Sebelum memulai sesi interaktif di ChatBI, Anda harus menentukan cakupan data yang akan dianalisis dengan menggunakan dataset. Dataset dapat berupa tabel dari sumber data target atau file lokal.
Prasyarat
serverless resource group telah dibuat di wilayah tempat Anda menggunakan ChatBI.
Catatan penggunaan
-
Untuk dataset dari sumber data, hanya sumber data Hologres, MaxCompute, StarRocks, dan MySQL yang didukung.
-
Untuk dataset dari file lokal, hanya format
xls,xlsx, dancsvyang didukung. Anda dapat mengunggah maksimal 10 file, dengan ukuran setiap file tidak melebihi 1 GB.
Buat dataset
-
Buka halaman ChatBI.
Login ke Alibaba Cloud dan buka halaman ChatBI Intelligent Data Insights. Pilih titik akses yang sesuai dengan wilayah sumber daya DataWorks Anda, seperti dataset dan serverless resource group Anda.
-
Di panel navigasi sebelah kiri, klik Dataset untuk membuka halaman Datasets. Lalu, klik Create Dataset.
-
Pada halaman Create Dataset, konfigurasikan parameter berikut:
-
Jika tipe dataset adalah Data Source:
Parameter
Description
Basic Information
Name
Masukkan nama kustom untuk dataset.
Type
Tipe dataset. Nilai yang valid:
-
Data Source
-
Local File
Pilih Data Source.
Data Source Type
Tipe sumber data. Nilai yang valid:
-
Hologres
-
MaxCompute
-
StarRocks
-
MySQL
Data source information
Parameter konfigurasi bervariasi tergantung tipe sumber data.
Contohnya, untuk Hologres, Anda harus mengonfigurasi Region, Hologres Instance, dan Database Name.
Resource Group
Pilih DataWorks serverless resource group, yang digunakan untuk mengakses sumber data guna menjalankan kueri data pada sesi berikutnya.
Test Network Connectivity
Uji konektivitas jaringan antara DataWorks serverless resource group yang dipilih dan sumber data.
Select Destination Table
Select destination tables
Setelah menyelesaikan konfigurasi Basic Information, klik Next untuk menuju langkah Select Destination Table.
Pada daftar To Be Selected, pilih tabel tujuan lalu klik
 untuk menambahkannya ke daftar Selected. Tabel yang dipilih akan ditambahkan ke dataset saat ini.
untuk menambahkannya ke daftar Selected. Tabel yang dipilih akan ditambahkan ke dataset saat ini. -
-
Jika tipe dataset adalah Local File:
Parameter
Description
Basic Information
Name
Masukkan nama kustom untuk dataset.
Type
Tipe dataset. Nilai yang valid:
-
Data Source
-
Local File
Pilih Local File.
Upload local files
Hanya format
xls,xlsx, dancsvyang didukung. Anda dapat mengunggah maksimal 10 file, dan ukuran setiap file tidak boleh melebihi 1 GB. -
-
-
Setelah menyelesaikan konfigurasi dataset, klik Next untuk menuju langkah Data Insight. Sistem secara otomatis memindai dataset untuk mengekstraksi karakteristik nilai data, yang meningkatkan akurasi analisis selama sesi.
-
Proses data insight mungkin memakan waktu lama. Anda dapat langsung mengklik Completed dan melihat hasilnya nanti di dataset.
Lihat dataset
-
Di panel navigasi sebelah kiri, klik Dataset untuk membuka halaman Datasets.
-
Temukan kartu dataset tujuan, lalu klik untuk membuka halaman detail dataset.
-
Pada halaman detail dataset, bagian atas menampilkan informasi dasar dataset (termasuk tipe, jumlah tabel/file, dan pembuat), sisi kiri menampilkan daftar tabel/file, dan sisi kanan menampilkan informasi dasar serta pratinjau data tiap tabel/file (maksimal 20 catatan dapat dipratinjau).
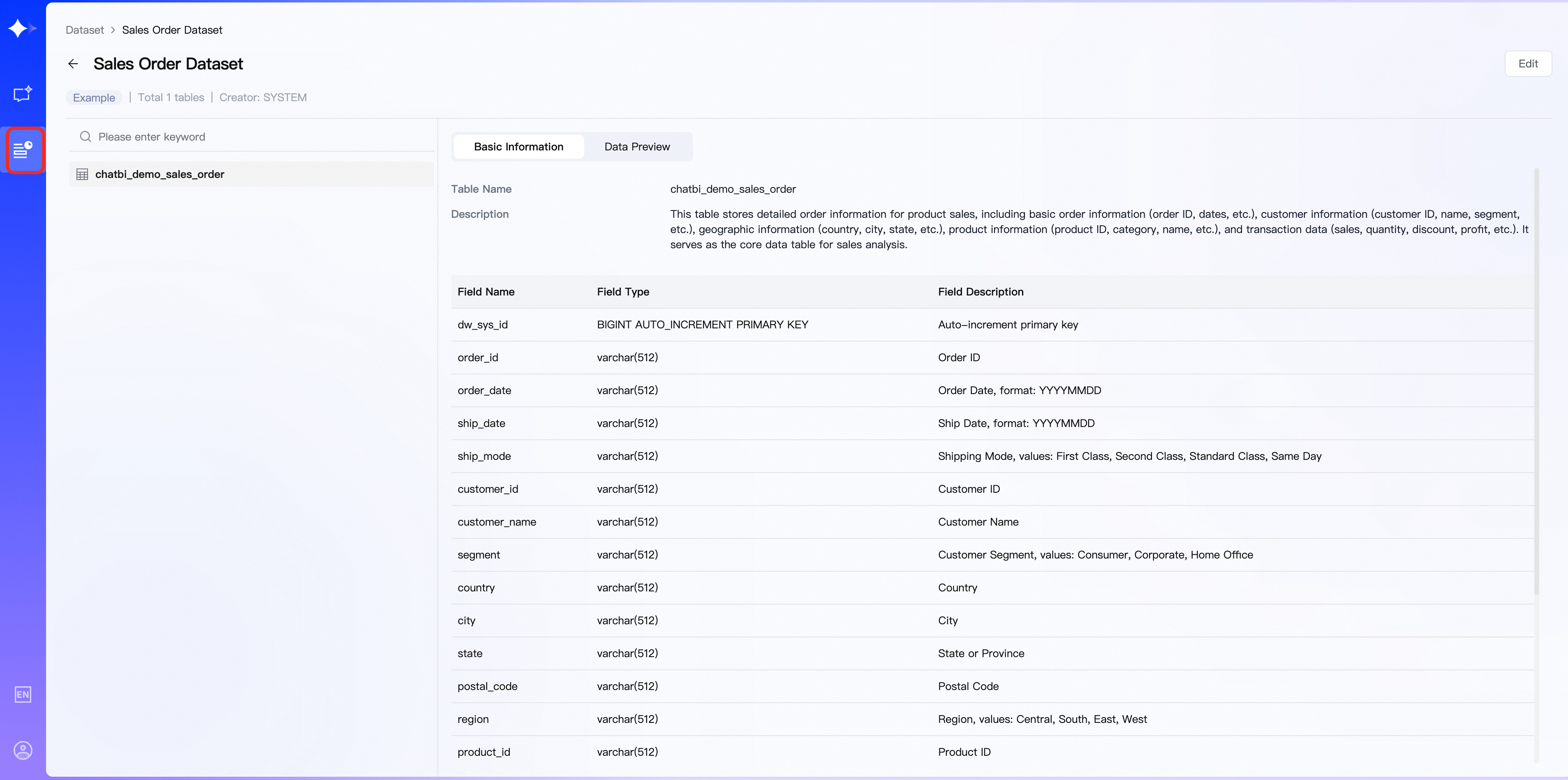
Edit dataset
-
Di panel navigasi sebelah kiri, klik Dataset untuk membuka halaman Datasets.
-
Temukan kartu dataset tujuan. Anda dapat menggunakan salah satu metode berikut untuk membuka halaman edit dataset.
-
Arahkan kursor ke kartu dataset tujuan, lalu di pojok kanan atas kartu, klik
 > Edit.
> Edit. -
Klik kartu dataset tujuan untuk membuka halaman detail dataset, lalu klik tombol Edit di pojok kanan atas.
-
-
Ubah konfigurasi dataset. Deskripsi parameternya sama seperti pada Buat dataset.
CatatanSaat mengedit konfigurasi dataset yang sudah ada, tipe dan tipe sumber data tidak dapat diubah.
-
Setelah menyelesaikan pengeditan dataset, klik Next untuk menuju langkah Data Insight. Proses data insight dijalankan ulang terhadap data dalam dataset.
Hapus dataset
-
Di panel navigasi sebelah kiri, klik Dataset untuk membuka halaman Datasets.
-
Arahkan kursor ke kartu dataset tujuan, lalu di pojok kanan atas kartu, klik
> Delete. Setelah dataset dihapus, sesi dan grafik terkait tidak dapat menampilkan data dengan benar.
Langkah berikutnya: Mulai sesi berdasarkan dataset
-
Anda dapat menggunakan salah satu metode berikut untuk memulai sesi berdasarkan dataset tertentu.
-
Di panel navigasi sebelah kiri, klik Dataset untuk membuka halaman Datasets. Arahkan kursor ke kartu dataset tujuan, lalu di pojok kanan atas kartu, klik
 untuk memulai sesi.
untuk memulai sesi. -
Di panel navigasi sebelah kiri, klik New Session untuk membuka jendela sesi ChatBI. Lalu, di jendela sesi, klik Select Dataset.

-
-
Pada halaman Chat, masukkan kebutuhan atau pertanyaan Anda untuk memulai analisis data. Untuk informasi lebih lanjut, lihat Sesi ChatBI.
Kiat mengajukan pertanyaan
Kualitas analisis ChatBI sangat bergantung pada cara Anda mengajukan pertanyaan. Menguasai kiat berikut membantu Anda memperoleh hasil analisis yang lebih tepat dan bernilai.
Tentukan tujuan analisis yang jelas
Pertanyaan analisis yang baik harus mencakup subjek analisis yang jelas, metrik pengukuran, dan dimensi analisis.
|
Pertanyaan terstruktur (direkomendasikan) |
Pertanyaan samar (hindari) |
|
Tren penjualan bulanan di wilayah Tiongkok Timur pada tahun 2025 |
Tunjukkan situasi penjualan |
|
Pengguna baru harian dan laju pertumbuhan year-over-year selama 7 hari terakhir |
Bagaimana pertumbuhan pengguna akhir-akhir ini? |
|
10 tingkat pengembalian tertinggi berdasarkan kategori produk dan distribusi alasan pengembalian |
Apakah banyak pengembalian? |
Gunakan rentang waktu dan kondisi filter secara bijak
Menentukan rentang waktu dan kondisi filter dalam pertanyaan Anda membantu ChatBI menghasilkan SQL yang lebih tepat dan menghindari pemindaian tabel penuh yang tidak perlu.
-
Tentukan rentang waktu: Misalnya, "Margin kotor berdasarkan lini produk pada Q4 2025" lebih tepat daripada "Margin kotor berdasarkan lini produk" dan mengurangi volume data yang dikueri.
-
Tentukan dimensi filter: Misalnya, "Distribusi nilai pesanan rata-rata untuk pelanggan VIP di Tiongkok Utara" lebih terarah daripada "Berapa nilai pesanan rata-rata".
-
Gunakan istilah bisnis: Saat mengajukan pertanyaan, gunakan nilai bidang aktual dalam tabel data atau istilah bisnis yang dikonfigurasi di basis pengetahuan. Misalnya, gunakan "status='Completed'" daripada "pesanan yang sudah selesai". Hal ini membantu ChatBI mencocokkan data secara akurat.
Pecah kebutuhan kompleks menjadi langkah-langkah
Untuk kebutuhan analisis kompleks, kami merekomendasikan agar Anda membaginya menjadi beberapa pertanyaan sederhana dan mengajukannya secara bertahap untuk analisis progresif.
-
Langkah 1: Ikhtisar umum: Pertama, ajukan pertanyaan ikhtisar untuk memahami tren keseluruhan. Misalnya, "Tren penjualan bulanan keseluruhan pada tahun 2025".
-
Langkah 2: Identifikasi anomali: Setelah menemukan anomali, ajukan pertanyaan mendalam yang terarah. Misalnya, "Alasan penurunan penjualan pada bulan Maret, dipecah berdasarkan kategori produk".
-
Langkah 3: Analisis akar penyebab: Lakukan analisis akar penyebab lebih lanjut terhadap temuan utama. Misalnya, "Pada kategori elektronik di bulan Maret, subkategori mana yang mengalami penurunan terbesar".
Kiat percakapan multi-turn
ChatBI mendukung beberapa pertanyaan berurutan dalam satu sesi yang sama. Kiat berikut membantu Anda melakukan analisis multi-turn lebih efisien.
-
Lanjutkan dengan pertanyaan lanjutan: Ajukan pertanyaan lanjutan berdasarkan hasil sebelumnya. Misalnya, pertama tanyakan "Peringkat penjualan berdasarkan wilayah", lalu tanyakan "Detail penjualan bulanan untuk wilayah dengan peringkat tertinggi".
-
Instruksi koreksi: Jika hasil analisis tidak sesuai ekspektasi, jelaskan secara jelas apa yang perlu disesuaikan pada giliran berikutnya. Misalnya, "Agregasikan analisis di atas berdasarkan kuartal, bukan bulan" atau "Kecualikan data uji dan tampilkan hanya pesanan resmi".
-
Ganti visualisasi: Untuk hasil data yang sama, Anda dapat meminta format tampilan berbeda. Misalnya, "Tampilkan data di atas sebagai grafik pie" atau "Urutkan secara menurun".
Menangani hasil yang tidak akurat
Saat hasil analisis ChatBI kurang akurat, Anda dapat mengoptimalkannya dari aspek berikut.
-
Periksa pencocokan tabel tujuan: Pada langkah "Identify destination table" dalam hasil analisis, pastikan apakah ChatBI memilih tabel data yang benar. Jika tabel yang salah dicocokkan, sebutkan secara eksplisit nama tabel dalam pertanyaan Anda, misalnya, "Analisis penjualan berdasarkan kategori menggunakan tabel ods_order_detail".
-
Perbaiki redaksi pertanyaan: Ajukan ulang pertanyaan menggunakan istilah bisnis yang lebih tepat dan definisi metrik yang jelas. Misalnya, ubah "Berapa banyak pengguna aktif" menjadi "Jumlah pengguna unik yang login dalam 30 hari terakhir".
-
Tingkatkan basis pengetahuan: Jika jenis pertanyaan tertentu secara konsisten tidak akurat, kami merekomendasikan agar administrator menambahkan templat pertanyaan, istilah, atau logika bisnis terkait di Basis pengetahuan. Setelah dikonfigurasi, ChatBI memprioritaskan pengetahuan dalam basis pengetahuan untuk memahami dan memproses pertanyaan tersebut.
-
Periksa SQL yang dihasilkan: Perluas kode SQL pada langkah "Generate execution plan" dan pastikan apakah logika kueri sudah benar. Jika terdapat masalah, salin SQL tersebut, modifikasi secara manual, lalu eksekusi. Kemudian tambahkan SQL yang benar sebagai templat pertanyaan ke basis pengetahuan.
Panduan konfigurasi sumber data
MySQL
-
Risiko pemindaian tabel penuh: SQL yang dihasilkan ChatBI berdasarkan pertanyaan Anda mungkin melakukan pemindaian tabel penuh. Jika tabel berisi data dalam jumlah besar (lebih dari jutaan baris), hal ini dapat memberi beban tinggi pada database. Kami sangat menyarankan menggunakan standby atau replika read-only sebagai sumber data dataset untuk menghindari dampak pada lingkungan produksi.
-
Optimasi indeks: Buat indeks pada kolom filter yang sering dikueri (seperti kolom waktu, status, dan kategori) untuk mempercepat eksekusi SQL yang dihasilkan ChatBI.
-
Penamaan kolom: Gunakan nama kolom berbahasa Inggris dengan makna bisnis yang jelas (seperti
order_amountdancustomer_name), dan tambahkan komentar kolom berbahasa Indonesia. ChatBI mengandalkan nama kolom dan komentar untuk memahami struktur tabel. Penamaan yang baik secara signifikan meningkatkan akurasi pencocokan tabel tujuan dan pembuatan SQL. -
Skenario penggunaan: Cocok untuk skenario kueri database bisnis dengan volume data hingga puluhan juta baris, seperti analisis pesanan dan manajemen pelanggan untuk analisis data bisnis online.
Hologres
-
Desain tabel partisi: Kami merekomendasikan penggunaan tabel partisi, dipartisi berdasarkan waktu (seperti tanggal atau bulan). Saat SQL yang dihasilkan ChatBI mengkueri tabel partisi, sistem dapat secara otomatis melakukan partition pruning, sehingga secara signifikan mengurangi volume data yang dipindai dan menghindari timeout kueri akibat rentang kueri yang terlalu luas.
-
Komentar tabel dan kolom: Hologres mendukung penambahan
COMMENTpada tabel dan kolom. ChatBI membaca komentar tersebut untuk memahami semantik data. Disarankan agar Anda menambahkan komentar berbahasa Mandarin pada setiap tabel dan kolom kunci guna menjelaskan makna bisnisnya. -
Penyimpanan hybrid baris-kolom: Untuk skenario kueri ChatBI yang fokus pada analisis agregasi, kami merekomendasikan penggunaan mode penyimpanan kolom untuk performa kueri yang lebih baik.
-
Skenario penggunaan: Cocok untuk skenario analisis data real-time dan near-real-time. Mendukung kueri interaktif pada ratusan juta catatan dan sangat sesuai untuk dasbor waktu nyata serta analisis metrik real-time.
MaxCompute
-
Partition pruning: MaxCompute adalah mesin pemrosesan data masif, dan satu kueri saja dapat memindai data dalam jumlah besar. Kami sangat menyarankan penggunaan tabel partisi dan memastikan dimensi filter yang umum digunakan (seperti tanggal dan wilayah) dijadikan kunci partisi. ChatBI menggunakan kondisi partisi saat menghasilkan SQL sebisa mungkin untuk mengurangi pemindaian tabel penuh yang tidak perlu.
-
Latensi kueri: MaxCompute adalah mesin pemrosesan batch offline, dan waktu respons kueri biasanya berkisar dari beberapa detik hingga menit, tergantung volume data dan kompleksitas kueri. Jika Anda memerlukan respons dalam hitungan detik, kami merekomendasikan penggunaan Hologres atau StarRocks.
-
Perbedaan dialek SQL: MaxCompute menggunakan dialek SQL sendiri, dan beberapa fungsi serta sintaks berbeda dari SQL standar. ChatBI telah diadaptasi ke sintaks SQL MaxCompute dan secara otomatis menghasilkan SQL yang sesuai spesifikasi MaxCompute. Jika SQL yang dihasilkan gagal dieksekusi, Anda dapat menambahkan templat pertanyaan di basis pengetahuan untuk mengarahkan sintaks SQL yang benar.
-
Skenario penggunaan: Cocok untuk analisis offline data masif pada skala TB hingga PB, seperti analisis tren data historis dan analisis perilaku pengguna menyeluruh.
StarRocks
-
Fitur arsitektur MPP: StarRocks menggunakan arsitektur massively parallel processing (MPP) dan unggul dalam analisis multidimensi serta kueri agregasi kompleks. Pertanyaan analisis silang multidimensi yang diajukan melalui ChatBI biasanya mencapai performa kueri yang baik di StarRocks.
-
Tampilan yang di-materialisasi: Jika kueri agregasi tertentu merupakan skenario frekuensi tinggi, kami merekomendasikan pembuatan materialized views di StarRocks untuk mempercepat kueri. ChatBI secara otomatis menggunakan materialized views untuk meningkatkan performa kueri.
-
Pemodelan data: StarRocks mendukung model Duplicate Key, Aggregate Key, Unique Key, dan Primary Key. Untuk skenario analisis ChatBI, model Duplicate Key cocok untuk analisis multidimensi fleksibel, sedangkan model Aggregate Key cocok untuk skenario kueri metrik tetap. Pilih model yang sesuai berdasarkan kebutuhan analisis aktual.
-
Skenario penggunaan: Cocok untuk analisis multidimensi real-time dan skenario kueri ad hoc. Mendukung respons kueri dalam hitungan detik pada ratusan juta catatan dan sangat sesuai untuk analisis perilaku pengguna, laporan real-time, dan skenario serupa.