Berbeda dengan alur kerja terjadwal yang berjalan sesuai jadwal tetap (misalnya pukul 01.00 setiap hari), alur kerja yang dipicu merupakan model pemrosesan data berbasis event yang dijalankan sesuai permintaan. Alur ini berjalan ketika dipicu secara real-time oleh sinyal eksternal—seperti unggahan file, kedatangan pesan, panggilan API, atau klik manual—dan menyediakan responsivitas serta fleksibilitas tingkat tinggi.
Feature | Scheduled workflow | Triggered workflow |
Trigger mechanism | Fixed schedule (cron expression) | External signal (event, API, or manual) |
Execution model | Scheduled and predictable | Reactive and on-demand |
Use cases | T+1 batch data warehousing and scheduled reporting | Processing files upon arrival, integrating with business systems, and manual data patching |
Key advantages | Stability and predictable execution | Real-time responsiveness and flexibility |
Metode pemicu yang didukung
Alur kerja yang dipicu mendukung tiga metode pemicu berikut. Pilih salah satu berdasarkan skenario bisnis Anda.
Trigger method | Initiator | Core scenarios | Key points |
Event trigger | External event source (such as OSS or ApsaraMQ for Kafka) | Event-driven ETL: Process files upon arrival or trigger real-time computation from messages. | Anda harus create a trigger dan mengaitkannya dengan alur kerja. Hanya berlaku di lingkungan produksi. |
Manual trigger | User (developer or operator) | Ad-hoc tasks: Perform one-time data processing or analysis. | Dapat dijalankan secara manual baik di lingkungan pengembangan maupun produksi. Ini merupakan alternatif yang direkomendasikan untuk manual business processes. |
API trigger | External system (via OpenAPI) | System integration: Trigger data processing through callbacks from business systems such as CRM or ERP. | Memerlukan pemanggilan OpenAPI dengan izin yang sesuai. |
Panduan cepat: Membuat alur kerja yang dipicu secara manual
Bagian ini menjelaskan cara membuat dan menjalankan secara manual alur kerja yang dipicu secara sederhana.
Langkah 1: Membuat alur kerja yang dipicu
Buka halaman Workspaces di Konsol DataWorks. Di bilah navigasi atas, pilih wilayah yang diinginkan. Temukan ruang kerja yang dimaksud dan pilih pada kolom Actions.
Di panel navigasi kiri, klik
 . Di samping Business Flow, klik
. Di samping Business Flow, klik  > Create Workflow untuk membuka halaman Create Workflow.
> Create Workflow untuk membuka halaman Create Workflow.Di halaman Create Workflow, atur Scheduling Type menjadi Triggered Scheduling, masukkan Name alur kerja, lalu klik OK.
Langkah 2: Mengatur orkestrasi alur kerja dan mengembangkan node
Di bilah alat, klik + Add Node untuk membuka daftar node. Dari daftar jenis node di sebelah kiri, seret node Shell ke kanvas dan masukkan nama untuk membuatnya.
Klik ganda node Shell untuk membuka editor kode dan masukkan kode berikut:
echo "Hello, Trigger Workflow! Current time is ${bizdate}"Klik Save di bilah alat.
Langkah 3: Debug di lingkungan pengembangan
Kembali ke kanvas alur kerja dan klik ikon
 di bilah alat atas.
di bilah alat atas.Di kotak dialog yang muncul, masukkan Current run value untuk alur kerja (misalnya, jika tanggal saat ini adalah 20260310,
bizdateharus diganti dengan20260309).Di log eksekusi bagian bawah, Anda dapat melihat status eksekusi node dan output perintah
echo.
Langkah 4: Publikasikan dan jalankan di produksi
Di kanvas alur kerja, klik tombol Publish
 dan ikuti petunjuk untuk mempublikasikan alur kerja.
dan ikuti petunjuk untuk mempublikasikan alur kerja.Setelah alur kerja dipublikasikan, buka Operation Center > Manually Triggered Node O&M > Manual Task> Triggered Workflow.
Temukan alur kerja yang telah Anda publikasikan dan klik Run di kolom Actions.
Di kotak dialog yang muncul, klik Run lagi untuk memicu instans alur kerja di lingkungan produksi. Anda dapat melihat detail eksekusi ini di halaman Manual Instance.
Anda kini telah menguasai dasar-dasar penggunaan alur kerja yang dipicu. Selanjutnya, kita akan menjelajahi kemampuan berbasis event-nya yang lebih canggih.
Kasus penggunaan lanjutan: Membuat alur kerja yang dipicu oleh event
Skenario 1: Memproses file baru di OSS
Tujuan: Ketika file CSV baru diunggah ke direktori tertentu di OSS, otomatis picu alur kerja yang mencetak path file tersebut.
Langkah 1: Membuat pemicu OSS
Buka Operation Center > Tenant Schedule Setting > Trigger Management.
Klik Create Trigger dan konfigurasikan parameter berikut:
CatatanUntuk penjelasan parameter lengkap, lihat OSS trigger.
Trigger name: Masukkan nama kustom, misalnya
oss_new_file_trigger.Applicable workspace: Pilih ruang kerja target tempat alur kerja berada.
Trigger event type: Pilih
Object Storage Service (OSS).Trigger event: Pilih
oss:ObjectCreated:PutObjectatau event unggah lainnya.Bucket name: Pilih bucket OSS Anda.
File name: Tentukan path dan format file yang akan dipantau. Wildcard didukung. Misalnya, untuk memantau direktori
input/terhadap semua file.csv, masukkaninput/*.csv.Role configuration: Saat pertama kali menggunakan fitur ini, Anda harus menyelesaikan one-click authorization. Pilih role yang dihasilkan bernama
DataWorks-EventBridge-OSS-MNS-Role-*************.*************merepresentasikan ID acak 13 digit yang memastikan nama role bersifat unik.
Klik OK untuk membuat pemicu.
Langkah 2: Membuat dan mengaitkan alur kerja
Ikuti langkah-langkah dalam Panduan cepat: Membuat alur kerja yang dipicu secara manual untuk membuat alur kerja yang dipicu bernama
process_oss_file_workflow.Di sisi kanan kanvas alur kerja, pada panel Properties, pilih Scheduling Policy.
Dari daftar drop-down Trigger, pilih
oss_new_file_triggeryang baru saja Anda buat.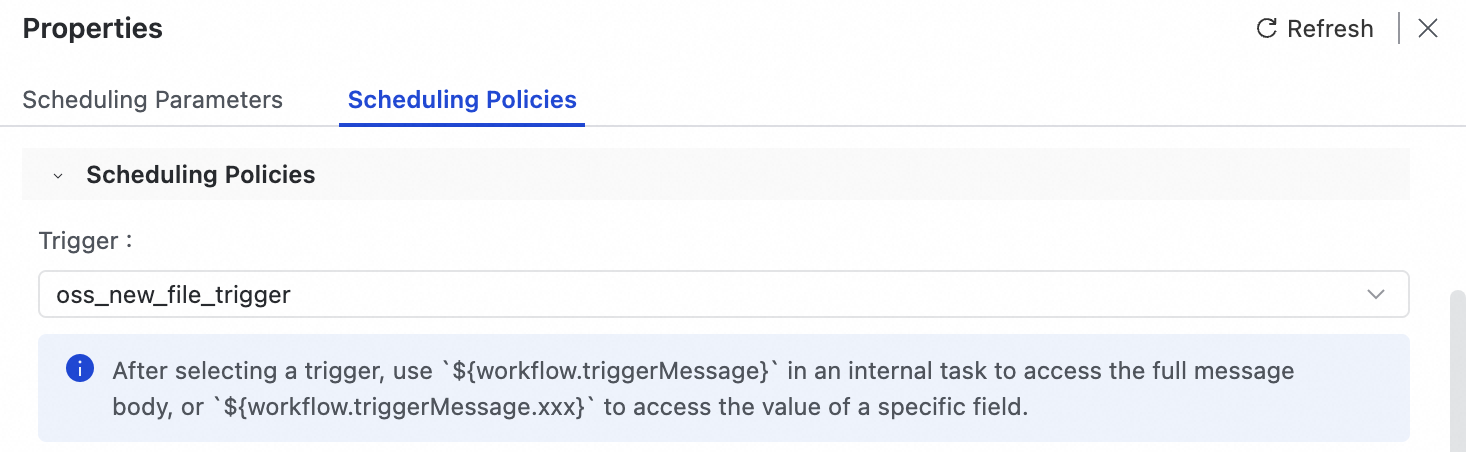
Langkah 3: Mengembangkan node dan mengurai parameter event
Di bilah alat, klik + Add Node untuk membuka daftar node. Dari daftar jenis node di sebelah kiri, seret node Shell ke kanvas dan masukkan nama untuk membuatnya.
Klik ganda node tersebut dan masukkan kode berikut untuk mendapatkan serta mencetak path file dari event pemicu.
# Ketika alur kerja dipicu, informasi event diteruskan melalui variabel bawaan workflow.triggerMessage. # Anda dapat menggunakan ${workflow.triggerMessage.data.oss.object.key} untuk mendapatkan path lengkap file yang diunggah. echo "========= Start Processing OSS File =========" message="${workflow.triggerMessage}" echo "Raw Value: ${message}" # Ekstrak path file dari pesan event. FILE_PATH="${workflow.triggerMessage.data.oss.object.key}" echo "A new file has arrived: ${FILE_PATH}" # Tambahkan logika pemrosesan spesifik Anda di sini. echo "========= Finish Processing OSS File ========="Catatan${workflow.triggerMessage} mengambil seluruh isi pesan event dalam format JSON. Anda dapat menemukan format pesan OSS spesifik di EventBridge dengan membuka Event Buses >
DATAWORKS_TRIGGER_FOR_BUCKET_<OSS_Bucket_Name>> Event Tracking > Event Details.
Langkah 4: Debug dan publikasikan
Debug:
Kembali ke kanvas alur kerja dan klik tombol Run
.Di kotak input Trigger Message Body, tempel event OSS simulasi dalam format JSON. Anda dapat menyalin contoh pesan dari halaman konfigurasi pemicu dan mengubah nilai field
key. Berikut contoh minimal:{ "data": { "oss":{ "object": { "key": "input/test_file_20260310.csv" } } } }Klik Run dan periksa log untuk memastikan bahwa
input/test_file_20260310.csvberhasil dicetak.
Publish: Setelah debugging berhasil, klik tombol Publish untuk men-deploy alur kerja ke lingkungan produksi. Pemicu berbasis event hanya aktif di lingkungan produksi.
Langkah 5: Verifikasi di produksi
Menggunakan konsol OSS atau klien, unggah file CSV ke bucket dan path yang telah Anda konfigurasikan di pemicu, misalnya direktori
input/.Buka
https://eventbridge.console.alibabacloud.com/<regionId>/event-bus/DATAWORKS_TRIGGER_FOR_BUCKET_<OssBucketName>/event-tracinguntuk mengkueri daftar event pemicu terbaru. Anda juga dapat mengklik Event Details untuk event tertentu guna melihat pesan pemicunya, yaitu nilai workflow.triggerMessage.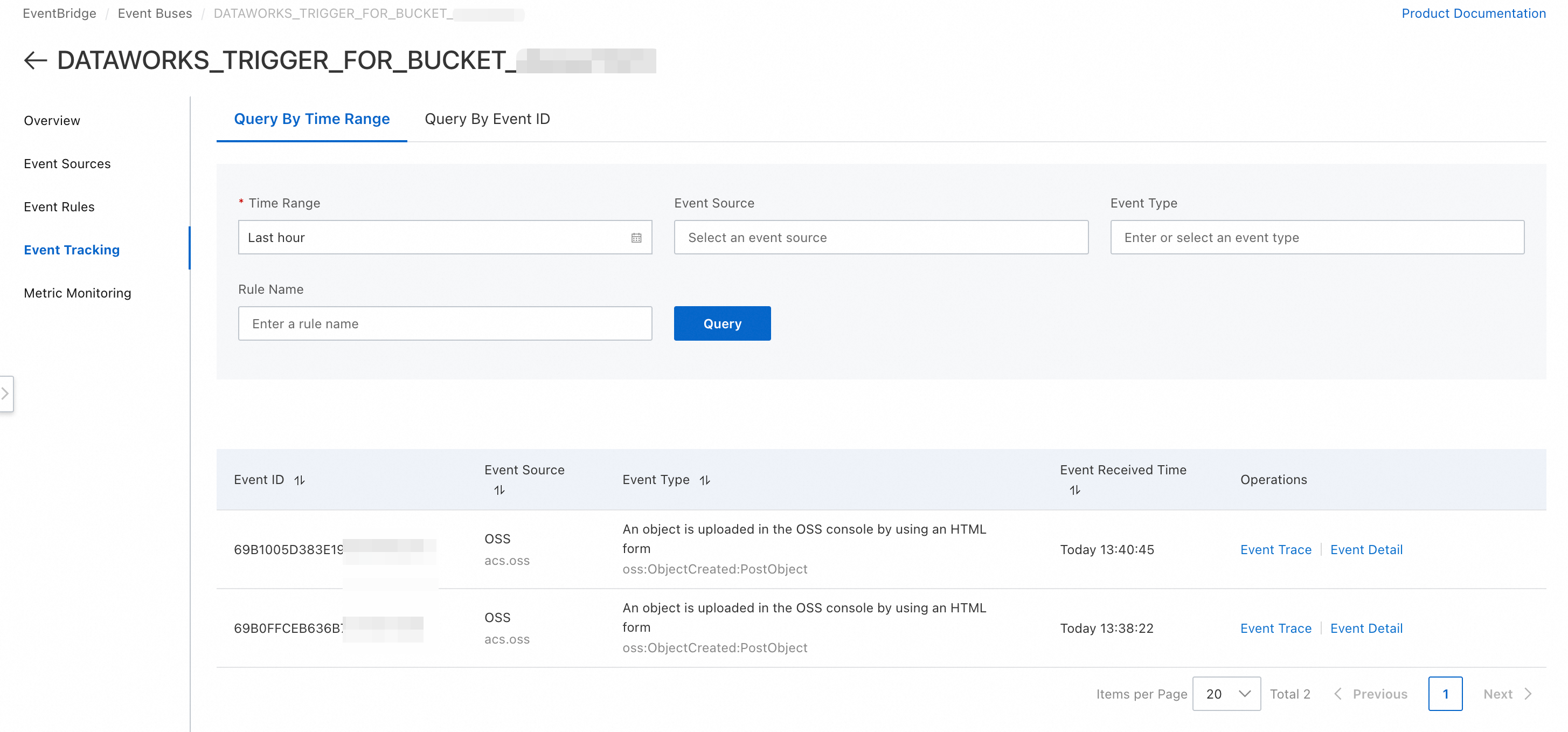
Di DataWorks, buka Operation Center > Manually Triggered Node O&M > Manual Task > Triggered Workflow. Alur kerja yang telah dipublikasikan
process_oss_file_workflowmuncul dalam daftar.
Setelah beberapa saat, instans alur kerja baru secara otomatis dipicu dan dijalankan. Anda dapat melihatnya di DataWorks pada Operation Center > Manually Triggered Node O&M > Manual Instance. Klik instans tersebut untuk melihat log-nya dan pastikan path file telah diproses dengan benar.
Praktik terbaik: Desain idempotensi
Event OSS mungkin dikirimkan lebih dari sekali karena faktor seperti fluktuasi jaringan. Untuk mencegah pemrosesan data duplikat, kami merekomendasikan penerapan idempotensi dalam logika bisnis Anda. Pendekatan umum adalah memeriksa tabel catatan—seperti tabel MaxCompute—sebelum memproses file. Gunakan ETag atau path unik file sebagai pengenal, dan lewati file tersebut jika sudah pernah diproses.
Skenario 2: Memproses pesan ApsaraMQ for Kafka
Tujuan: Pantau topik Kafka untuk log perilaku pengguna. Ketika pesan baru tiba, picu alur kerja untuk menguraikannya dan mengeksekusi logika berbeda berdasarkan isinya.
Langkah 1: Membuat pemicu Kafka
Buka Operation Center > Tenant Schedule Setting > Trigger Management dan klik Create Trigger.
Konfigurasikan parameter berikut:
Trigger name:
kafka_user_action_trigger.Trigger event type: Pilih ApsaraMQ for Kafka.
Kafka instance dan Topic: Pilih instance dan topik yang ingin Anda pantau.
ConsumerGroupId: Kami merekomendasikan memilih Quick Create. Sistem secara otomatis menghasilkan ID kelompok konsumen untuk menghindari konflik dengan aplikasi lain.
Key (Opsional): Anda dapat menentukan kunci pesan. Hanya pesan dengan kunci yang persis cocok yang akan memicu alur kerja.
Klik OK.
Langkah 2: Membuat dan mengaitkan alur kerja
Ikuti langkah-langkah dalam Panduan cepat: Membuat alur kerja yang dipicu secara manual untuk membuat alur kerja yang dipicu bernama
handle_user_action_workflow.Di sisi kanan kanvas alur kerja, pada panel Properties, pilih Scheduling Policy.
Dari daftar drop-down Trigger, pilih
kafka_user_action_triggeryang baru saja Anda buat.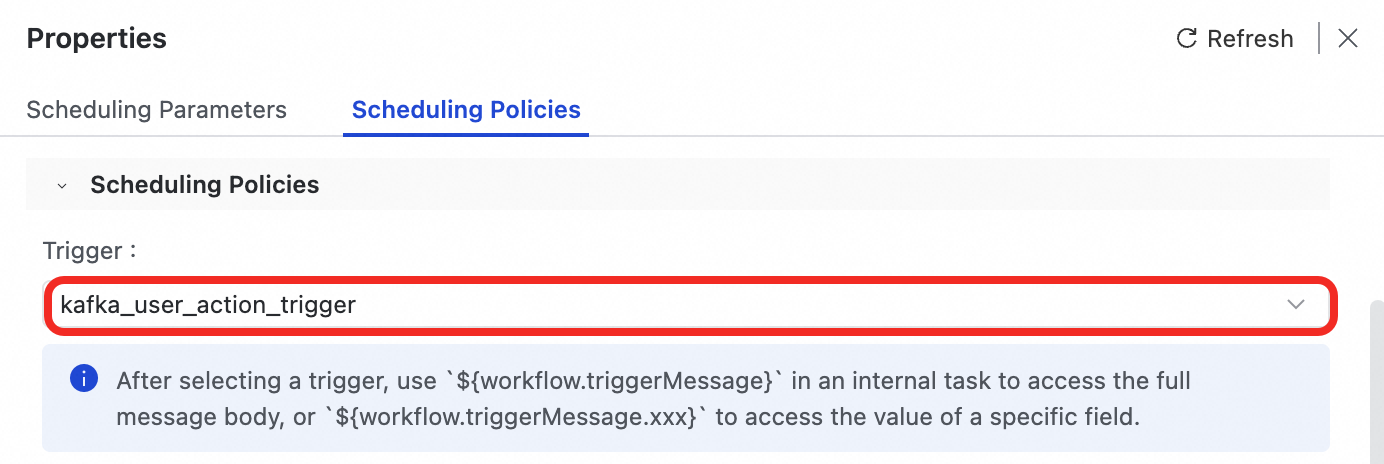
(Penting) Karena pesan mungkin tiba dengan frekuensi tinggi, kami merekomendasikan Anda mengonfigurasi maximum parallel instances. Misalnya, atur nilainya menjadi
100untuk mencegah lonjakan pesan membebani sumber daya penjadwalan.
Langkah 3: Mengembangkan node dan mengurai JSON bersarang
Asumsikan field value dari pesan Kafka berupa string JSON dengan format berikut: {"user_id": "1001", "action_type": "login", "timestamp": 1688888888}.
Di bilah alat, klik + Add Node untuk membuka daftar node. Dari daftar jenis node di sebelah kiri, seret node Python ke kanvas.
Masukkan kode berikut untuk mengurai pesan. Karena field
valueberupa string, Anda harus melakukan penguraian JSON kedua dalam kode Anda.import json # 1. Dapatkan field 'value' dari pesan Kafka, yang merupakan string terenkapsulasi JSON, melalui variabel bawaan. message_value_str = '${workflow.triggerMessage.value}' print(f'Received raw message value string: {message_value_str}') try: # 2. Uraikan string menjadi dictionary Python. message_data = json.loads(message_value_str) user_id = message_data.get("user_id") action_type = message_data.get("action_type") print(f"Successfully parsed message. User ID: {user_id}, Action: {action_type}") # 3. Eksekusi logika bisnis berbeda berdasarkan action_type. if action_type == 'login': # o.run_sql(f"INSERT OVERWRITE TABLE user_login_record PARTITION(ds='{bizdate}') VALUES ('{user_id}');") print("Processing login action...") elif action_type == 'purchase': print("Processing purchase action...") else: print("Unknown action type.") except json.JSONDecodeError as e: print(f"Error decoding JSON: {e}") # Tambahkan logika penanganan exception, seperti menulis pesan error ke tabel log khusus. raise e # Naikkan kembali exception untuk menandai node sebagai gagal, yang membantu troubleshooting.
Langkah 4: Debug dan publikasikan
Debug:
Kembali ke kanvas alur kerja dan klik tombol Run
.Di kotak input Trigger Message Body, tempel event Kafka simulasi. Perhatikan bahwa field
valueberupa string JSON yang telah di-escape.{ "topic": "user-behavior-topic", "key": "some-key", "value": "{\"user_id\": \"1001\", \"action_type\": \"login\", \"timestamp\": 1688888888}" }Jalankan dan periksa log untuk memastikan node Python berhasil mengurai nilai
user_iddanaction_type.
Publish: Setelah debugging berhasil, publikasikan alur kerja ke lingkungan produksi.
Langkah 5: Verifikasi di produksi
Kirim pesan dengan format yang benar ke Topik Kafka yang telah Anda konfigurasikan.
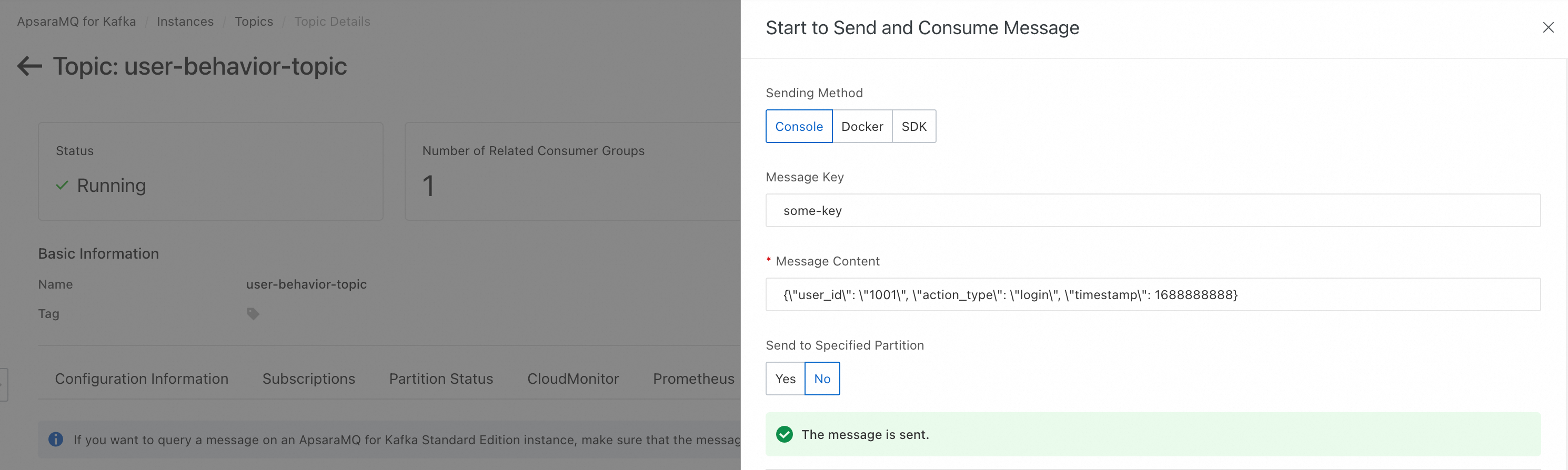
Di DataWorks, buka Operation Center > Manually Triggered Node O&M > Manual Task > Triggered Workflow. Alur kerja yang telah dipublikasikan
handle_user_action_workflowmuncul dalam daftar.
Di Operation Center > Manually Triggered Node O&M > Manual Instance > Triggered Workflow Instance, amati apakah instans alur kerja baru telah dipicu dan periksa log eksekusinya.

Praktik terbaik: Kontrol konkurensi dan pengurutan
Kontrol konkurensi: Selalu atur batas maksimum instans paralel yang wajar untuk menangani lonjakan pesan.
Jaminan urutan: Penjadwalan DataWorks tidak menjamin urutan pemrosesan pesan yang ketat. Jika Anda perlu memastikan pesan untuk pengguna atau partisi yang sama dieksekusi berurutan, Anda harus menerapkan kunci terdistribusi dalam kode bisnis Anda (misalnya, dengan menggunakan Redis atau MaxCompute). Alternatifnya, Anda dapat mendelegasikan logika pemrosesan ke mesin komputasi yang menjamin konsumsi berurutan berdasarkan partisi, seperti Flink.
Desain dan konfigurasi inti
Orkestrasi alur kerja
Mengatur orkestrasi alur kerja yang dipicu mirip dengan mengatur orkestrasi alur kerja terjadwal. Untuk informasi lebih lanjut, lihat Node and workflow orchestration.
Parameter penjadwalan
Di panel Properties di sisi kanan kanvas alur kerja, Anda dapat mengatur parameter global untuk alur kerja. Semua node di dalamnya dapat mereferensikan parameter tersebut.
Sintaks referensi: Di kode node, referensikan parameter alur kerja dengan format
${workflow.parameter_name}.Prioritas parameter: Parameter di DataWorks memiliki hubungan override hierarkis. Urutan prioritasnya adalah: parameter node > parameter alur kerja.
Untuk informasi lebih lanjut tentang parameter, lihat Parameter design and flow.
Kebijakan penjadwalan
Ketika beberapa alur kerja dipicu secara bersamaan dan menyebabkan bottleneck sumber daya, gunakan priority dan priority weighting policies untuk mengelola penjadwalan sumber daya dan memastikan tugas paling penting dieksekusi terlebih dahulu.
Menjamin kelangsungan bisnis inti: Atur prioritas lebih tinggi untuk alur kerja bisnis kritis agar selalu berjalan sebelum alur kerja non-kritis.
Mengurangi waktu eksekusi jalur kritis: Dalam satu instans alur kerja, Anda dapat menggunakan priority weighting policy untuk memengaruhi urutan eksekusi node. Misalnya, dengan kebijakan downward weighting, node pada jalur kritis yang memiliki lebih banyak dependensi hulu mendapatkan bobot dinamis lebih tinggi. Strategi ini memprioritaskan eksekusi mereka, sehingga memperpendek waktu eksekusi keseluruhan alur kerja.
Parameter
Description
Priority
Menentukan tingkat prioritas absolut instans alur kerja dalam antrean penjadwalan. Tingkat yang tersedia adalah 1, 3, 5, 7, dan 8, di mana angka lebih tinggi menunjukkan prioritas lebih tinggi. Tugas atau alur kerja berprioritas tinggi selalu dialokasikan sumber daya penjadwalan sebelum yang berprioritas rendah.
Priority weighting policy
Menentukan cara bobot masing-masing node (task) dihitung secara dinamis dalam tingkat prioritas yang sama. Node dengan bobot lebih tinggi diberi prioritas eksekusi.
No weighting: Semua node memiliki bobot garis dasar tetap.
Downward weighting: Bobot node disesuaikan secara dinamis. Semakin banyak node hulu yang menjadi dependensinya, semakin tinggi bobotnya. Strategi ini membantu memprioritaskan eksekusi node pada jalur kritis dalam grafik asiklik terarah (DAG). Bobot dihitung sebagai berikut:
Initial weight + Sum of the priorities of all its upstream nodes.
Maximum parallel instances
Mengontrol jumlah maksimum instans alur kerja ini yang dapat berjalan secara bersamaan untuk kontrol konkurensi dan perlindungan sumber daya. Ketika batas ini tercapai, instans baru yang dipicu masuk ke status menunggu. Anda dapat mengaturnya menjadi Unlimited atau nilai kustom hingga 100.000.
CatatanJika batas yang ditentukan melebihi kapasitas maksimum kelompok sumber daya, konkurensi aktual ditentukan oleh batas fisik kelompok sumber daya tersebut.
Sistem prioritas DataWorks mengikuti aturan override hierarkis: runtime specification > node-level configuration > workflow-level configuration.
Konfigurasi tingkat alur kerja (garis dasar): Dikonfigurasi di panel Scheduling Policy alur kerja, ini berfungsi sebagai pengaturan default untuk semua node.
Konfigurasi tingkat node (override): Anda dapat meng-override pengaturan tingkat alur kerja untuk node tertentu dengan mengatur priority lebih tinggi di panel Properties > Scheduling Policy-nya.
Spesifikasi runtime (sementara): Saat memicu eksekusi secara manual di Operation Center, Anda dapat menentukan prioritas dengan menggunakan sakelar Override Priority at Runtime. Konfigurasi ini memiliki prioritas tertinggi dan hanya berlaku untuk eksekusi saat ini, tanpa mengubah pengaturan permanen apa pun.
O&M dan manajemen
Pemantauan instans: Di halaman Manual Instance (terletak di Operation Center > Manually Triggered Node O&M), Anda dapat melihat, menjalankan ulang, menghentikan, dan memeriksa log untuk semua instans yang dipicu atau dijalankan secara manual.
Klon alur kerja: Di Business Flow, klik kanan alur kerja dan pilih Clone untuk menyalinnya dengan cepat ke alur kerja baru yang mencakup semua node dan dependensinya. Untuk informasi lebih lanjut, lihat Clone a workflow untuk alur kerja terjadwal.
Manajemen versi: Di panel Version di sisi kanan kanvas alur kerja, Anda dapat melihat, membandingkan, dan mengembalikan ke versi historis alur kerja. Untuk informasi lebih lanjut, lihat Version management untuk alur kerja terjadwal.
Batasan dan catatan
Lingkungan berlaku: Mekanisme event-driven triggering hanya berlaku setelah alur kerja dipublikasikan ke lingkungan produksi (Operation Center).
Jumlah node: Satu alur kerja mendukung maksimal 400 node. Kami merekomendasikan menjaga jumlah di bawah 100 untuk mempermudah pemeliharaan.
Batas konkurensi: Jumlah maksimum instans paralel adalah 100.000, tetapi kapasitas konkuren aktual dibatasi oleh spesifikasi kelompok sumber daya penjadwalan yang telah Anda beli.
Penjadwalan tingkat node: Saat mengonfigurasi penjadwalan di tingkat node, hanya priority yang dapat dikonfigurasi. priority weighting policy tidak didukung.
Jenis node yang tidak didukung: EMR Spark Streaming, Flink SQL Streaming, Flink JAR Streaming, Flink Python Streaming, dan node dependency check tidak didukung dalam alur kerja yang dipicu. Jenis-jenis tersebut hanya dapat dikembangkan dan dijalankan sebagai node independen.