Dependensi pada siklus sebelumnya merupakan dependensi lintas siklus di mana sebuah instans node bergantung pada keberhasilan eksekusi instans node lain dari siklus sebelumnya.
DataWorks mendukung tiga jenis dependensi lintas siklus berikut:
Node anak tingkat pertama
Dependensi node: Node saat ini bergantung pada node downstream langsungnya (node anak tingkat pertama). Misalnya, jika node A memiliki tiga node downstream—B, C, dan D—dependensi pada node anak tingkat pertama berarti instans saat ini dari node A bergantung pada penyelesaian yang berhasil dari instans node B, C, dan D pada siklus sebelumnya.
Skenario bisnis: Eksekusi node saat ini bergantung pada keberhasilan pembersihan data oleh node downstream-nya pada siklus sebelumnya. Data yang dibersihkan tersebut berasal dari tabel output node saat ini pada siklus sebelumnya. Untuk memverifikasi bahwa hasil pembersihan data sesuai ekspektasi, Anda dapat mengonfigurasi aturan Kualitas Data pada tabel output node downstream tersebut.
Node saat ini
Dependensi node: Ini adalah dependensi lintas siklus terhadap diri sendiri. Instans node saat ini bergantung pada penyelesaian yang berhasil dari instansnya sendiri pada siklus sebelumnya.
Skenario bisnis: Eksekusi node saat ini bergantung pada data bisnis yang dihasilkannya pada siklus sebelumnya. Untuk memverifikasi bahwa data tersebut sesuai ekspektasi, Anda dapat mengonfigurasi aturan pemantauan Kualitas Data pada tabel output node tersebut.
Kustom: Anda dapat menentukan secara manual node-node yang menjadi dependensi dengan memasukkan ID nodenya. Untuk menentukan beberapa node, pisahkan ID tersebut dengan koma (,), misalnya 12345,23456.
Dependensi node: Eksekusi node saat ini bergantung pada penyelesaian yang berhasil dari node kustom yang ditentukan pada siklus sebelumnya.
Skenario bisnis: Logika bisnis mengharuskan adanya dependensi terhadap output data yang berhasil dari proses bisnis lain, meskipun node saat ini tidak secara langsung memproses data tersebut.
Di Pusat Operasi, dependensi lintas siklus ditampilkan sebagai garis putus-putus untuk membedakannya dari dependensi dalam satu siklus.
Saat Anda membatalkan publikasi sebuah node, Anda harus menghapus dependensinya, baik dependensi lintas siklus (①) maupun dependensi dalam satu siklus (②).
Anda dapat memilih siklus mana dari node upstream yang akan dijadikan dependensi. Biasanya, Anda hanya memilih satu jenis dependensi: dalam satu siklus atau lintas siklus. Fitur auto-parsing secara default membuat dependensi dalam satu siklus terhadap node upstream. Untuk mengubahnya, Anda harus terlebih dahulu menghapus dependensi dalam satu siklus tersebut, lalu menambahkan dependensi lintas siklus. Untuk informasi lebih lanjut, lihat Logika dependensi penjadwalan.
Gambar berikut menunjukkan dependensi antar node dalam alur bisnis.
Laman Pusat Operasi menampilkan dependensi alur bisnis tersebut.
Gambar berikut menunjukkan contoh kode untuk node xc_create.
Seperti yang ditunjukkan pada gambar, kode SQL untuk node xc_create membuat dan mengisi dua tabel: xc_1 dan xc_2. Tabel-tabel ini kemudian ditetapkan sebagai output untuk node tersebut.
Gambar berikut menunjukkan contoh kode untuk node xc_select.
Seperti yang ditunjukkan pada gambar, kode SQL untuk node xc_select mengambil data dari tabel yang dihasilkan oleh node xc_create. Fitur auto-parsing secara otomatis mengidentifikasi node xc_create sebagai dependensi upstream untuk node xc_select.
Dependensi pada siklus sebelumnya: Node anak tingkat pertama
Dependensi node: Node saat ini bergantung pada penyelesaian yang berhasil dari node downstream langsungnya pada siklus sebelumnya. Misalnya, jika node A memiliki tiga node downstream (B, C, dan D), instans saat ini dari node A hanya akan dijalankan jika instans B, C, dan D pada siklus sebelumnya semuanya berhasil diselesaikan.
Skenario bisnis: Eksekusi node saat ini bergantung pada keberhasilan pembersihan data oleh node downstream-nya pada siklus sebelumnya. Data yang dibersihkan tersebut berasal dari tabel output node saat ini. Instans node saat ini hanya akan dijalankan jika node downstream-nya berhasil dijalankan pada siklus sebelumnya.
Node xc_create diatur untuk bergantung pada node anak tingkat pertamanya.
Laman Pusat Operasi menampilkan dependensi untuk setiap node.
Dependensi pada siklus sebelumnya: Node saat ini
Dependensi node: Instans node saat ini bergantung pada penyelesaian yang berhasil dari instansnya sendiri pada siklus sebelumnya. Jika instans sebelumnya tidak berhasil diselesaikan, instans saat ini akan diblokir.
Skenario bisnis: Eksekusi saat ini dari node tersebut bergantung pada status eksekusinya sendiri pada siklus sebelumnya. Untuk memudahkan pengamatan dalam contoh ini, node dijadwalkan berjalan setiap jam.
Buka laman untuk melihat dependensi node tersebut.
Untuk node yang dijadwalkan per jam dengan self-dependency (Dependensi pada siklus sebelumnya: Node saat ini), jika sebuah instans dari siklus sebelumnya tidak berhasil dijalankan, instans untuk jam berikutnya juga tidak akan dijalankan.
Misalnya, jika sebuah task per jam gagal atau tidak dijalankan, semua instans per jam berikutnya dari node tersebut sepanjang hari juga akan diblokir.
Dependensi pada siklus sebelumnya: Node kustom
Dependensi node: Node saat ini (xc_create) bergantung pada penyelesaian yang berhasil dari node kustom (1000374815) pada siklus sebelumnya. Dependensi ini diperlukan oleh logika bisnis, meskipun kode node saat ini tidak menggunakan tabel output dari node 1000374815.
Skenario bisnis: Logika bisnis mengharuskan adanya dependensi terhadap output data yang berhasil dari node 1000374815. Namun, node saat ini (xc_create) tidak memproses data bisnis tersebut, misalnya dengan melakukan query terhadap tabel output node 1000374815.
Node 1000374815 dipilih sebagai dependensi upstream kustom untuk node xc_create.
Buka laman untuk melihat dependensi node tersebut.
Konfigurasi lanjutan untuk dependensi lintas siklus
Dalam skenario percabangan, node percabangan biasanya memiliki beberapa node downstream, tetapi hanya satu yang dipilih untuk dijalankan sementara yang lainnya diatur sebagai dry-run. Properti dry-run ini diwariskan ke semua node anak dari cabang dry-run tersebut. Untuk menangani situasi ini, DataWorks menyediakan atribut penjadwalan: Do not propagate the dry-run property of ancestor nodes across cycles.
Namun, jika sebuah node di cabang downstream memiliki self-dependency terhadap siklus sebelumnya, dan cabangnya tidak dipilih pada siklus sebelumnya, node tersebut akan terus-menerus diatur sebagai dry-run.
Misalnya, jika node (I_am_the_left_one) diatur sebagai dry-run, node downstream-nya juga akan diatur sebagai dry-run.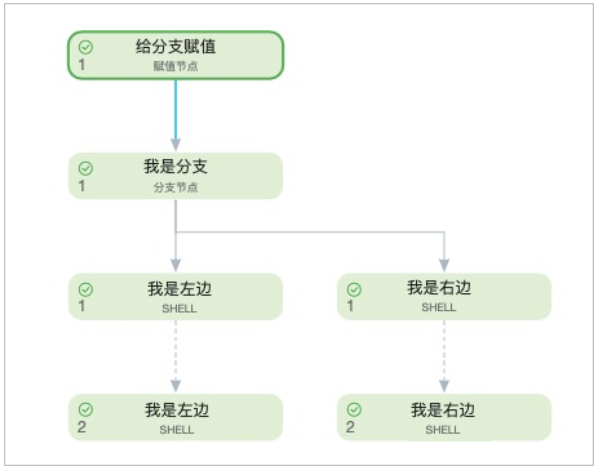
Untuk memastikan bahwa status eksekusi node pada siklus berikutnya ditentukan oleh pemilihan cabang pada siklus berikutnya—bukan oleh properti dry-run dari siklus sebelumnya—lakukan langkah-langkah berikut:
Di sisi kanan laman editor node, klik Scheduling Configuration.
Pada area Time Property, pilih Dependency on previous cycle.
Klik Advanced Configuration.
Pilih Do not propagate the dry-run property of ancestor nodes across cycles. Task tersebut tidak lagi dipengaruhi oleh properti dry-run dari node percabangan pada siklus sebelumnya.

Opsi ini hanya berlaku untuk properti dry-run yang diwariskan dari node leluhur percabangan yang tidak dipilih. Opsi ini tidak memengaruhi properti dry-run dari node biasa pada siklus sebelumnya.
Skenario umum untuk dependensi lintas siklus
Skenario 1:
Deskripsi skenario: Sebuah node harian bergantung pada node per jam, tetapi Anda ingin node harian tersebut dijalankan sesuai jadwal (misalnya, pukul 12.00) tanpa menunggu ke-24 instans per jam selesai.
Solusi: Konfigurasikan node upstream per jam dengan self-dependency dengan memilih . Atur waktu jadwal untuk node downstream harian menjadi pukul 12.00. Node harian tersebut tidak memerlukan dependensi lintas siklus.
Ketika instans pukul 12.00 dari node upstream per jam berhasil dijalankan, node downstream harian akan mulai dijalankan.
Skenario 2:
Deskripsi skenario: Sebuah node harian bergantung pada data hari sebelumnya dari node per jam.
Solusi: Konfigurasikan node downstream harian dengan , dan masukkan ID node upstream per jam tersebut.
Skenario 3:
Deskripsi skenario: Sebuah node per jam bergantung pada node harian. Saat node upstream harian selesai, waktu jadwal untuk beberapa siklus node downstream per jam telah lewat. Hal ini dapat menyebabkan beberapa instans node per jam dijalankan secara bersamaan.
Solusi: Konfigurasikan node downstream per jam dengan self-dependency dengan memilih . Hal ini memaksa instans per jam dijalankan secara berurutan, bukan secara bersamaan.
Skenario 4:
Skenario Real-time: Jika sebuah node bergantung pada data yang dihasilkannya pada epoch sebelumnya, bagaimana Anda memastikan waktu pembuatan data tersebut?
Solusi: Konfigurasikan node tersebut dengan self-dependency dengan memilih .