Anda dapat menggunakan Kafka sebagai sumber untuk sinkronisasi waktu nyata tabel tunggal, menangkap data dari antrian pesan secara real-time dan menulisnya ke tujuan. Topik ini menjelaskan cara mengonfigurasi komponen input Kafka.
Cakupan
Mendukung Alibaba Cloud Kafka dan versi Kafka yang dikelola sendiri dari 0.10.2 hingga 2.2.x, inklusif.
Versi Kafka sebelum 0.10.2 tidak mendukung pengambilan offset data partisi, dan struktur datanya mungkin tidak mendukung timestamp. Akibatnya, statistik latensi untuk tugas sinkronisasi mungkin salah, dan Anda mungkin tidak dapat mengatur ulang offset konsumen dengan benar.
Untuk informasi lebih lanjut, lihat Konfigurasikan Sumber Data Kafka.
Prosedur
Buka halaman DataStudio.
Masuk ke Konsol DataWorks. Di bilah navigasi atas, pilih Wilayah yang diinginkan. Di panel navigasi sisi kiri, pilih . Pada halaman yang muncul, pilih ruang kerja yang diinginkan dari daftar drop-down dan klik Go to Data Development.
Di panel Alur Kerja Terjadwal halaman DataStudio, gerakkan pointer di atas ikon
 dan pilih .
dan pilih .Sebagai alternatif, temukan alur kerja yang diinginkan di panel Alur Kerja Terjadwal, klik kanan nama alur kerja, dan pilih .
Di kotak dialog Create Node, atur parameter Sync Method menjadi End-to-end ETL dan konfigurasikan parameter Name dan Path.
Klik Confirm.
Di halaman konfigurasi node sinkronisasi waktu nyata, klik dan seret ke panel pengeditan.
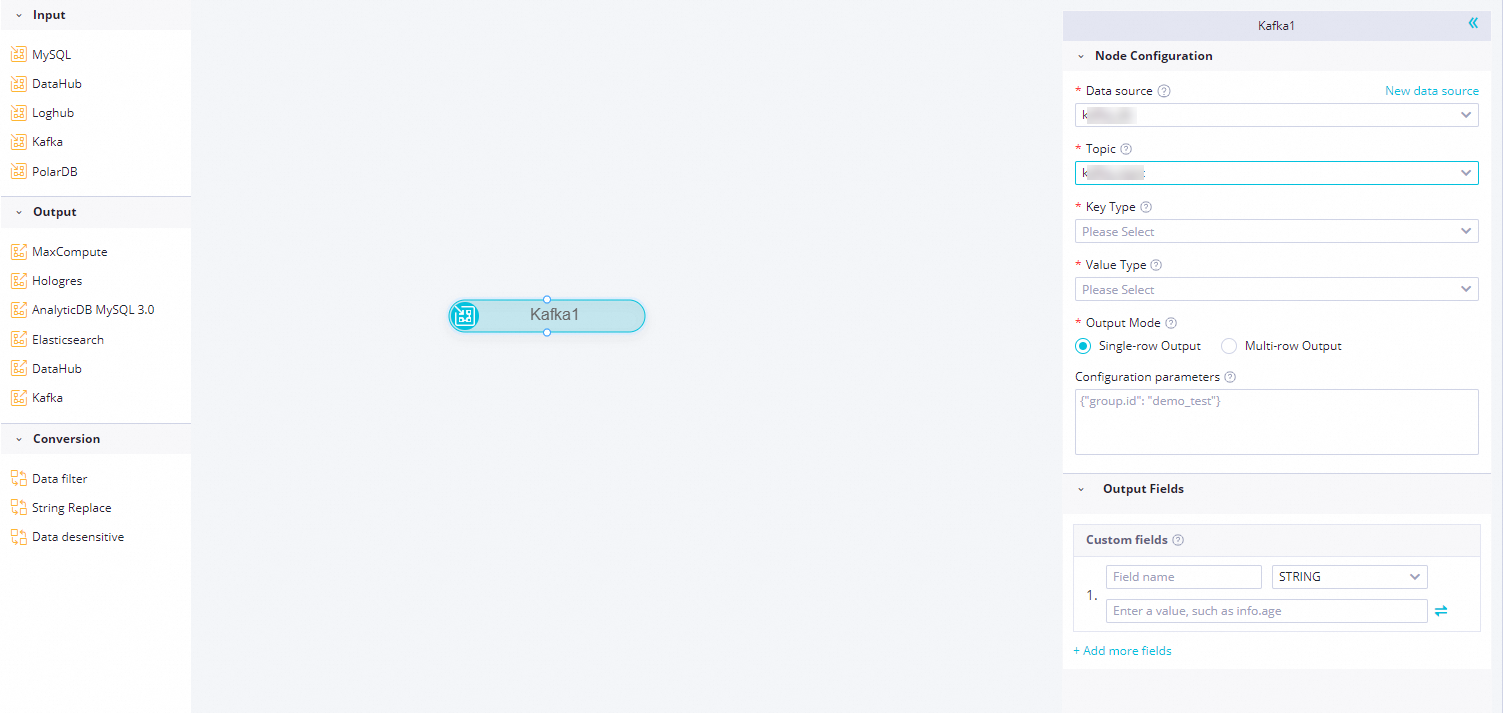
Klik node Kafka. Di kotak dialog Node Configuration, konfigurasikan parameter-parameter berikut.
Parameter
Deskripsi
Data Source
Pilih sumber data Kafka yang telah dikonfigurasi. Hanya sumber data Kafka yang didukung. Jika tidak ada sumber data yang tersedia, klik New Data Source di sebelah kanan untuk pergi ke halaman dan buat satu. Untuk informasi lebih lanjut, lihat Konfigurasikan Sumber Data Kafka.
Topic
Nama topik Kafka. Topik adalah kategori yang digunakan Kafka untuk mengorganisasi umpan pesan.
Setiap pesan yang dipublikasikan ke kluster Kafka termasuk dalam sebuah topik. Sebuah topik adalah kumpulan kelompok pesan.
CatatanInput Kafka hanya mendukung satu topik.
Key Type
Tipe kunci dalam pesan Kafka. Nilai ini menentukan konfigurasi key.deserializer saat Anda menginisialisasi KafkaConsumer. Nilai valid: STRING, BYTEARRAY, DOUBLE, FLOAT, INTEGER, LONG, dan SHORT.
Value Type
Tipe nilai dalam pesan Kafka. Nilai ini menentukan konfigurasi value.deserializer saat Anda menginisialisasi KafkaConsumer. Nilai valid: STRING, BYTEARRAY, DOUBLE, FLOAT, INTEGER, LONG, dan SHORT.
Output Mode
Metode yang digunakan untuk mengurai catatan Kafka.
Output baris tunggal: Mengurai catatan Kafka sebagai string tanpa struktur atau objek JSON. Satu catatan Kafka diurai menjadi satu catatan output.
Output multi-baris: Mengurai catatan Kafka sebagai array JSON. Setiap elemen array diurai menjadi satu catatan output. Oleh karena itu, satu catatan Kafka dapat diurai menjadi beberapa catatan output.
CatatanItem konfigurasi ini hanya didukung di beberapa wilayah. Jika Anda tidak melihat item ini, tunggu fitur ini dirilis di wilayah Anda.
Path Of Array
Saat Mode Output diatur ke Output multi-baris, tentukan path array JSON dalam nilai catatan Kafka. Path mendukung referensi ke bidang dalam objek JSON tertentu dalam format
a.a1atau bidang dalam array JSON tertentu dalam formata[0].a1. Jika Anda membiarkan item konfigurasi ini kosong, seluruh nilai catatan Kafka diurai sebagai array JSON.Perhatikan bahwa array JSON target yang akan diurai harus berupa array objek, seperti
[{"a":"hello"},{"b":"world"}], bukan array numerik atau string, seperti["a","b"].Configuration Parameters
Saat Anda membuat klien konsumsi data Kafka (KafkaConsumer), Anda dapat mengonfigurasi parameter ekstensi
kafkaConfiguntuk kontrol detail halus atas perilaku pembacaan datanya. Untuk daftar lengkap parameter yang didukung oleh versi kluster Kafka yang berbeda, lihat dokumentasi resmi Kafka untuk versi Anda.Contoh parameter umum:
bootstrap.serversauto.commit.interval.mssession.timeout.ms
group.idPerilaku default
Secara default, tugas sinkronisasi waktu nyata menetapkan string yang dibuat secara acak sebagaigroup.iduntuk KafkaConsumer.Konfigurasi manual
Anda dapat secara manual menentukangroup.idtetap. Ini memungkinkan Anda memantau atau mengamati offset konsumen tugas sinkronisasi di kluster Kafka menggunakan kelompok konsumen yang ditentukan.
Output Fields
Kustomisasi nama bidang output untuk data Kafka:
Klik Add More Fields, masukkan Field Name, dan pilih Type untuk menambahkan bidang kustom.
Value Method menentukan cara mendapatkan nilai bidang dari catatan Kafka. Klik ikon
 di sebelah kanan untuk beralih antara dua metode nilai.
di sebelah kanan untuk beralih antara dua metode nilai.Metode nilai preset: Menyediakan enam opsi preset untuk mendapatkan nilai dari catatan Kafka:
value: isi pesan
key: kunci pesan
partition: nomor partisi
offset: Offset pesan
timestamp: timestamp pesan dalam milidetik
headers: header pesan
Penguraian JSON: Anda dapat menggunakan sintaksis . (untuk mendapatkan subbidang) dan [] (untuk mendapatkan elemen array) untuk mendapatkan konten dari format JSON kompleks. Untuk kompatibilitas mundur, Anda juga dapat menggunakan string yang dimulai dengan dua garis bawah (_), seperti __value__, untuk mendapatkan konten spesifik dari catatan Kafka sebagai nilai bidang. Kode berikut menunjukkan data Kafka contoh.
{ "a": { "a1": "hello" }, "b": "world", "c":[ "xxxxxxx", "yyyyyyy" ], "d":[ { "AA":"this", "BB":"is_data" }, { "AA":"that", "BB":"is_also_data" } ] }Nilai untuk bidang output bervariasi berdasarkan situasi:
Untuk menyinkronkan nilai catatan Kafka, atur metode nilai menjadi __value__.
Untuk menyinkronkan kunci catatan Kafka, atur metode nilai menjadi __key__.
Untuk menyinkronkan partisi catatan Kafka, atur metode nilai menjadi __partition__.
Untuk menyinkronkan Offset catatan Kafka, atur metode nilai menjadi __offset__.
Untuk menyinkronkan timestamp catatan Kafka, atur metode nilai menjadi __timestamp__.
Untuk menyinkronkan header catatan Kafka, atur metode nilai menjadi __headers__.
Untuk menyinkronkan data "hello" dari bidang a1, atur metode nilai menjadi a.a1.
Untuk menyinkronkan data "world dari bidang b, atur metode nilai menjadi b.
Untuk menyinkronkan data "yyyyyyy" dari bidang c, atur metode nilai menjadi c[1].
Untuk menyinkronkan data "this" dari bidang AA, atur metode nilai menjadi d[0].AA.
Gerakkan pointer di atas bidang yang ingin Anda hapus dan klik ikon
 .
.
Contoh skenario: Jika Anda mengatur Output Mode ke Multi-row Output, sistem pertama-tama mengurai array JSON berdasarkan path JSON yang ditentukan di Path of array. Kemudian, ia mengambil setiap objek JSON dari array dan membentuk bidang output berdasarkan nama bidang dan metode nilai yang didefinisikan. Definisi metode nilai sama seperti pada mode output baris tunggal. Anda dapat menggunakan sintaksis . (untuk mendapatkan subbidang) dan [] (untuk mendapatkan elemen array) untuk mendapatkan konten dari format JSON kompleks. Kode berikut menunjukkan data contoh instans Kafka:
{ "c": { "c0": [ { "AA": "this", "BB": "is_data" }, { "AA": "that", "BB": "is_also_data" } ] } }Jika Anda mengatur Path of array menjadi
c.c0dan mendefinisikan dua bidang output, satu bernamaAAdengan metode nilaiAAdan lainnya bernamaBBdengan metode nilaiBB, catatan Kafka ini diurai menjadi dua catatan berikut:
Klik ikon
 di bilah alat.Catatan
di bilah alat.CatatanInput Kafka hanya mendukung satu topik.