Selama sinkronisasi data, data mentah mungkin memiliki format yang tidak konsisten, informasi berlebihan, atau tidak terstruktur. Fitur pemrosesan data bawaan pada task sinkronisasi offline DataWorks memungkinkan Anda membersihkan, memproses dengan bantuan AI, dan melakukan vektorisasi data secara langsung dalam pipeline sinkronisasi data, sehingga menyederhanakan arsitektur ekstrak, transformasi, dan muat (ETL).
Batasan
Fitur ini hanya tersedia di ruang kerja yang telah mengaktifkan versi baru Data Development.
Hanya kelompok sumber daya Serverless yang didukung.
Fitur ini saat ini hanya tersedia untuk beberapa saluran yang melakukan sinkronisasi tabel non-partisi tunggal secara offline.
Mengaktifkan pemrosesan data akan mengonsumsi unit komputasi (CU) tambahan. Pantau kuota sumber daya Anda.
Titik masuk konfigurasi
Pada halaman konfigurasi task sinkronisasi offline yang baru atau yang sudah ada, gulir ke bawah hingga bagian Pemrosesan data.
Secara default, fitur ini dinonaktifkan. Klik toggle untuk mengaktifkan modul pemrosesan data guna dikonfigurasi.
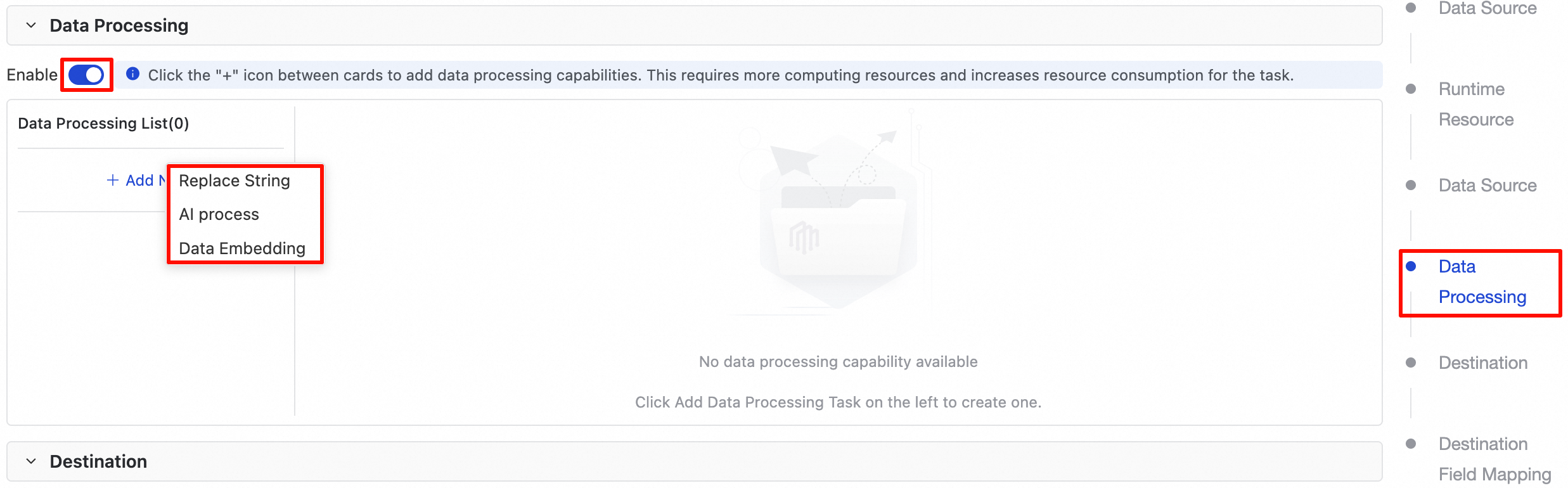
Fitur
Setelah mengaktifkan modul pemrosesan data, Anda dapat menambahkan satu atau beberapa aturan pemrosesan berikut sesuai kebutuhan.
1. Penggantian string
Penggantian string merupakan fitur pembersihan data dasar dan umum. Anda dapat menetapkan beberapa aturan penggantian untuk bidang-bidang berbeda dalam task saat ini.
Konfigurasi UI tanpa kode
Pada Data processing list, klik tombol + Add Node dan pilih String replacement untuk menambahkan aturan penggantian baru. Item konfigurasi dijelaskan sebagai berikut:
Item konfigurasi | Deskripsi |
Name | Masukkan nama kustom untuk aturan penggantian yang mudah dikenali. |
Description | (Opsional) Berikan deskripsi rinci mengenai tujuan aturan tersebut. |
Field name | Klik tombol + Add Rule untuk menambahkan aturan bidang. Pilih bidang dari daftar drop-down bidang tabel sumber untuk menerapkan aturan ini. |
Content to replace | Masukkan string asli yang akan dicari dan diganti. |
Replace with | Masukkan string baru. |
| Toggle untuk mengaktifkan ekspresi reguler. Ini memungkinkan Anda menggunakan ekspresi reguler untuk mencari string asli yang akan diganti. |
| Toggle untuk mengatur apakah pencarian konten yang akan diganti bersifat case-sensitive. Secara default, pencarian tidak case-sensitive. |
Anda dapat menambahkan beberapa aturan untuk penggantian detail halus terhadap konten berbeda di bidang-bidang berbeda. Misalnya, buat aturan untuk mengganti 'male' dengan '1' pada bidang gender, serta aturan lain untuk mengganti 'active' dengan 'valid' pada bidang status.
Pratinjau output data
Setelah mengonfigurasi aturan, klik Data output preview di pojok kanan atas bagian Pemrosesan data.
Pada kotak dialog yang muncul, konfigurasikan Input data. Dua metode didukung:
Otomatis: Sistem mengambil data dari output node leluhur secara default. Anda dapat mengklik Refetch upstream output untuk merefresh data.
Manual: Klik + Manually construct data untuk memasukkan nilai kustom untuk setiap bidang dalam satu baris data, atau untuk menguji kondisi batas tertentu seperti
NULLatau string kosong.
Klik tombol Preview di area Preview result.
Sistem menjalankan semua aturan pemrosesan yang telah dikonfigurasi dan menampilkan hasilnya di bawah. Bandingkan hasil tersebut dengan ekspektasi Anda untuk memverifikasi bahwa aturan telah dikonfigurasi dengan benar.
Hasil pratinjau hanya untuk pengujian dan referensi. Hasil eksekusi akhir bergantung pada waktu proses task yang sebenarnya.
Konfigurasi editor kode
Untuk mengonfigurasi pemrosesan data di editor kode, tambahkan objek JSON dengan "category": "map" dan "stepType": "stringreplace" ke modul `steps` pada skrip JSON. Untuk informasi lebih lanjut mengenai proses konfigurasi umum di editor kode, lihat Konfigurasi editor kode.
{
"category": "map",
"stepType": "stringreplace",
"parameter": {
"condition": [
{
"name": "<field_to_process>",
"replaceString": "<string_to_replace>",
"replaceByString": "<replacement_string>",
"useRegex": false,
"caseSensitive": false
}
]
},
"displayName": "<rule_name>",
"description": "<rule_description>"
}2. Pemrosesan berbantuan AI
Fitur ini memanggil model bahasa besar (LLM) bawaan untuk memproses konten bidang tertentu secara cerdas, sehingga menambahkan lebih banyak nilai bisnis pada data Anda.
Skenario inti:
Ringkasan konten: Ekstrak ringkasan utama dari blok teks besar, seperti ulasan produk atau artikel berita.
Ekstraksi informasi: Ekstrak informasi penting, seperti nama, alamat, dan detail kontak, dari teks tidak terstruktur.
Terjemahan teks: Terjemahkan konten bidang ke bahasa yang ditentukan.
Analisis sentimen: Tentukan sentimen teks (misalnya positif, negatif, atau netral).
Konfigurasi dan penggunaan:
Saat Anda mengklik Add Node, pilih Pemrosesan berbantuan AI. Untuk detail mengenai metode konfigurasi dan kasus penggunaan khas fitur ini, lihat Pemrosesan berbantuan AI.
3. Vektorisasi data
Vektorisasi data adalah proses mengonversi teks atau tipe data lainnya menjadi vektor matematis berdimensi tinggi menggunakan model penyematan. Vektor-vektor ini menangkap informasi semantik dari data dan merupakan langkah kunci dalam membangun aplikasi AI seperti Generasi yang Diperkaya dengan Pengambilan Data (RAG), pencarian semantik, dan sistem rekomendasi.
Skenario inti:
Membangun basis pengetahuan: Lakukan vektorisasi data teks dari dokumen, tiket, dan manual produk, lalu simpan di database vektor untuk dijadikan basis pengetahuan eksternal bagi LLM.
Rekomendasi personalisasi: Hitung kemiripan berdasarkan representasi vektor pengguna dan item untuk memberikan rekomendasi yang tepat.
Konfigurasi dan penggunaan:
Saat Anda mengklik Add Node, pilih Data vectorization. Kemudian, pilih bidang yang akan diproses dan model penyematan yang akan digunakan. Untuk petunjuk konfigurasi lengkap dan contoh, lihat Pemrosesan vektorisasi.