLog.enabled false spark.eventLog.dir hdfs://master1:9000/sparklogs spark.eventLog.compress true spark.yarn.historyServer.address master1:18080 spark.serializer org.apache.spark.serializer.KryoSerializer #eRDMA spark.driver.extraLibraryPath /path/erdmalib spark.executor.extraLibraryPath /path/erdmalib spark.driver.extraClassPath /path/spark-eRDMA-1.0-for-spark-3.2.1.jar:/path/disni-2.1-jar-with-dependencies.jar spark.executor.extraClassPath /path/spark-eRDMA-1.0-for-spark-3.2.1.jar:/path/disni-2.1-jar-with-dependencies.jar spark.shuffle.manager org.apache.spark.shuffle.sort.RdmaShuffleManager spark.shuffle.sort.io.plugin.class org.apache.spark.shuffle.rdma.RdmaLocalDiskShuffleDataIO spark.shuffle.rdma.recvQueueDepth 128Catatan-
Atur
spark.shuffle.compresskefalseuntuk rasio akselerasi yang lebih baik. -
Kode contoh menggunakan pengaturan resource Spark untuk Instance ECS dengan 32 vCPU dan memori 128 GB. Sesuaikan
spark.executor.instances,spark.executor.memory,spark.executor.cores, danspark.sql.shuffle.partitionsberdasarkan skala kluster atau spesifikasi instans Anda.
-
-
Tekan Esc, ketik
:wq, lalu tekan Enter untuk menyimpan dan keluar.
-
-
Hasilkan data:
cd /opt/spark-3.2.1-bin-hadoop3.2/conf spark-submit --properties-file /opt/spark-3.2.1-bin-hadoop3.2/conf/spark-normal.conf --class com.databricks.spark.sql.perf.tpcds.TPCDS_Bench_DataGen spark-sql-perf_2.12-0.5.1-SNAPSHOT.jar hdfs://master1:9000/tmp/tpcds_400 tpcds_400 400 parquetCatatan400menentukan volume data dalam GB. Sesuaikan berdasarkan skala kluster Anda. -
Jalankan pengujian Benchmark:
spark-submit --properties-file /opt/spark-3.2.1-bin-hadoop3.2/conf/spark-jverbs-erdma.conf --class com.databricks.spark.sql.perf.tpcds.TPCDS_Bench_RunAllQuery spark-sql-perf_2.12-0.5.1-SNAPSHOT.jar all hdfs://master1:9000/tmp/tpcds_400 tpcds_400 /tmp/tpcds_400_resultOutput berikut menunjukkan bahwa pengujian telah selesai. Hasil pengujian menampilkan waktu eksekusi beban dari Spark cluster.
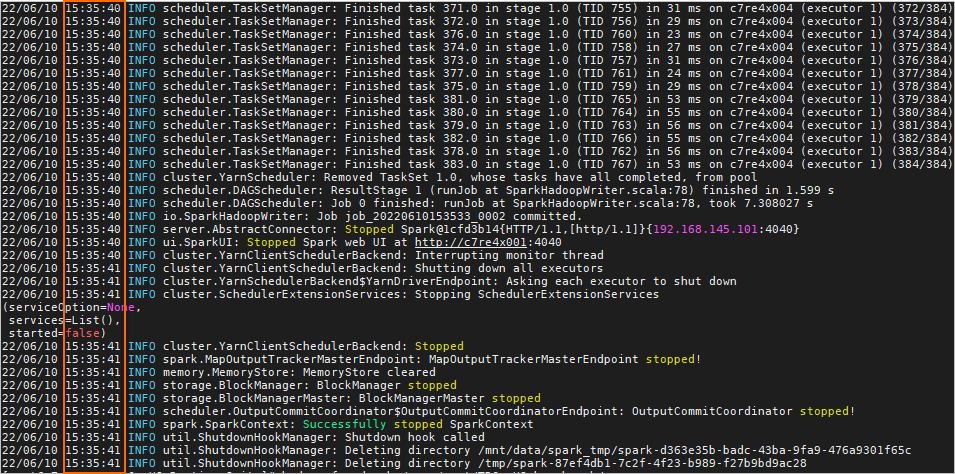 Catatan
CatatanUntuk membandingkan kinerja eRDMA, hapus konfigurasi plug-in spark-erdma dari direktori conf Spark atau gunakan Spark cluster tanpa eRDMA, jalankan pengujian Benchmark yang sama, lalu bandingkan hasilnya.