Parameter penjadwalan dapat digunakan di setiap tahap konfigurasi node sinkronisasi data. Topik ini menjelaskan skenario penggunaan umum parameter penjadwalan.
Informasi latar belakang
| Skema | Deskripsi | Referensi |
| Sinkronkan data inkremental | DataWorks memungkinkan Anda mengonfigurasi parameter penjadwalan untuk jenis Reader Plugin tertentu guna menyinkronkan hanya data tambahan yang dihasilkan dalam periode waktu tertentu ke tujuan. DataWorks juga memungkinkan Anda menggunakan fitur pengisian ulang data yang disediakan di Operation Center untuk menyinkronkan data dalam periode waktu tertentu ke partisi tertentu di tabel tujuan. Sebagai contoh, Anda dapat mengonfigurasi parameter penjadwalan untuk MySQL, LogHub, atau Kafka Reader dalam skenario ini. | Skenario 1: Sinkronkan data inkremental dan Skenario 4: Sinkronkan data historis |
| Sinkronkan data dari tabel atau file dengan nama tabel dinamis atau nama file | Saat mengonfigurasi jenis Reader Plugin tertentu, Anda dapat menggunakan parameter penjadwalan untuk menentukan format nama tabel atau file dari mana Anda ingin menyinkronkan data. Dengan cara ini, node sinkronisasi data terkait dapat menyinkronkan data dari tabel atau file dengan nama tabel dinamis atau nama file setiap kali node tersebut dijalankan. Sebagai contoh, Anda dapat mengonfigurasi parameter penjadwalan untuk Object Storage Service (OSS), FTP, atau MySQL Reader dalam skenario ini. Untuk jenis Reader Plugin tertentu, Anda mungkin perlu menggunakan editor kode untuk mengonfigurasi parameter penjadwalan. | Skenario 2: Sinkronkan data dari tabel atau file dengan nama tabel dinamis atau nama file |
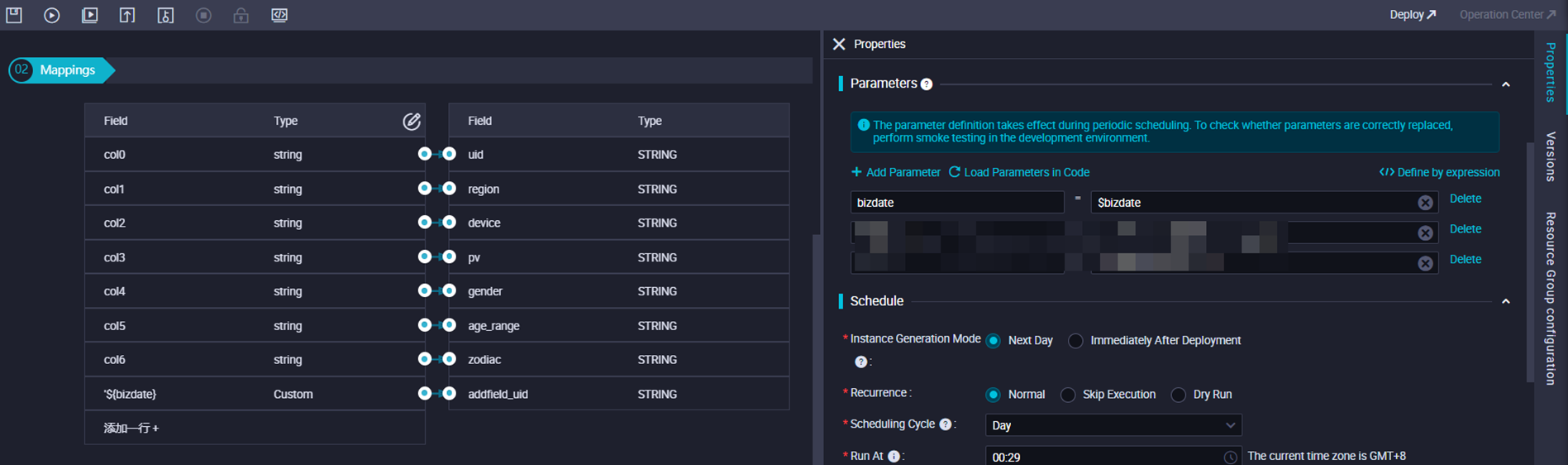
| Tetapkan konstanta atau variabel terkait waktu ke bidang dalam tabel tujuan | Saat mengonfigurasi pemetaan antara bidang dalam tabel sumber dan bidang dalam tabel tujuan, Anda dapat menetapkan konstanta yang diperoleh berdasarkan cap waktu data dari node sinkronisasi data ke bidang dalam tabel tujuan. Kemudian, sistem secara dinamis menetapkan nilai ke bidang tersebut setiap hari berdasarkan parameter penjadwalan yang dikonfigurasi. Dukungan untuk operasi ini bervariasi berdasarkan tipe sumber data. | Skenario 3: Tentukan bidang tujuan |
Perhatian
- Lakukan pengujian asap pada node SQL tempat parameter penjadwalan digunakan. Jika node SQL lolos pengujian asap, gunakan parameter penjadwalan untuk node tersebut. Untuk informasi lebih lanjut tentang pengujian asap pada node SQL untuk memeriksa apakah parameter penjadwalan yang digunakan untuk node bekerja seperti yang diharapkan, lihat Konfigurasikan dan gunakan parameter penjadwalan.
- Komit node ke Operation Center dalam lingkungan pengembangan.
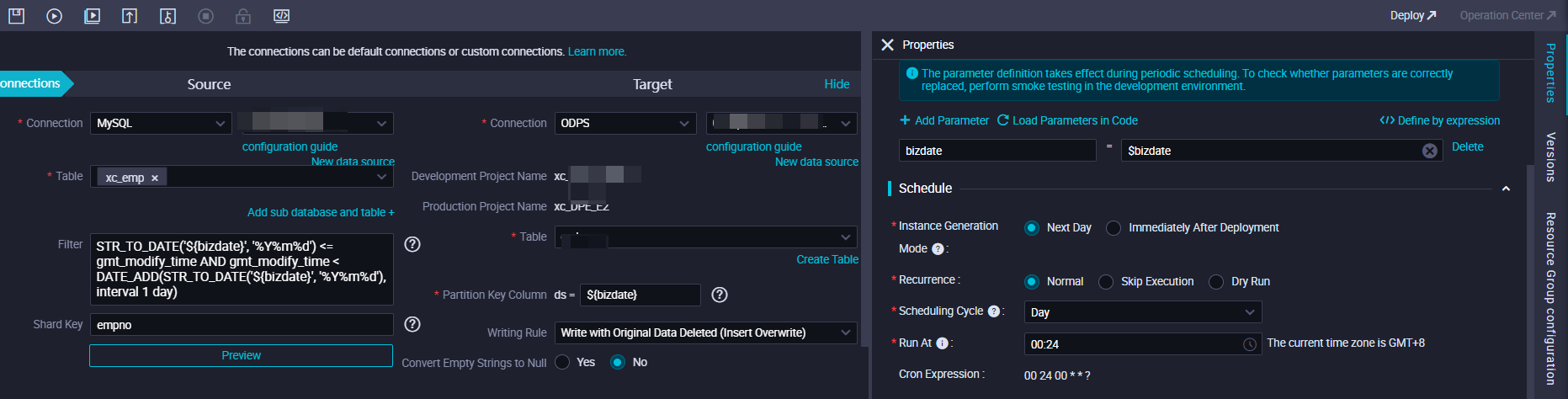
Skenario 1: Sinkronkan data inkremental
- Contoh 1: Sinkronkan data inkremental dari LogHub ke partisi T-1 tabel MaxCompute dengan interval 10 menit.
Sistem menghasilkan instance penjadwalan untuk node sinkronisasi data setiap 10 menit berdasarkan waktu penjadwalan node. Partisi dalam tabel MaxCompute ke mana data ditulis ditentukan oleh parameter penjadwalan. $bizdate menentukan cap waktu data dari node sinkronisasi data. Saat node sinkronisasi data dijalankan, ekspresi filter partisi yang dikonfigurasikan untuk node tersebut diganti dengan nilai aktual berdasarkan cap waktu data yang ditentukan oleh parameter penjadwalan. Untuk informasi lebih lanjut tentang cara menggunakan parameter penjadwalan, lihat Konfigurasikan dan gunakan parameter penjadwalan.
Catatan Rentang waktu adalah interval tertutup kiri, terbuka kanan.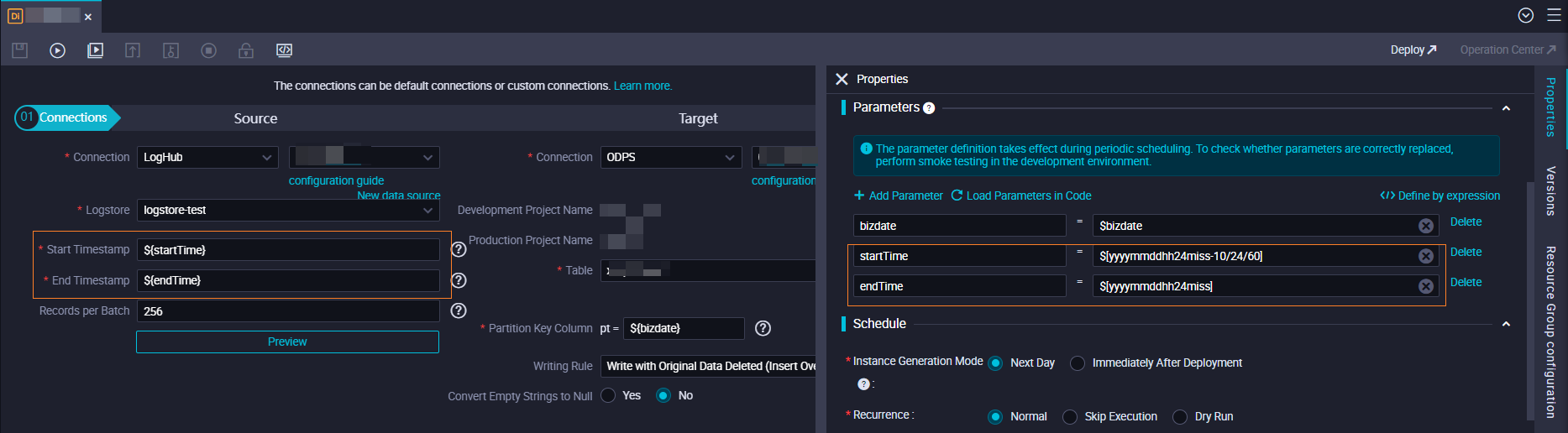
- Contoh 2: Sinkronkan data yang dihasilkan pada hari sebelumnya dari LogHub ke partisi T-1 tabel MaxCompute pada pukul 00:00 setiap hari. Catatan Rentang waktu adalah interval tertutup kiri, terbuka kanan.
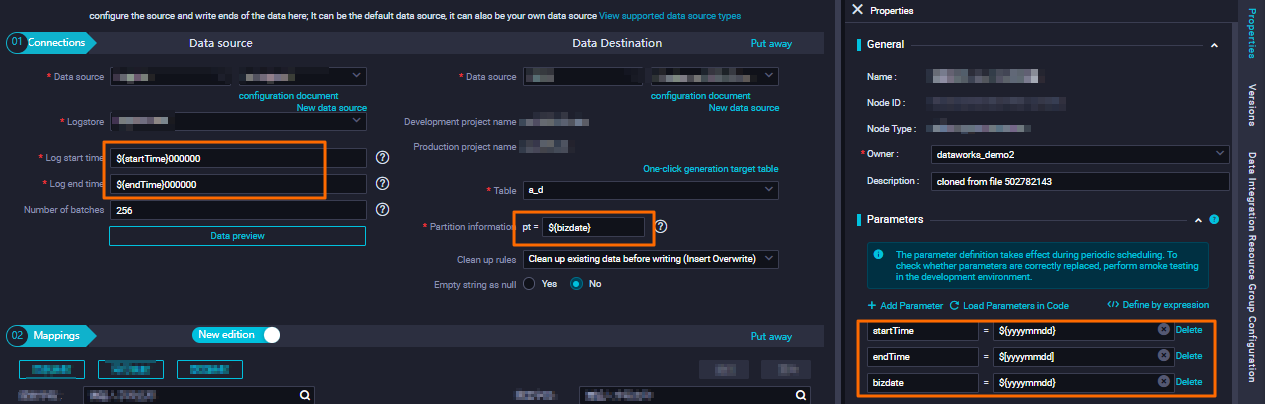
Skenario 2: Sinkronkan data dari tabel atau file dengan nama tabel dinamis atau nama file
- Contoh 1: Sinkronkan data dari file dengan nama file dinamis.
Saat mengonfigurasi node sinkronisasi data untuk menyinkronkan data dari OSS ke MaxCompute, Anda dapat menggunakan parameter penjadwalan untuk menentukan nama objek sumber yang namanya diakhiri dengan tanggal. Dengan cara ini, data dapat disinkronkan dari objek terkait ke partisi terkait dalam tabel MaxCompute setiap hari.
Catatan Jika Anda ingin menggunakan node sinkronisasi data untuk menyinkronkan data dari tabel atau file dengan nama tabel dinamis atau nama file, Anda mungkin perlu mengonfigurasi node tersebut menggunakan editor kode. Jika Anda menggunakan variabel dalam konfigurasi node sinkronisasi data, pratinjau data tidak didukung.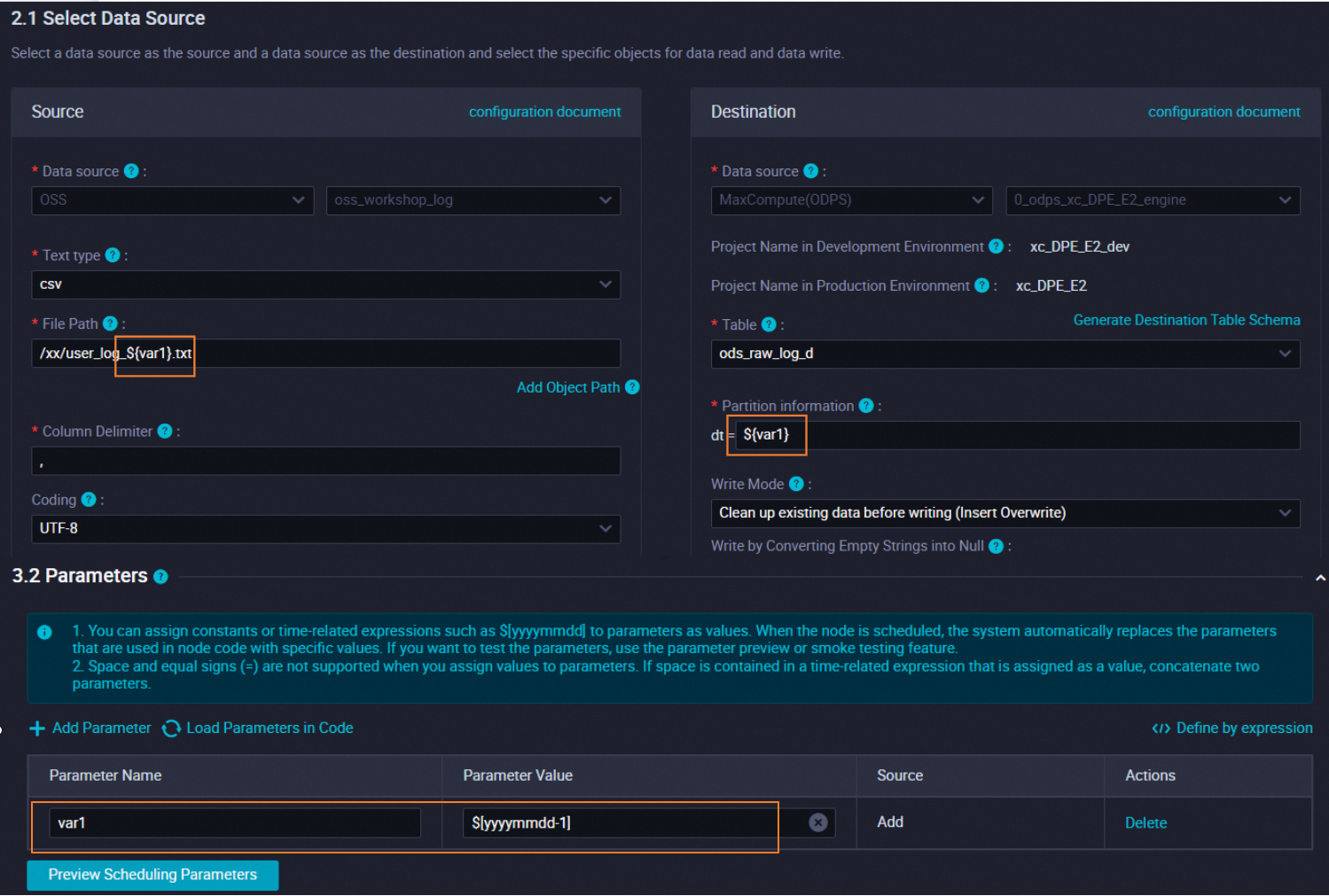
- Contoh 2: Sinkronkan data dari tabel dengan nama tabel dinamis. Saat mengonfigurasi node sinkronisasi data untuk menyinkronkan data dari MySQL ke MaxCompute, Anda dapat menggunakan parameter penjadwalan untuk menentukan tabel sumber yang diberi nama berdasarkan waktu. Dengan cara ini, data dapat disinkronkan dari tabel terkait ke partisi terkait dalam tabel MaxCompute setiap hari. Gambar berikut menunjukkan konfigurasi di editor kode dan UI tanpa kode.
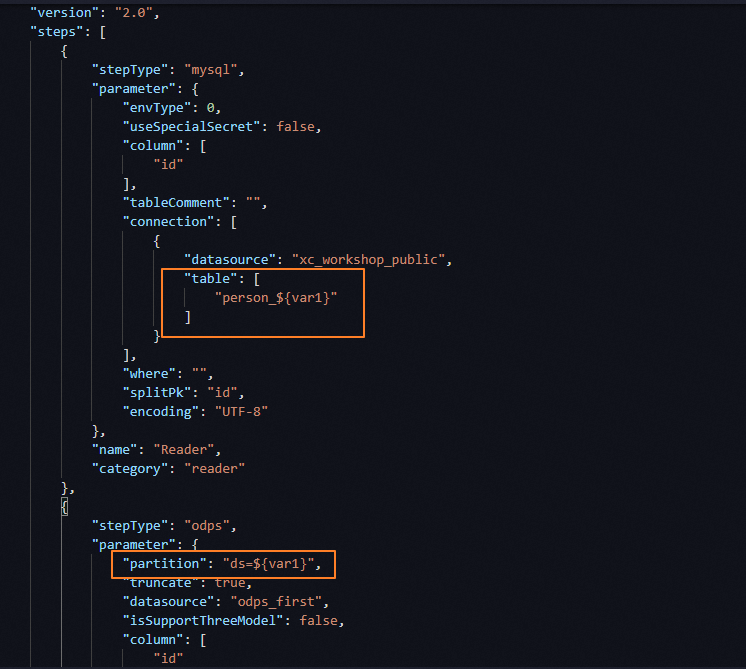
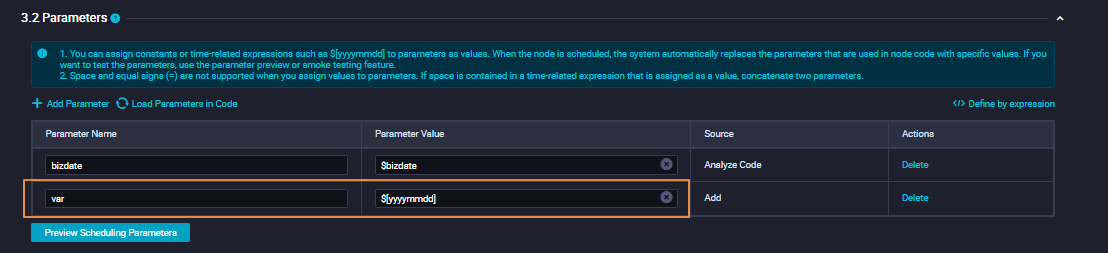
Skenario 3: Tentukan bidang tujuan
Skenario 4: Sinkronkan data historis
Parameter penjadwalan secara otomatis diganti dengan nilai spesifik berdasarkan cap waktu data dari node dan format nilai parameter penjadwalan. Ini memungkinkan konfigurasi parameter dinamis untuk penjadwalan node. Jika Anda ingin mengisi ulang data pada hari Anda membuat node, Anda dapat menggunakan fitur pengisian ulang data untuk menghasilkan data historis untuk rentang waktu tertentu. Dalam hal ini, parameter penjadwalan secara otomatis diganti dengan nilai spesifik berdasarkan cap waktu data dari operasi pengisian ulang data. Untuk informasi lebih lanjut tentang pengisian ulang data, lihat Isi ulang data dan lihat instance pengisian ulang data (versi baru).