Lakukan segmentasi teks bahasa Tiongkok dalam skala besar di MaxCompute menggunakan pustaka open source Jieba pada node PyODPS 3 di DataWorks. Jika kamus bawaan Jieba tidak mencakup istilah spesifik domain Anda, unggah kamus kustom sebagai resource MaxCompute untuk memperluas hasil segmentasi.
Kasus penggunaan umum mencakup analisis teks, pengambilan informasi, penambangan teks, ekstraksi fitur, pembuatan mesin pencari, penerjemahan mesin, dan pelatihan model bahasa.
Langkah-langkah dalam topik ini hanya bersifat referensi. Jangan menggunakannya di lingkungan produksi.
Prasyarat
Sebelum memulai, pastikan Anda telah memiliki:
-
Ruang kerja DataWorks. Lihat Create and manage workspaces.
-
Sumber data MaxCompute yang telah ditambahkan dan dikaitkan dengan ruang kerja. Lihat Add a MaxCompute data source and associate the data source with a workspace.
Latar Belakang
Node PyODPS DataWorks memungkinkan Anda menulis kode Python dan menggunakan MaxCompute SDK for Python secara langsung dalam alur kerja. Terdapat dua jenis node yang tersedia:
| Jenis node | Dukungan Python | Catatan |
|---|---|---|
| PyODPS 3 | Hanya Python 3.X | Mendukung instalasi pip; direkomendasikan untuk pengembangan baru |
| PyODPS 2 | Python 2.X dan 3.X | Gunakan hanya jika Anda memerlukan Python 2.X |
Untuk proyek baru, gunakan node PyODPS 3. Lihat Develop a PyODPS 3 task.
Persiapan: unduh paket Jieba
Unduh paket Jieba open source dari GitHub.
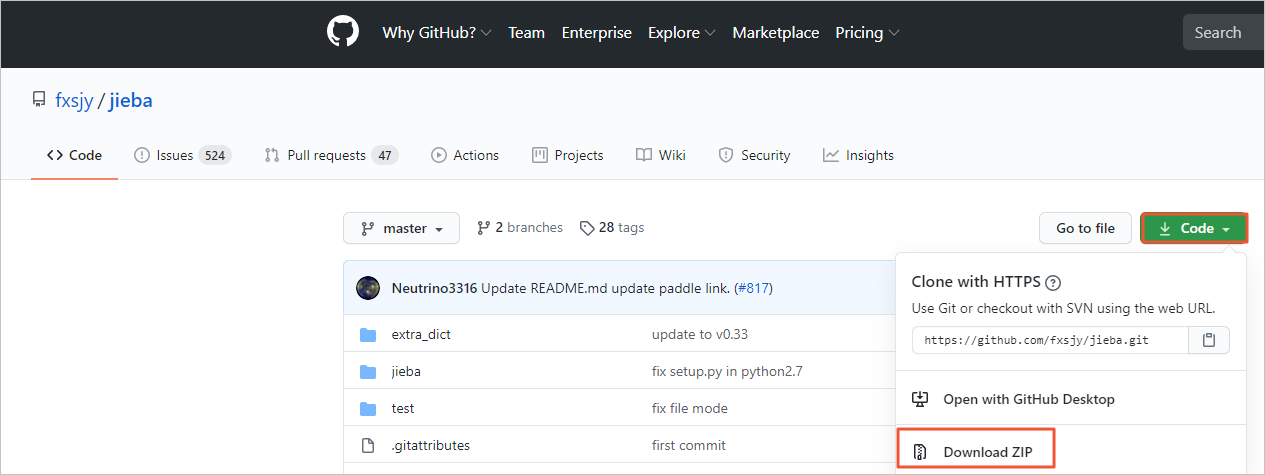
Latihan 1: Segmentasi teks dengan kamus Jieba bawaan
Langkah 1: Buat alur kerja
Lihat Buat alur kerja.
Langkah 2: Unggah paket Jieba sebagai resource MaxCompute
-
Klik kanan nama alur kerja dan pilih Create Resource > MaxCompute > Archive.
-
Pada kotak dialog Create Resource, atur parameter berikut lalu klik Create.
Parameter Deskripsi File Klik Upload dan pilih file jieba-master.zipyang telah Anda unduh.Name Masukkan nama resource. Pada latihan ini, gunakan jieba-master.zip. Nama resource dapat berbeda dari nama file tetapi harus mengikuti konvensi penamaan.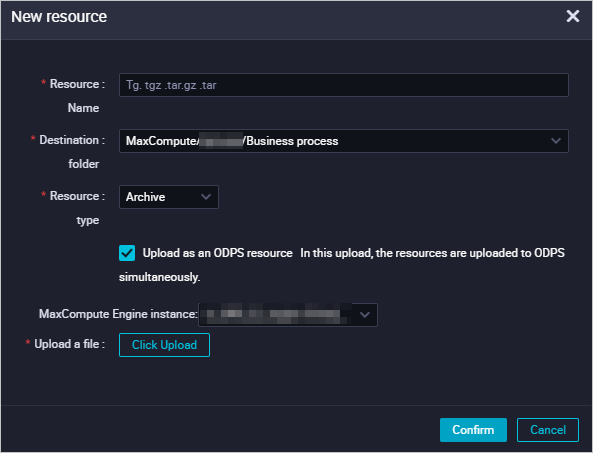
-
Klik ikon
 di bilah alat atas untuk melakukan commit terhadap resource tersebut.
di bilah alat atas untuk melakukan commit terhadap resource tersebut.
Langkah 3: Buat tabel input dan output
Buat dua tabel:
-
jieba_test— menyimpan data teks input -
jieba_result— menyimpan output segmentasi
Untuk membuat tabel, klik kanan nama alur kerja dan pilih Create Table > MaxCompute > Table. Konfigurasikan tabel di kotak dialog dan jalankan pernyataan DDL berikut untuk menentukan skema. Setelah membuat setiap tabel, lakukan commit ke lingkungan pengembangan. Lihat Create and manage MaxCompute tables.
-- Tabel input: menyimpan data uji
CREATE TABLE jieba_test (
`chinese` string,
`content` string
);
-- Tabel output: menyimpan hasil segmentasi
CREATE TABLE jieba_result (
`chinese` string
);Langkah 4: Impor data uji
-
Unduh jieba_test.csv ke mesin lokal Anda.
-
Pada panel Scheduled Workflow di halaman DataStudio, klik ikon
 untuk membuka Data Import Wizard.
untuk membuka Data Import Wizard. -
Masukkan
jieba_testdi kolom nama tabel, pilih tabel tersebut, lalu klik Next. -
Unggah
jieba_test.csv, konfigurasikan pengaturan unggah, pratinjau data, lalu klik Next. -
Pilih By Name lalu klik Import Data.
Langkah 5: Buat node PyODPS 3
-
Klik kanan nama alur kerja dan pilih Create Node > MaxCompute > PyODPS 3.
-
Pada kotak dialog Create Node, atur Name menjadi
word_splitlalu klik Confirm.
Langkah 6: Jalankan kode segmentasi
Tempel kode berikut ke dalam node word_split lalu jalankan. Kode ini melakukan segmentasi kolom chinese di jieba_test, menulis hasilnya ke jieba_result, dan mencetak 10 baris pertama.
def test(input_var):
import jieba
result = jieba.cut(input_var, cut_all=False)
return "/ ".join(result)
hints = {
'odps.isolation.session.enable': True,
'odps.stage.mapper.split.size': 64, # Mengontrol ukuran split input untuk meningkatkan paralelisme eksekusi
}
libraries = ['jieba-master.zip'] # Menyediakan paket Jieba bagi semua node pekerja
src_df = o.get_table('jieba_test').to_df()
result_df = src_df.chinese.map(test).persist('jieba_result', hints=hints, libraries=libraries)
print(result_df.head(10))odps.stage.mapper.split.size dapat digunakan untuk meningkatkan paralelisme eksekusi. Lihat Flag parameters.Langkah 7: Lihat hasil
Tersedia dua opsi:
-
Tab Runtime Log di bagian bawah halaman — cocok untuk memeriksa output secara cepat selama pengembangan.
-
Ad Hoc Query di panel navigasi kiri DataStudio — memungkinkan Anda melakukan kueri terhadap seluruh set hasil di tabel
jieba_result.select * from jieba_result;
Latihan 2: Segmentasi teks dengan kamus kustom
Jika kamus bawaan Jieba melewatkan istilah spesifik domain, unggah kamus kustom sebagai resource File MaxCompute.
Di PyODPS, user-defined function (UDF) yang membaca resource MaxCompute harus ditulis sebagai fungsi closure atau fungsi kelas yang dapat dipanggil.
Untuk membuat fungsi MaxCompute yang mereferensikan UDF kompleks, lihat Create and use a MaxCompute function.
Langkah 1: Buat resource kamus kustom
-
Klik kanan nama alur kerja dan pilih Create Resource > MaxCompute > File.
-
Pada kotak dialog Create Resource, atur Name menjadi
key_words.txtlalu klik Create. -
Pada tab konfigurasi
key_words.txt, masukkan konten kamus kustom, lalu simpan dan lakukan commit terhadap resource tersebut. Contoh berikut menambahkan dua istilah spesifik domain. Sesuaikan kontennya berdasarkan kebutuhan Anda.增量备份 安全合规
Langkah 2: Jalankan kode segmentasi dengan kamus kustom
def test(resources):
import jieba
fileobj = resources[0]
jieba.load_userdict(fileobj)
def h(input_var): # Panggil fungsi h() bersarang untuk memuat kamus dan melakukan segmentasi teks.
result = jieba.cut(input_var, cut_all=False)
return "/ ".join(result)
return h
hints = {
'odps.isolation.session.enable': True,
'odps.stage.mapper.split.size': 64,
}
libraries = ['jieba-master.zip']
src_df = o.get_table('jieba_test').to_df()
file_object = o.get_resource('key_words.txt') # Panggil fungsi get_resource() untuk mereferensikan resource MaxCompute.
mapped_df = src_df.chinese.map(test, resources=[file_object]) # Panggil fungsi map untuk mentransfer parameter resources.
result_df = mapped_df.persist('jieba_result2', hints=hints, libraries=libraries)
print(result_df.head(10))odps.stage.mapper.split.size dapat digunakan untuk meningkatkan paralelisme eksekusi. Lihat Flag parameters.Langkah 3: Lihat hasil
-
Tab Runtime Log di bagian bawah halaman — cocok untuk memeriksa output secara cepat selama pengembangan.
-
Ad Hoc Query di panel navigasi kiri DataStudio — memungkinkan Anda melakukan kueri terhadap seluruh set hasil di tabel
jieba_result2.select * from jieba_result2;