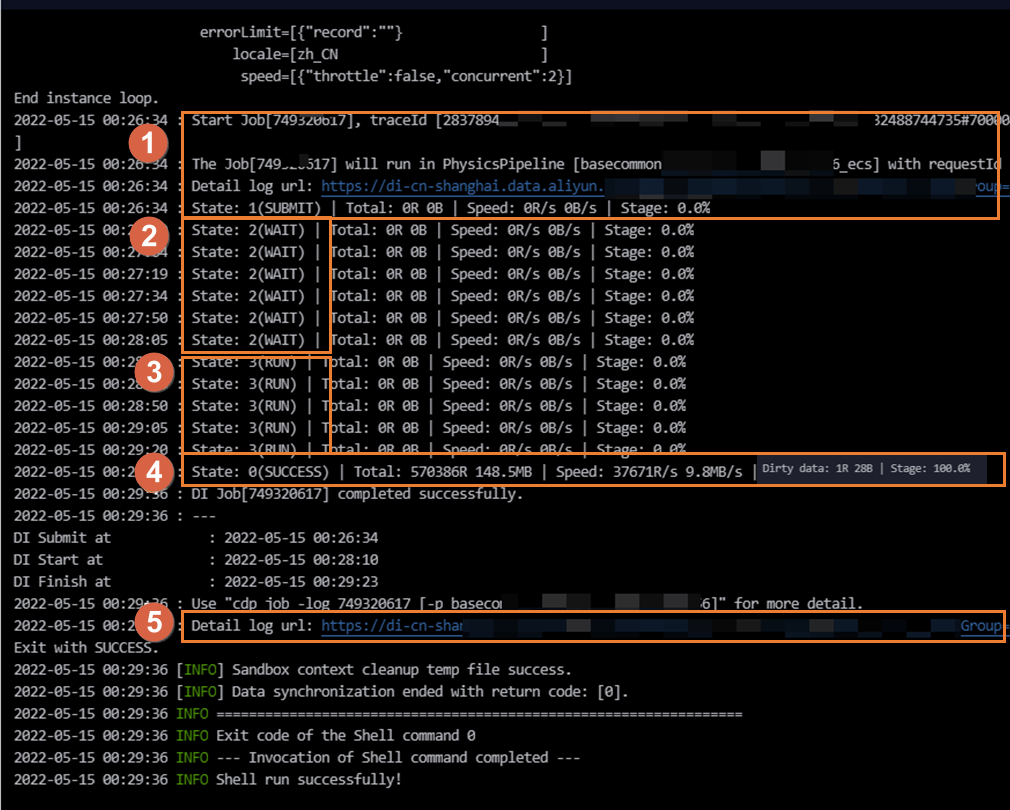
Area | Parameter | Deskripsi |
Pengiriman Instans (Area ①) | SUBMIT: Status `SUBMIT` menunjukkan bahwa tugas sinkronisasi telah dikirim dari Sistem pemetaan CDN ke kelompok sumber daya untuk eksekusi tugas Integrasi Data. Ini berarti rendering tugas sinkronisasi telah selesai. | Sistem pemetaan CDN mengirimkan tugas ke kelompok sumber daya untuk dieksekusi. Anda dapat melihat kelompok sumber daya Integrasi Data yang digunakan oleh tugas saat ini di Area ①. Output log berbeda tergantung pada jenis kelompok sumber daya: Jika tugas berjalan pada kelompok sumber daya default, log berisi informasi berikut. running in Pipeline[basecommon_ group_xxxxxxxxx]
Jika tugas berjalan pada kelompok sumber daya eksklusif untuk Integrasi Data, log berisi informasi berikut. running in Pipeline[basecommon_S_res_group_xxx]
Jika tugas berjalan pada kelompok sumber daya arsitektur tanpa server, log berisi informasi berikut. running in Pipeline[basecommon_Serverless_res_group_xxx]
Catatan Anda juga dapat mengklik Detail log url di area ini untuk melihat log terperinci setiap tahap. |
Permintaan Sumber Daya (Area ②) | WAIT: Status `WAIT` menunjukkan bahwa tugas sinkronisasi sedang menunggu sumber daya untuk eksekusi tugas Integrasi Data. | Jika sebuah tugas menunggu lama untuk sumber daya Integrasi Data, tugas lain mungkin sedang menggunakan sumber daya pada kelompok sumber daya tersebut. Ini berarti tidak ada sumber daya yang tersedia untuk tugas saat ini. Untuk menyelesaikan masalah ini, gunakan salah satu solusi berikut: Tunggu hingga tugas yang menggunakan kelompok sumber daya Integrasi Data selesai dan melepaskan sumber dayanya. Lalu, jalankan tugas Anda lagi. Untuk mengidentifikasi tugas yang menggunakan sumber daya, lihat Skenario dan Solusi untuk Sinkronisasi Data yang Lambat. Temukan daftar tugas yang menggunakan sumber daya dan identifikasi pemiliknya. Koordinasikan dengan pemilik untuk mengurangi konkurensi tugas. Kurangi konkurensi tugas sinkronisasi saat ini. Lalu, kirimkan dan publikasikan tugas lagi. Perluas kelompok sumber daya untuk eksekusi tugas. Untuk informasi lebih lanjut, lihat Operasi Skala-Masuk dan Skala-Keluar.
|
Mulai Sinkronisasi (Area ③) | RUN: Status `RUN` menunjukkan bahwa tugas sinkronisasi sedang berjalan. | Tugas sinkronisasi batch berjalan dalam empat tahap: Prapenyiapan Sistem mengirimkan pernyataan SQL pra-eksekusi ke database untuk dieksekusi berdasarkan konfigurasi Anda. Tidak semua tugas memiliki tahap prapenyiapan. Untuk MySQL Writer, jika Anda mengonfigurasikan pernyataan PreSQL untuk tugas, pernyataan SQL dikirim ke database dan dieksekusi pada tahap ini. Untuk MySQL Reader, jika Anda mengonfigurasikan pernyataan querySql atau klausa filter data (where), pernyataan SQL ini dikirim ke database dan dieksekusi pada tahap ini. Sebagai contoh, ketika Anda menulis data ke MaxCompute, tugas dapat dikonfigurasikan untuk Delete Existing Data Before Writing.
Catatan Gunakan bidang indeks untuk kondisi filter. Ini membantu mencegah pernyataan SQL membutuhkan waktu terlalu lama untuk dieksekusi di database. Waktu eksekusi yang lama dapat meningkatkan waktu sinkronisasi keseluruhan atau menyebabkan tugas sinkronisasi habis waktu dan gagal. Pemisahan (shard) Tugas Pada tahap ini, data sumber dipisahkan menjadi beberapa subtugas untuk pembacaan batch bersamaan. Aturan pemisahan adalah sebagai berikut: Database relasional: Data dipisahkan menjadi beberapa subtugas berdasarkan splitPk (kunci shard) yang Anda tentukan di antarmuka. Subtugas kemudian dibaca secara bersamaan dalam batch. Jika Anda tidak menetapkan kunci shard, data disinkronkan menggunakan thread konkuren tunggal. LogHub, DataHub, atau MongoDB: Data dipisahkan berdasarkan jumlah shards. Konkurensi maksimum tugas tidak dapat melebihi jumlah shards. Penyimpanan semi-terstruktur: Data dipisahkan berdasarkan jumlah file atau volume data. Sebagai contoh, untuk tugas OSS, konkurensi maksimum tidak dapat melebihi jumlah file.
Sinkronisasi data. Pada tahap ini, subtugas disinkronkan dalam batch berdasarkan konkurensi yang Anda konfigurasikan. Untuk database relasional, beberapa pernyataan SQL pengambilan data dibuat berdasarkan kunci shard. Pernyataan ini digunakan untuk mengambil data dari database secara terpisah. Untuk informasi lebih lanjut, lihat Hubungan antara Konkurensi Sinkronisasi Batch dan Pembatasan Laju.
Catatan Konkurensi aktual selama eksekusi mungkin tidak sama dengan konkurensi yang Anda tetapkan. Pernyataan SQL pengambilan data yang dihasilkan dari kunci shard dapat menyebabkan masalah jika kunci shard tidak ditetapkan dengan benar. Pernyataan SQL mungkin berjalan lama di database, yang meningkatkan waktu sinkronisasi keseluruhan. Mereka juga bisa habis waktu dan menyebabkan tugas sinkronisasi gagal. Jika beban database tinggi, eksekusi tugas juga bisa melambat.
Pasca-penyiapan Sistem mengirimkan pernyataan SQL pasca-eksekusi ke database untuk dieksekusi berdasarkan konfigurasi Anda. Tidak semua tugas memiliki tahap pasca-penyiapan: Untuk MySQL Writer, jika Anda mengonfigurasikan pernyataan PostSQL untuk tugas, pernyataan SQL dikirim ke database dan dieksekusi pada tahap ini setelah sinkronisasi data selesai. Waktu eksekusi pernyataan PostSQL di database juga memengaruhi total waktu eksekusi tugas sinkronisasi.
|
Eksekusi Selesai (Area ④) | Status penyelesaian tugas dapat berupa salah satu dari berikut: | Jika tugas gagal, pesan kesalahan utama dicatat dalam log. Anda dapat mengklik tautan di Area ⑤ untuk melihat proses eksekusi terperinci setiap tahap. Jika tugas berhasil, informasi seperti jumlah total catatan data yang disinkronkan dan kecepatan sinkronisasi rata-rata dicatat dalam log.
Catatan Jika data kotor dihasilkan selama sinkronisasi, log menunjukkan Dirty data: xxR. Data kotor tidak ditulis ke tujuan. Jika sejumlah besar data kotor dihasilkan, ini memengaruhi kecepatan sinkronisasi data. Jika Anda memiliki persyaratan untuk kecepatan sinkronisasi, Anda harus terlebih dahulu menyelesaikan masalah data kotor. Untuk informasi lebih lanjut tentang data kotor, lihat Fitur Konfigurasi Tugas Sinkronisasi Batch. Anda dapat mengontrol apakah data kotor memengaruhi eksekusi tugas normal dengan mengonfigurasi jumlah toleransi data kotor. Secara default, tugas sinkronisasi batch dikonfigurasikan untuk mentolerir data kotor. Anda dapat mengubah pengaturan ini di antarmuka konfigurasi tugas. Untuk informasi tentang cara mengonfigurasi tugas di Antarmuka tanpa kode, lihat Konfigurasikan Tugas di Antarmuka tanpa Kode. Untuk informasi tentang cara mengonfigurasi tugas di editor kode, lihat Konfigurasikan Tugas di Editor Kode.
|
Tautan Log Terperinci (Area ⑤) | Menyediakan tautan ke log terperinci. | Klik tautan log terperinci untuk melihat log terperinci setiap tahap proses eksekusi. |