Kafka adalah layanan antrian pesan terdistribusi dengan throughput tinggi dan skalabilitas tinggi. Layanan ini banyak digunakan dalam analitik data besar, seperti pengumpulan log, agregasi data pemantauan, pemrosesan aliran, serta analisis online dan offline. Kafka merupakan komponen penting dalam ekosistem data besar. Topik ini menjelaskan cara menyinkronkan data dari ApsaraDB RDS for MySQL ke kluster Kafka yang dikelola sendiri menggunakan Data Transmission Service (DTS). Fitur sinkronisasi data memungkinkan Anda memperluas kemampuan pemrosesan pesan.
Prasyarat
Kluster Kafka telah dibuat dan versi Kafka berada di rentang 0.10.1.0 hingga 2.7.0.
Sebuah instance ApsaraDB RDS for MySQL telah dibuat. Untuk informasi lebih lanjut, lihat Buat Instance ApsaraDB RDS for MySQL.
Catatan Penggunaan
DTS menggunakan sumber daya baca dan tulis dari instance RDS sumber dan tujuan selama sinkronisasi data penuh awal. Hal ini dapat meningkatkan beban pada instance RDS. Jika performa instance tidak optimal, spesifikasinya rendah, atau volume datanya besar, layanan database mungkin menjadi tidak tersedia. Contohnya, DTS menggunakan sejumlah besar sumber daya baca dan tulis dalam kasus berikut: banyak kueri SQL lambat dilakukan pada instance RDS sumber, tabel tidak memiliki kunci utama, atau deadlock terjadi di instance RDS tujuan. Sebelum melakukan sinkronisasi data, evaluasi dampaknya terhadap performa instance RDS sumber dan tujuan. Kami menyarankan Anda menyinkronkan data selama jam-jam sepi, misalnya ketika utilisasi CPU instance RDS sumber dan tujuan kurang dari 30%.
Database sumber harus memiliki PRIMARY KEY atau batasan UNIQUE, dan semua bidang harus unik. Jika tidak, database tujuan mungkin berisi catatan data duplikat.
Penagihan
| Jenis Sinkronisasi | Biaya Konfigurasi Tugas |
| Sinkronisasi skema dan data penuh | Gratis. |
| Sinkronisasi data tambahan | Dikenakan biaya. Untuk informasi lebih lanjut, lihat Ikhtisar Penagihan. |
Batasan
Hanya tabel yang dapat dipilih sebagai objek untuk disinkronkan.
DTS tidak menyinkronkan data dalam tabel yang diubah namanya ke kluster Kafka tujuan jika nama tabel baru tidak termasuk dalam objek yang akan disinkronkan. Jika Anda ingin menyinkronkan data dalam tabel yang diubah namanya ke kluster Kafka tujuan, Anda harus reselect the objects to be synchronized. Untuk informasi lebih lanjut, lihat Tambahkan Objek ke Tugas Sinkronisasi Data.
Topologi sinkronisasi yang didukung
Sinkronisasi satu arah satu-ke-satu
Sinkronisasi satu arah satu-ke-banyak
Sinkronisasi satu arah banyak-ke-satu
Sinkronisasi satu arah bertingkat
Prosedur
Beli instance sinkronisasi data. Untuk informasi lebih lanjut, lihat Beli Instance DTS.
CatatanDi halaman pembelian, atur parameter Instance Sumber ke MySQL, parameter Instance Tujuan ke Kafka, dan parameter Topologi Sinkronisasi ke One-Way Synchronization.
Masuk ke Konsol Data Transmission Service (DTS).
Di panel navigasi di sebelah kiri, klik Data Synchronization.
Di bagian atas halaman Data Synchronization Tasks, pilih wilayah tempat instance tujuan berada.
Temukan tugas sinkronisasi data dan klik Configure Task di kolom Aksi.
Konfigurasikan instance sumber dan kluster tujuan.
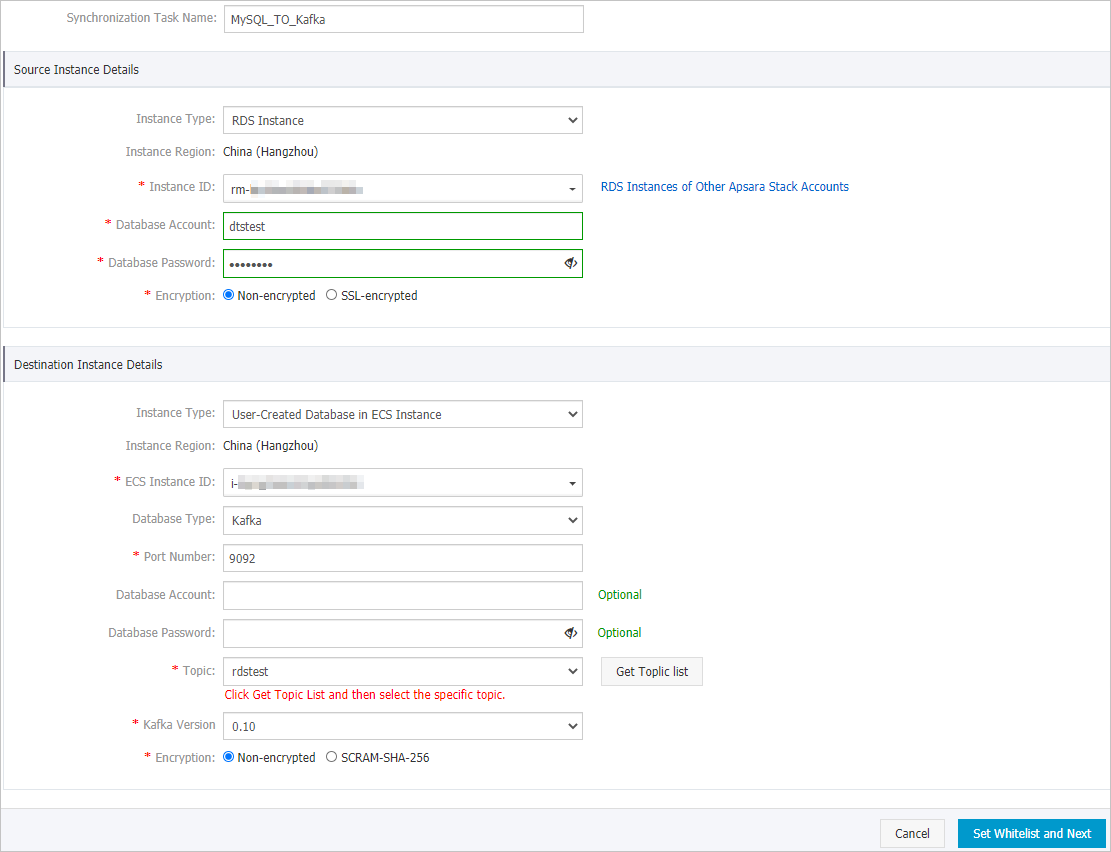
Bagian
Parameter
Deskripsi
Tidak Ada
Nama Tugas Sinkronisasi
Nama tugas yang DTS hasilkan secara otomatis. Kami sarankan Anda menentukan nama deskriptif yang memudahkan identifikasi tugas. Anda tidak perlu menggunakan nama tugas yang unik.
Detail Instance Sumber
Tipe Instance
Tipe instance sumber. Pilih RDS Instance.
Wilayah Instance
Wilayah sumber yang Anda pilih di halaman pembelian. Nilai parameter ini tidak dapat diubah.
ID Instance
ID instance ApsaraDB RDS sumber.
Akun Database
Akun yang digunakan untuk terhubung ke database sumber. Akun tersebut harus memiliki izin SELECT pada objek yang diperlukan dan izin REPLICATION CLIENT, REPLICATION SLAVE, dan SHOW VIEW.
Kata Sandi Database
Kata sandi akun database sumber.
Enkripsi
Menentukan apakah akan mengenkripsi koneksi ke instance sumber. Pilih Non-encrypted atau SSL-encrypted berdasarkan kebutuhan bisnis dan keamanan Anda. Jika Anda memilih SSL-encrypted, Anda harus mengaktifkan enkripsi SSL untuk instance ApsaraDB RDS sebelum mengonfigurasi tugas sinkronisasi data. Untuk informasi lebih lanjut, lihat Gunakan sertifikat cloud untuk mengaktifkan enkripsi SSL.
PentingParameter Encryption hanya tersedia di wilayah daratan Tiongkok dan wilayah China (Hong Kong).
Detail Instance Tujuan
Tipe Instance
Penerapan kluster Kafka. Dalam contoh ini, User-Created Database in ECS Instance dipilih.
CatatanJika Anda mengatur parameter Tipe Instance ke nilai lain, Anda harus menerapkan lingkungan jaringan untuk kluster Kafka. Untuk informasi lebih lanjut, lihat Ikhtisar Persiapan.
Wilayah Instance
Wilayah tujuan yang Anda pilih di halaman pembelian. Nilai parameter ini tidak dapat diubah.
ID Instance ECS
ID instance Elastic Compute Service (ECS) tempat kluster Kafka diterapkan.
CatatanJika Kafka diterapkan dalam arsitektur kluster, Anda hanya perlu memilih ID instance ECS tempat salah satu node kluster berada. DTS secara otomatis mendapatkan informasi topik dari semua node dalam kluster Kafka.
Tipe Database
Tipe database tujuan. Pilih Kafka.
Nomor Port
Nomor port layanan kluster Kafka. Nilai default: 9092.
Akun Database
Nama pengguna yang digunakan untuk masuk ke kluster Kafka. Jika tidak ada autentikasi yang diaktifkan untuk kluster Kafka, Anda tidak perlu memasukkan nama pengguna.
Kata Sandi Database
Kata sandi kluster Kafka. Jika tidak ada autentikasi yang diaktifkan untuk kluster Kafka, Anda tidak perlu memasukkan kata sandi.
Versi Kafka
Versi kluster Kafka tujuan.
Enkripsi
Menentukan apakah akan mengenkripsi koneksi ke kluster tujuan. Pilih Non-encrypted atau SCRAM-SHA-256 berdasarkan kebutuhan bisnis dan keamanan Anda.
Topik
Nama topik tempat data disinkronkan. Klik Get Topic List dan pilih nama topik dari daftar drop-down.
Topik yang Menyimpan Informasi DDL
Topik yang digunakan untuk menyimpan informasi DDL. Pilih topik dari daftar drop-down. Jika Anda tidak menentukan parameter ini, informasi DDL disimpan di topik yang ditentukan oleh parameter Topik.
Gunakan Kafka Schema Registry
Kafka Schema Registry menyediakan lapisan penyajian untuk metadata Anda. Ini menyediakan API RESTful untuk menyimpan dan mengambil skema Avro Anda.
No: tidak menggunakan Kafka Schema Registry.
Yes: menggunakan Kafka Schema Registry. Dalam hal ini, Anda harus memasukkan URL atau alamat IP yang terdaftar di Kafka Schema Registry untuk skema Avro Anda.
Di pojok kanan bawah halaman, klik Set Whitelist and Next.
Jika database sumber atau tujuan adalah instance database Alibaba Cloud, seperti ApsaraDB RDS for MySQL atau ApsaraDB for MongoDB, DTS secara otomatis menambahkan blok CIDR server DTS ke daftar putih alamat IP instance. Jika database sumber atau tujuan adalah database yang dikelola sendiri yang di-hosting pada instance Elastic Compute Service (ECS), DTS secara otomatis menambahkan blok CIDR server DTS ke aturan grup keamanan instance ECS, dan Anda harus memastikan bahwa instance ECS dapat mengakses database. Jika database yang dikelola sendiri di-hosting pada beberapa instance ECS, Anda harus menambahkan blok CIDR server DTS ke aturan grup keamanan setiap instance ECS secara manual. Jika database sumber atau tujuan adalah database yang dikelola sendiri yang diterapkan di pusat data atau disediakan oleh penyedia layanan cloud pihak ketiga, Anda harus menambahkan blok CIDR server DTS ke daftar putih alamat IP database secara manual untuk mengizinkan DTS mengakses database. Untuk informasi lebih lanjut, lihat Tambahkan Blok CIDR Server DTS.
PeringatanJika blok CIDR server DTS ditambahkan secara otomatis atau manual ke daftar putih database atau instance, atau ke aturan grup keamanan ECS, risiko keamanan mungkin timbul. Oleh karena itu, sebelum menggunakan DTS untuk menyinkronkan data, Anda harus memahami dan mengakui potensi risiko serta mengambil langkah-langkah pencegahan, termasuk tetapi tidak terbatas pada langkah-langkah berikut: meningkatkan keamanan nama pengguna dan kata sandi, membatasi port yang diekspos, mengotentikasi panggilan API, secara berkala memeriksa daftar putih atau aturan grup keamanan ECS dan melarang blok CIDR yang tidak sah, atau menghubungkan database ke DTS menggunakan Express Connect, VPN Gateway, atau Smart Access Gateway.
Pilih objek yang akan disinkronkan.
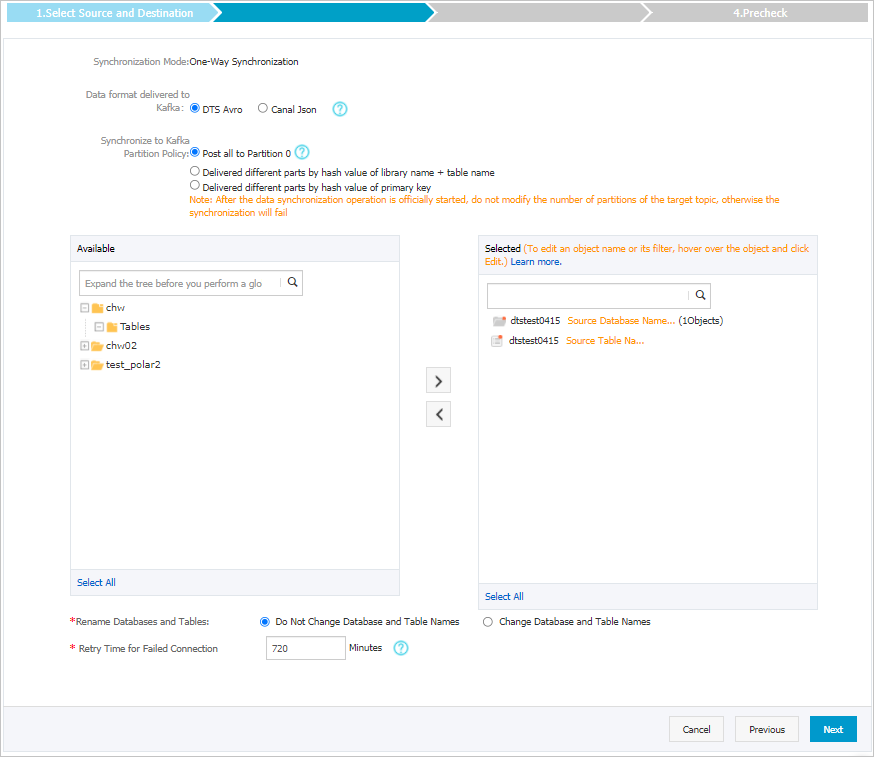
Parameter
Deskripsi
Data Format in Kafka
Data yang disinkronkan ke kluster Kafka disimpan dalam format Avro atau Canal JSON. Untuk informasi lebih lanjut, lihat Format data dalam antrian pesan.
Policy for Shipping Data to Kafka Partitions
Kebijakan yang digunakan untuk menyinkronkan data ke partisi Kafka. Pilih kebijakan berdasarkan kebutuhan bisnis Anda. Untuk informasi lebih lanjut, lihat Tentukan kebijakan untuk menyinkronkan data ke partisi Kafka.
Objek yang akan disinkronkan
Pilih satu atau lebih tabel dari bagian Available dan klik ikon
 untuk menambahkan tabel ke bagian Selected.Catatan
untuk menambahkan tabel ke bagian Selected.CatatanDTS memetakan nama tabel ke nama topik yang Anda pilih di Langkah 6. Anda dapat menggunakan fitur pemetaan nama objek untuk mengubah topik yang disinkronkan ke kluster tujuan. Untuk informasi lebih lanjut, lihat Ubah nama objek yang akan disinkronkan.
Ubah Nama Database dan Tabel
Anda dapat menggunakan fitur pemetaan nama objek untuk mengubah nama objek yang disinkronkan ke instance tujuan. Untuk informasi lebih lanjut, lihat Pemetaan Nama Objek.
Waktu Ulang untuk Koneksi Gagal
Secara default, jika DTS gagal terhubung ke database sumber atau tujuan, DTS mencoba kembali dalam waktu 720 menit (12 jam) ke depan. Anda dapat menentukan waktu percobaan ulang berdasarkan kebutuhan Anda. Jika DTS berhasil terhubung kembali ke database sumber dan tujuan dalam waktu yang ditentukan, DTS melanjutkan tugas sinkronisasi data. Jika tidak, tugas sinkronisasi data gagal.
CatatanSaat DTS mencoba kembali koneksi, Anda dikenakan biaya untuk instance DTS. Kami menyarankan Anda menentukan waktu percobaan ulang berdasarkan kebutuhan bisnis Anda. Anda juga dapat melepaskan instance DTS sesegera mungkin setelah instance sumber dan tujuan dilepaskan.
Di pojok kanan bawah halaman, klik Next.
Konfigurasikan sinkronisasi awal.

Parameter
Deskripsi
Initial Synchronization
Pilih kedua opsi Initial Schema Synchronization dan Initial Full Data Synchronization. DTS menyinkronkan skema dan data historis objek yang diperlukan, lalu menyinkronkan data tambahan.
Filter options
Ignore DDL in incremental synchronization phase dipilih secara default. Dalam hal ini, DTS tidak menyinkronkan operasi DDL yang dilakukan pada database sumber selama sinkronisasi data tambahan.
Di pojok kanan bawah halaman, klik Precheck.
CatatanSebelum Anda dapat memulai tugas sinkronisasi data, DTS melakukan pemeriksaan awal. Anda hanya dapat memulai tugas sinkronisasi data setelah tugas tersebut lolos pemeriksaan awal.
Jika tugas gagal lolos pemeriksaan awal, Anda dapat mengklik ikon
 di sebelah setiap item yang gagal untuk melihat detailnya.
di sebelah setiap item yang gagal untuk melihat detailnya.Setelah Anda menyelesaikan masalah berdasarkan detail tersebut, mulai pemeriksaan awal baru.
Jika Anda tidak perlu menyelesaikan masalah, ignore the failed items dan initiate a new precheck.
Tutup kotak dialog Precheck setelah pesan berikut ditampilkan: Precheck Passed. Kemudian, tugas sinkronisasi data dimulai.
Anda dapat melihat status tugas sinkronisasi data di halaman Data Synchronization.
