Topik ini menggunakan contoh untuk menjelaskan cara melakukan sinkronisasi data secara batch dari satu tabel MaxCompute ke ApsaraDB for ClickHouse serta menguraikan praktik terbaik untuk Konfigurasi Sumber Data, konektivitas jaringan, dan konfigurasi Tugas Sinkronisasi Batch.
Ikhtisar ApsaraDB for ClickHouse
ApsaraDB for ClickHouse adalah database berorientasi kolom yang dirancang untuk Pemrosesan Analitik Online (OLAP). Data Integration mendukung sinkronisasi data baik dari ApsaraDB for ClickHouse ke destinasi lain maupun dari sumber lain ke ApsaraDB for ClickHouse. Topik ini menyediakan contoh end-to-end tentang sinkronisasi batch data dari satu tabel MaxCompute ke ApsaraDB for ClickHouse.
Batasan
Sinkronisasi batch tabel tunggal hanya didukung untuk ApsaraDB for ClickHouse.
Prasyarat
Sumber data MaxCompute dan sumber data ApsaraDB for ClickHouse. Untuk informasi selengkapnya, lihat Konfigurasi Sumber Data.
Konektivitas jaringan antara resource group dan sumber data. Untuk informasi selengkapnya, lihat Solusi Konektivitas Jaringan.
Prosedur
Topik ini menjelaskan cara mengonfigurasi Tugas Sinkronisasi Batch di antarmuka pengguna DataStudio (versi baru).
Buat node dan konfigurasikan tugas
Topik ini tidak mencakup langkah-langkah umum untuk membuat dan mengonfigurasi node menggunakan Antarmuka tanpa kode. Untuk informasi tersebut, lihat Konfigurasi node di Antarmuka tanpa kode.
Konfigurasikan sumber dan destinasi
Pada bagian sumber data dan resource, atur Source ke sumber data MaxCompute Anda dan Destination ke sumber data ApsaraDB for ClickHouse Anda. Kemudian, pilih Resource Group dan uji konektivitasnya.
Konfigurasikan parameter Source (MaxCompute)
Parameter utama untuk tabel MaxCompute sumber dijelaskan di bawah ini.
Parameter | Deskripsi |
Tunnel Resource Group | Secara default, Public Transmission Resource digunakan. Jika Anda memiliki kuota Tunnel eksklusif, Anda dapat memilihnya dari daftar drop-down. |
Table | Pilih tabel MaxCompute yang ingin Anda sinkronkan. Jika Anda menggunakan ruang kerja DataWorks standar, pastikan tabel MaxCompute dengan nama dan skema tabel yang sama tersedia di lingkungan pengembangan maupun produksi.
|
Filtering Method | Mendukung Partition Filtering dan Data Filter.
|
Partition | Parameter ini wajib diisi ketika Filtering Method diatur ke Partition. Anda dapat memasukkan nilai kolom partisi.
|
If partitions do not exist, | Menentukan kebijakan yang diterapkan ketika partisi yang ditentukan tidak ada. Nilai yang valid:
|
Konfigurasikan parameter Destination (ApsaraDB for ClickHouse)
Parameter utama untuk tabel ApsaraDB for ClickHouse destinasi dijelaskan di bawah ini.
Parameter | Deskripsi |
Table | Pilih tabel ApsaraDB for ClickHouse tempat Anda ingin menyinkronkan data. Disarankan agar skema tabel untuk sumber data ApsaraDB for ClickHouse identik di lingkungan pengembangan dan produksi. Catatan Daftar tabel dari sumber data ApsaraDB for ClickHouse di lingkungan pengembangan ditampilkan di sini. Jika definisi tabel di lingkungan pengembangan dan produksi berbeda, tugas mungkin tampak berhasil dikonfigurasi tetapi gagal setelah dipublikasikan ke lingkungan produksi dengan pesan error bahwa tabel atau kolom tidak ditemukan. |
Primary or Unique Key Conflict Handling | Saat Anda memilih |
Statement Run Before Writing | Anda dapat menjalankan pernyataan SQL sebelum dan sesudah tugas sinkronisasi data sesuai kebutuhan. Misalnya, sebelum sinkronisasi harian, Anda dapat menjalankan pernyataan untuk membersihkan partisi harian yang sesuai, sehingga partisi tersebut kosong sebelum data baru ditulis. |
Statement Run After Writing | |
Batch Insert Size (Bytes) | Data ditulis ke ApsaraDB for ClickHouse secara batch. Parameter-parameter ini menentukan batas atas ukuran dalam byte dan jumlah catatan per batch. Ketika jumlah data yang di-cache mencapai ukuran byte atau jumlah catatan yang ditentukan, penulisan batch dipicu. Disarankan untuk mengatur Batch size (Bytes) ke 16777216 (16 MB) dan mengatur Batch size (Records) ke nilai besar berdasarkan ukuran catatan tunggal Anda. Hal ini memastikan bahwa penulisan batch terutama dipicu oleh ukuran batch dalam byte. Sebagai contoh, jika satu catatan berukuran 1 KB, Anda dapat mengatur Batch size (Bytes) ke 16777216 (16 MB) dan Batch size (Records) ke 20000 (yang lebih besar dari 16 MB/1 KB = 16384). Dalam kasus ini, penulisan dipicu setiap kali ukuran batch mencapai 16 MB. |
Data Records Per Write | |
If a batch write fails | Menentukan kebijakan penanganan exception yang terjadi selama penulisan batch ke ApsaraDB for ClickHouse:
|
Konfigurasikan pemetaan bidang
Setelah memilih sumber dan destinasi, Anda perlu menentukan pemetaan antara kolom sumber dan destinasi. Anda dapat memilih Map Fields with the Same Name, Map Fields in the Same Line, Delete All Mappings, atau Auto Layout.
Pengaturan lanjutan
Anda dapat mengonfigurasi pengaturan untuk tugas sinkronisasi offline, seperti Expected Maximum Concurrency dan Policy for Dirty Data Records. Dalam tutorial ini, Policy for Dirty Data Records diatur ke Disallow Dirty Data Records, sedangkan pengaturan lainnya menggunakan nilai default. Untuk informasi selengkapnya, lihat Konfigurasi Antarmuka tanpa kode.
Konfigurasikan dan jalankan tugas
Klik Run Configuration di sisi kanan halaman edit node Sinkronisasi Batch, konfigurasikan Resource Group dan Script Parameters untuk debug run, lalu klik Run di bilah alat atas untuk menguji apakah tautan sinkronisasi berjalan sukses.
Anda dapat mengklik
 di bilah navigasi kiri, lalu klik ikon baru di sebelah kanan Personal Directory untuk membuat file SQL baru. Jalankan pernyataan SQL berikut untuk mengkueri data di tabel destinasi dan memverifikasi bahwa data sesuai harapan.Catatan
di bilah navigasi kiri, lalu klik ikon baru di sebelah kanan Personal Directory untuk membuat file SQL baru. Jalankan pernyataan SQL berikut untuk mengkueri data di tabel destinasi dan memverifikasi bahwa data sesuai harapan.CatatanUntuk mengkueri data dengan cara ini, Anda harus bind ApsaraDB for ClickHouse sebagai resource komputasi di DataWorks.
Anda perlu mengklik Run Configuration di sisi kanan halaman edit file
.sql, tentukan Computing Resources, Type sumber data, dan Resource Group, lalu klik Run di bilah alat atas.
SELECT * FROM <your_clickhouse_destination_table_name> LIMIT 20;
Konfigurasikan penjadwalan dan publikasikan tugas
Klik Scheduling Settings di sebelah kanan tugas sinkronisasi offline. Setelah mengonfigurasi parameter Konfigurasi Penjadwalan untuk eksekusi terjadwal, klik Publish di bilah alat atas. Di panel Publish, ikuti petunjuk di layar untuk menyelesaikan publikasi.
Lampiran: Sesuaikan parameter memori
Jika peningkatan konkurensi tidak secara signifikan meningkatkan throughput sinkronisasi, Anda dapat menyesuaikan secara manual parameter memori untuk tugas sinkronisasi. Ikuti langkah-langkah berikut:
Klik Code Editor di bilah alat atas halaman Tugas Sinkronisasi Offline untuk mengalihkan tugas dari Antarmuka tanpa kode ke editor kode.

Pada bagian
settingsegmen JSON skrip, tambahkan parameterjvmOption. Parameter ini berformat-Xms${heapMem} -Xmx${heapMem} -Xmn${newMem}.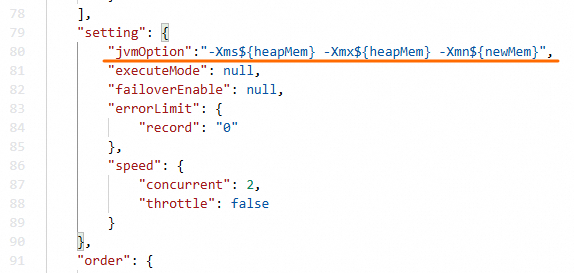
Di Antarmuka tanpa kode, sistem menghitung nilai ${heapMem} menggunakan rumus 768 MB + (tingkat konkurensi - 1) * 256 MB. Disarankan untuk mengatur ${heapMem} ke nilai yang lebih besar di editor kode dan mengatur ${newMem} menjadi sepertiga dari nilai ${heapMem}. Sebagai contoh, jika tingkat konkurensi adalah 8, nilai default untuk ${heapMem} di Antarmuka tanpa kode adalah 2560 MB, dan Anda dapat mengatur nilai yang lebih besar di editor kode, misalnya mengatur parameter jvmOption menjadi -Xms3072m -Xmx3072m -Xmn1024m.