Fitur Auto Scaling dari Database Autonomy Service (DAS) memantau performa waktu nyata instance database. Berdasarkan data tersebut, DAS mendeteksi pengecualian lalu lintas dan merekomendasikan spesifikasi serta disk yang sesuai, memungkinkan layanan database menyesuaikan sumber daya penyimpanan dan komputasi secara otomatis.
Informasi latar belakang
Staf O&M database sering menghadapi tantangan dalam memilih spesifikasi database yang tepat, termasuk CPU dan memori untuk aplikasi bisnis. Spesifikasi terlalu tinggi menyebabkan pemborosan sumber daya, sedangkan spesifikasi terlalu rendah mengakibatkan kekurangan komputasi dan memengaruhi bisnis.
Umumnya, staf O&M menggunakan spesifikasi yang memenuhi persyaratan CPU untuk lalu lintas stabil. Sebagai contoh, mereka mungkin memilih spesifikasi 4 inti CPU dan 8 GB memori untuk menjaga utilisasi CPU di bawah 50%. Selain itu, spesifikasi disk relatif tinggi, seperti 200 GB, digunakan untuk memastikan stabilitas operasi bisnis.
Namun, lonjakan lalu lintas sering kali menghabiskan sumber daya database, terjadi dalam berbagai skenario:
Saat layanan baru dirilis, jumlah lalu lintas aktual melebihi perkiraan, menyebabkan sumber daya habis. Contohnya, sejumlah besar lalu lintas dialihkan ke aplikasi baru atau fitur baru dirilis pada platform dengan lalu lintas tinggi.
Lonjakan lalu lintas tak terduga dapat dipicu oleh acara tertentu, selebriti, atau tren mode yang tiba-tiba memicu belanja besar-besaran.
Beberapa skenario melibatkan akses jarang tetapi terpusat, seperti absensi harian atau tugas akuntansi mingguan. Tekanan bisnis rendah sebagian besar waktu, sehingga staf O&M cenderung tidak mengalokasikan spesifikasi tinggi meskipun jam puncak diketahui.
Kekurangan sumber daya komputasi yang tiba-tiba sering kali tidak diantisipasi, berdampak serius pada bisnis. Salah satu tantangan utama bagi staf O&M adalah bagaimana menangani kekurangan sumber daya ini.
Sumber daya komputasi atau penyimpanan database dapat habis:
Ketika sumber daya komputasi habis, utilisasi CPU mencapai 100%, dan kemampuan komputasi tidak dapat memenuhi persyaratan bisnis.
Ketika sumber daya penyimpanan habis, penggunaan ruang disk mencapai 100%, dan jumlah data yang ditulis ke database mencapai batas atas spesifikasi saat ini, sehingga data baru tidak dapat ditulis ke sistem bisnis.
Untuk menyelesaikan masalah ini, DAS menyediakan layanan inovatif agar layanan database dapat menyesuaikan sumber daya penyimpanan dan komputasi secara otomatis.
Tema ini menjelaskan tantangan teknis, solusi, dan teknologi inti DAS Auto Scaling.
Tantangan teknis
Mengubah spesifikasi sumber daya komputasi dapat meningkatkan kinerja database. Namun, perubahan spesifikasi di lingkungan produksi melibatkan beberapa operasi, seperti migrasi data, pergantian high-availability (HA), dan pergantian proxy, yang dapat berdampak signifikan pada bisnis.
Dalam banyak kasus, lonjakan lalu lintas bisnis menyebabkan kekurangan sumber daya komputasi, bahkan hingga utilisasi CPU mencapai 100%.
Apakah peningkatan kapasitas dapat menyelesaikan masalah kekurangan sumber daya?
Utilisasi CPU 100% hanya salah satu gejala kekurangan sumber daya komputasi. Gejala ini dapat disebabkan oleh berbagai faktor dasar, dan masalah dapat diselesaikan dengan solusi berbeda:
Contohnya, lonjakan lalu lintas bisnis menyebabkan sumber daya saat ini tidak mencukupi. Dalam hal ini, auto scaling pada titik waktu yang tepat dapat dilakukan untuk peningkatan kapasitas.
Sebaliknya, sejumlah besar pernyataan SQL lambat menyebabkan antrian tugas tersumbat dan mengonsumsi banyak sumber daya. Dalam hal ini, respons pertama administrator database senior (DBA) adalah menerapkan pembatasan SQL sebagai solusi darurat alih-alih peningkatan kapasitas.
Saat sistem mendeteksi bahwa sumber daya instance tidak cukup, DAS harus mengidentifikasi penyebab dasar dari masalah kompleks tersebut dan membuat keputusan berdasarkan informasi dari penyebab dasar, seperti pembatasan dan peningkatan kapasitas.
Kapan peningkatan kapasitas dilakukan?
Menentukan titik waktu dan metode yang tepat untuk peningkatan kapasitas:
Akurasi keputusan pada titik waktu untuk peningkatan kapasitas sangat erat kaitannya dengan evaluasi keadaan darurat. Jika peringatan darurat dilaporkan terlalu sering, instance sering diperluas ke spesifikasi tinggi, menyebabkan biaya tidak perlu. Namun, jika peringatan dilaporkan lebih lambat, dampak keadaan darurat pada bisnis berlangsung lebih lama, bahkan dapat menyebabkan kegagalan bisnis. Dalam pemantauan waktu nyata, memprediksi apakah kesalahan akan bertahan pada waktu berikutnya menjadi tantangan.
Dalam banyak kasus, dua metode dapat digunakan untuk meningkatkan kapasitas: scale-out dan scale-up. Scale-out melibatkan penambahan node baca untuk penskalaan horizontal, sedangkan scale-up melibatkan peningkatan spesifikasi instance untuk penskalaan vertikal.
Scale-out cocok untuk skenario dengan jumlah lalu lintas baca besar dan lalu lintas tulis kecil. Namun, migrasi data diperlukan untuk membuat node baca-saja, yang membutuhkan waktu lama karena sinkronisasi data tambahan.
Scale-up melibatkan peningkatan spesifikasi yang ada. Proses ini mengurangi dampak pada bisnis, tetapi masalah sinkronisasi data dan latensi masih ada setelah pergantian antara database utama dan sekunder.
Oleh karena itu, metode peningkatan kapasitas harus ditentukan berdasarkan kondisi yang ada dan lalu lintas instance saat ini.
Metode apa yang digunakan untuk peningkatan kapasitas? Bagaimana cara memilih spesifikasi?
Setiap kali spesifikasi instance diubah, berbagai operasi manajemen dan O&M terlibat. Misalnya, mengubah spesifikasi database berbasis Docker melibatkan operasi tambahan seperti menghasilkan gambar Docker, memilih instance Elastic Compute Service (ECS), dan mengelola spesifikasi yang tersedia. Oleh karena itu, menggunakan spesifikasi yang tepat dapat mengurangi jumlah perubahan spesifikasi secara efektif, menghemat waktu untuk bisnis Anda.
Setelah utilisasi CPU mencapai 100% dan spesifikasi ditingkatkan, dua skenario mungkin terjadi. Dalam satu skenario, beban sumber daya komputasi berkurang dan lalu lintas bisnis stabil. Dalam skenario lain, utilisasi CPU tetap 100% karena lalu lintas meningkat, sehingga spesifikasi baru masih tidak memenuhi persyaratan kapasitas lalu lintas bisnis. Oleh karena itu, sumber daya tetap tidak cukup dan bisnis tetap terpengaruh.
Pengambilan keputusan tentang cara memilih spesifikasi tinggi yang tepat berdasarkan informasi operasi database memengaruhi hasil peningkatan kapasitas.
Solusi
DAS Auto Scaling membantu menangani ketiga tantangan teknis sebelumnya. Bagian berikut menjelaskan DAS Auto Scaling dari tiga aspek: kemampuan layanan, solusi, dan teknologi inti. Beberapa jenis database terlibat, seperti ApsaraDB RDS for MySQL, PolarDB for MySQL, dan ApsaraDB for Redis. Fitur-fitur seperti ekspansi penyimpanan otomatis, auto scaling untuk spesifikasi, dan penyesuaian bandwidth otomatis juga terlibat. Studi kasus disediakan di akhir topik ini untuk penjelasan lebih lanjut.
Kemampuan Layanan
Fitur ekspansi penyimpanan otomatis melakukan pra-peningkatan untuk meningkatkan ruang disk instance yang hampir mencapai batas atas spesifikasi saat ini, mencegah bisnis terpengaruh oleh ruang disk penuh. Anda dapat mengonfigurasi rasio ambang batas atau menggunakan ambang batas default 90% yang disediakan oleh DAS. Setelah ambang batas terlampaui, DAS meningkatkan kapasitas disk untuk instance tersebut.
DAS menyediakan fitur auto scaling untuk spesifikasi guna mengubah spesifikasi instance database secara otomatis. Fitur ini menyesuaikan sumber daya komputasi sehingga jumlah sumber daya yang sesuai digunakan untuk memproses permintaan aplikasi dalam beban bisnis. Anda dapat mengonfigurasi tingkat kejutan, durasi beban lalu lintas, dan spesifikasi maksimum, serta menentukan apakah akan kembali ke spesifikasi asli setelah perubahan.
DAS menyediakan fitur penyesuaian bandwidth otomatis untuk mengubah bandwidth instance database secara otomatis. Fitur ini menyesuaikan bandwidth ke spesifikasi yang sesuai, menyelesaikan masalah bandwidth yang tidak cukup.
DAS Auto Scaling menggunakan notifikasi untuk menampilkan kemajuan dan informasi status tugas Anda. Notifikasi dibagi menjadi tiga jenis: rekomendasi spesifikasi, status tugas, dan peristiwa yang dipicu oleh pengecualian. Notifikasi untuk peristiwa yang dipicu oleh pengecualian memberi tahu bahwa tugas mengubah spesifikasi telah dipicu. Notifikasi untuk rekomendasi spesifikasi menjelaskan spesifikasi asli dan yang diharapkan untuk ekspansi penyimpanan dan perubahan spesifikasi. Notifikasi untuk status tugas memberikan kemajuan dan informasi status tentang tugas Auto Scaling.
Solusi
Gambar berikut menunjukkan langkah-langkah untuk mengimplementasikan prosedur loop tertutup menggunakan DAS Auto Scaling.
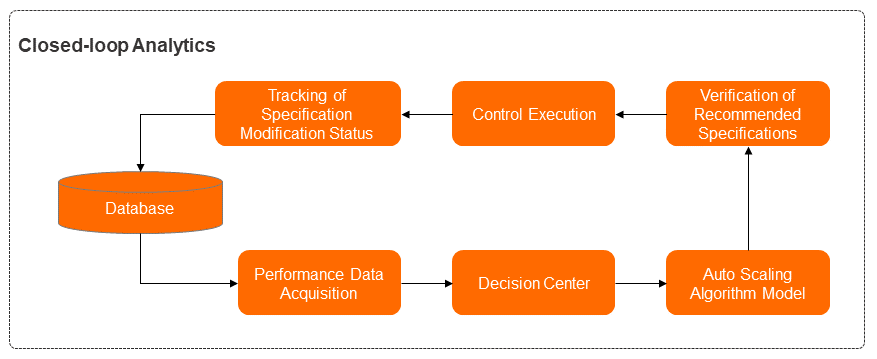
Prosedur loop tertutup melibatkan modul untuk pengumpulan data performa, pusat pengambilan keputusan, model algoritma, rekomendasi dan verifikasi spesifikasi, manajemen, dan pelacakan status. Masing-masing modul menyediakan fitur berikut:
Modul pengumpulan data performa mengumpulkan data performa waktu nyata dari instance, termasuk metrik performa, konfigurasi spesifikasi, dan informasi sesi tentang instance database yang beroperasi.
Modul pusat pengambilan keputusan membuat keputusan global berdasarkan data performa saat ini, daftar sesi instance, dan data lainnya untuk menangani tantangan pertama. Misalnya, jika sumber daya komputasi tidak cukup dan pembatasan SQL dapat menyelesaikan masalah, modul ini menentukan bahwa pembatasan SQL diaktifkan. Jika terjadi lonjakan lalu lintas bisnis, modul ini menentukan bahwa proses auto scaling dilanjutkan.
Modul model algoritma adalah inti dari fitur DAS Auto Scaling. Modul ini mengimplementasikan komputasi untuk mendeteksi anomali pada beban bisnis dan memberikan rekomendasi tentang spesifikasi kapasitas untuk instance database, membantu menangani tantangan kedua dan ketiga.
Modul rekomendasi dan verifikasi spesifikasi memberikan rekomendasi spesifik tentang spesifikasi dan memeriksa apakah spesifikasi yang direkomendasikan sesuai untuk jenis penyebaran dan lingkungan operasi aktual instance database. Modul ini juga memverifikasi apakah spesifikasi yang direkomendasikan termasuk dalam spesifikasi yang tersedia untuk wilayah saat ini, memastikan bahwa rekomendasi dapat diimplementasikan oleh modul manajemen.
Modul manajemen mendistribusikan dan mengimplementasikan rekomendasi spesifikasi yang disediakan.
Modul pelacakan status mengukur dan melacak perubahan performa yang terjadi pada instance database sebelum dan sesudah spesifikasi diubah.
Bagian berikut menjelaskan skenario bisnis dari tiga fitur yang didukung oleh DAS Auto Scaling: ekspansi penyimpanan otomatis, auto scaling untuk spesifikasi, dan penyesuaian bandwidth otomatis.
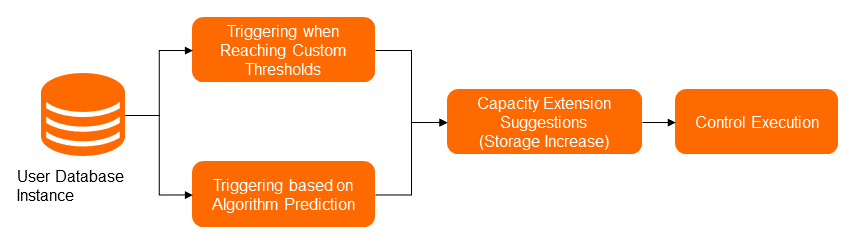
Gambar berikut menunjukkan solusi ekspansi penyimpanan. Ekspansi penyimpanan dipicu dengan dua cara: ambang batas yang ditentukan pengguna dan peramalan berbasis algoritma. Berdasarkan algoritma peramalan deret waktu dan ruang disk yang digunakan oleh instance database dalam periode sebelumnya, algoritma memprediksi ruang disk yang akan digunakan dalam periode berikutnya. Jika ruang disk yang digunakan melebihi spesifikasi disk instance dalam waktu singkat, ekspansi penyimpanan otomatis dipicu. Setiap kali ekspansi penyimpanan dilakukan, ruang disk ditingkatkan minimal 5 GB dan maksimal 15%, memastikan bahwa ruang disk instance database cukup.
Titik waktu implementasi fitur auto scaling pada disk ditentukan oleh ambang batas yang ditentukan dan hasil peramalan. Jika utilisasi disk meningkat perlahan hingga ambang batas yang ditentukan, seperti 90%, ekspansi penyimpanan dipicu. Jika utilisasi disk meningkat cepat dan algoritma memperkirakan bahwa kekurangan ruang akan terjadi dalam waktu singkat, Auto Scaling memberikan rekomendasi tentang ekspansi penyimpanan disk dan alasan yang sesuai.
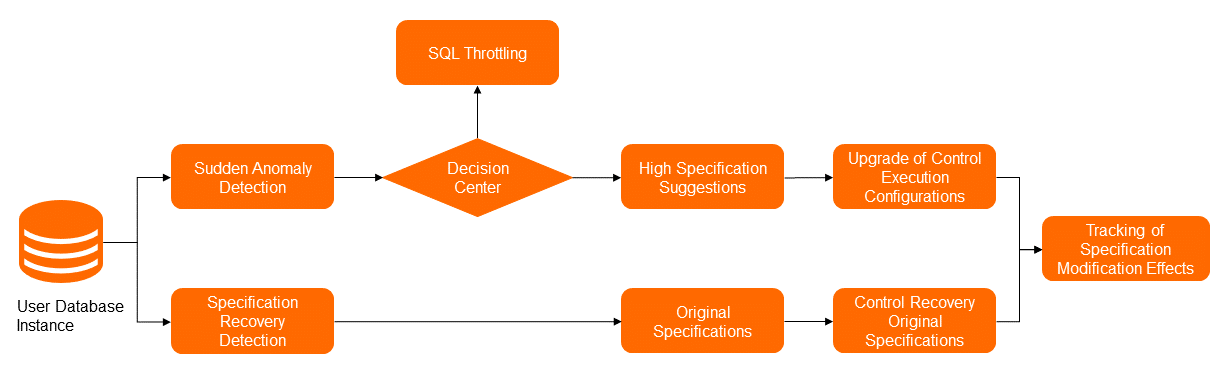
Gambar berikut menunjukkan solusi untuk auto scaling spesifikasi. Dalam proses mengubah spesifikasi, modul deteksi anomali mengidentifikasi pengecualian lalu lintas yang disebabkan oleh lonjakan lalu lintas bisnis dari berbagai dimensi, seperti permintaan per detik (QPS), transaksi per detik (TPS), sesi aktif, dan IOPS. Kemudian, pusat pengambilan keputusan menentukan apakah fitur auto scaling untuk spesifikasi akan diimplementasikan. Jika ya, modul rekomendasi spesifikasi memberikan rekomendasi spesifikasi tinggi, dan modul manajemen mengubah spesifikasi.
Setelah pengecualian lalu lintas berakhir, modul deteksi anomali mengidentifikasi bahwa lalu lintas kembali ke keadaan normal. Kemudian, modul manajemen menurunkan spesifikasi berdasarkan informasi spesifikasi asli yang disimpan dalam metadata. Setelah seluruh proses selesai, modul pelacakan status memberikan tren perubahan performa selama proses dan mengevaluasi hasilnya.
Untuk menentukan titik waktu yang tepat untuk memicu fitur auto scaling spesifikasi, DAS melakukan deteksi anomali pada berbagai metrik performa instance, seperti utilisasi CPU, disk IOPS, dan pembacaan logika instance. Sistem memicu fitur auto scaling spesifikasi berdasarkan durasi jendela observasi yang ditentukan. Setelah fitur dipicu, modul algoritma rekomendasi spesifikasi mengimplementasikan komputasi berdasarkan model yang telah dilatih, data performa saat ini, spesifikasi saat ini, dan data performa sebelumnya, memberikan spesifikasi instance yang sesuai untuk lalu lintas saat ini. Untuk menentukan titik waktu rollback ke spesifikasi asli, DAS mempertimbangkan durasi jendela observasi dalam periode tenang dan data performa instance. Setelah kondisi rollback terpenuhi, rollback dilakukan.
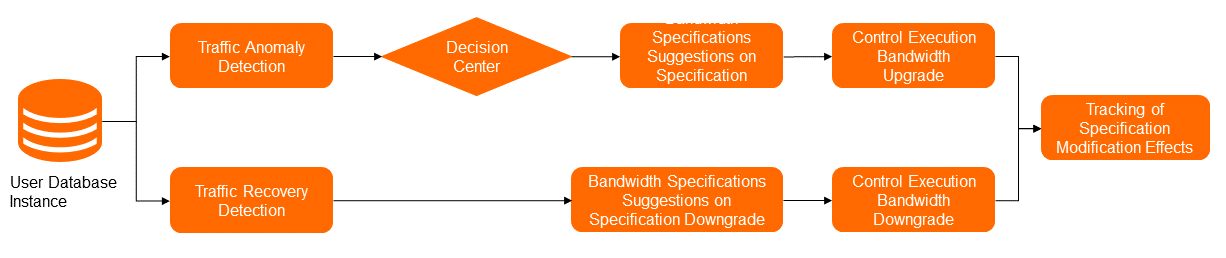
Gambar berikut menunjukkan solusi untuk penyesuaian bandwidth otomatis. Dalam proses mengubah bandwidth, modul deteksi anomali mendeteksi pengecualian lalu lintas berdasarkan penggunaan lalu lintas arah keluar dan arah masuk. Kemudian, pusat pengambilan keputusan menentukan apakah fitur penyesuaian bandwidth otomatis akan diimplementasikan untuk meningkatkan bandwidth. Jika ya, modul rekomendasi spesifikasi memberikan rekomendasi spesifikasi tinggi, dan modul manajemen meningkatkan bandwidth.
Setelah pengecualian lalu lintas berakhir, modul deteksi anomali mengidentifikasi bahwa lalu lintas kembali ke keadaan normal. Kemudian, modul manajemen menurunkan bandwidth berdasarkan informasi spesifikasi asli yang disimpan dalam metadata. Setelah seluruh proses selesai, modul pelacakan status memberikan tren perubahan performa selama proses dan mengevaluasi hasilnya.
Untuk menentukan titik waktu yang tepat untuk memicu fitur penyesuaian bandwidth otomatis, DAS melakukan deteksi anomali lalu lintas arah keluar dan arah masuk instance. Sistem memicu fitur penyesuaian bandwidth otomatis berdasarkan durasi jendela observasi yang ditentukan. Setelah fitur dipicu, modul algoritma rekomendasi spesifikasi mengimplementasikan komputasi berdasarkan model yang telah dilatih, data performa saat ini, spesifikasi bandwidth saat ini, dan data performa sebelumnya, memberikan spesifikasi bandwidth yang sesuai untuk lalu lintas saat ini. Untuk menentukan titik waktu rollback ke spesifikasi bandwidth asli, DAS mempertimbangkan data performa instance. Setelah kondisi rollback terpenuhi, rollback dilakukan.
Teknologi Inti
DAS Auto Scaling bergantung pada teknologi komprehensif yang dikembangkan oleh tim saluran data database Alibaba Cloud, tim manajemen, dan tim kernel. Fitur ini bergantung pada teknologi kunci berikut:
Pemantauan data instance database di seluruh jaringan dengan latensi beberapa detik. Saluran pemantauan dan pengumpulan data mengimplementasikan pengumpulan data, pemantauan, tampilan, dan diagnosis untuk instance database di seluruh jaringan dalam hitungan detik. Lebih dari 10 juta metrik pemantauan dapat diproses per detik secara real-time, meletakkan fondasi data yang kokoh untuk layanan database cerdas.
Aliran tugas manajemen terpadu tentang instance di seluruh jaringan. Aliran tugas manajemen melakukan operasi O&M pada instance di seluruh jaringan Alibaba Cloud, memastikan bahwa teknologi Auto Scaling diimplementasikan sesuai harapan.
Algoritma deret waktu untuk deteksi anomali berbasis peramalan dan pembelajaran mesin. Algoritma ini menyediakan berbagai fitur, seperti deteksi periodik, penentuan titik balik, dan identifikasi interval kontinu pengecualian. Algoritma ini dapat meramalkan data lebih dari 700.000 instance database online. Saat data diramalkan untuk hari berikutnya, jumlah instance dengan hasil kesalahan kurang dari 5% mencapai lebih dari 99%. Saat data diramalkan untuk periode yang terjadi 14 hari kemudian, jumlah instance dengan hasil kesalahan kurang dari 5% mencapai lebih dari 94%.
Model peramalan waktu respons database (RT) berbasis pembelajaran mendalam. Algoritma ini meramalkan RT instance berjalan berdasarkan berbagai metrik performa, seperti utilisasi CPU, pembacaan logika, pembacaan fisik, dan IOPS. Hasil peramalan digunakan sebagai referensi saat database mengurangi BufferPool memori, menghemat memori sebesar 27 TB untuk database Alibaba, mencakup sekitar 17% dari total memori.
Generasi berikutnya PolarDB for MySQL berbasis arsitektur komputasi awan. PolarDB for MySQL adalah database relasional yang disediakan oleh tim database Alibaba Cloud untuk era komputasi awan. Dalam database ini, node komputasi dipisahkan dari node penyimpanan, memberikan dukungan teknis yang kuat untuk Auto Scaling, mencegah overhead tambahan yang disebabkan oleh replikasi data dan penyimpanan, serta meningkatkan pengalaman pengguna secara signifikan.
Didukung oleh teknologi-teknologi sebelumnya, DAS Auto Scaling menyediakan fitur berbeda berdasarkan mesin yang berbeda, memastikan konsistensi dan integritas data selama auto scaling tanpa memengaruhi stabilitas bisnis. Dengan cara ini, bisnis Anda dilindungi. Tabel berikut menjelaskan fitur yang didukung untuk mesin database yang berbeda.
Fitur
Mesin database yang didukung
Auto scaling untuk spesifikasi
ApsaraDB RDS for MySQL Edisi High-availability yang menggunakan SSD standar atau SSD yang ditingkatkan (ESSD), ApsaraDB RDS for MySQL Edisi High-availability umum yang menggunakan disk lokal, dan ApsaraDB RDS for MySQL Edisi Enterprise umum
PolarDB for MySQL Edisi Kluster
ApsaraDB for Redis Edisi Komunitas dan ApsaraDB for Redis Edisi Enhanced yang dioptimalkan memori (Tair)
Ekspansi penyimpanan otomatis
ApsaraDB RDS for MySQL Edisi High-availability yang menggunakan SSD standar atau ESSD dan ApsaraDB RDS for MySQL Edisi Kluster
ApsaraDB RDS for PostgreSQL Edisi High-availability yang menggunakan SSD standar atau ESSD
ApsaraDB MyBase for MySQL Edisi High-availability yang menggunakan SSD standar atau ESSD dan ApsaraDB MyBase for MySQL Edisi High-availability yang menggunakan disk lokal
Penyesuaian bandwidth otomatis
ApsaraDB for Redis yang menggunakan disk lokal
Studi kasus
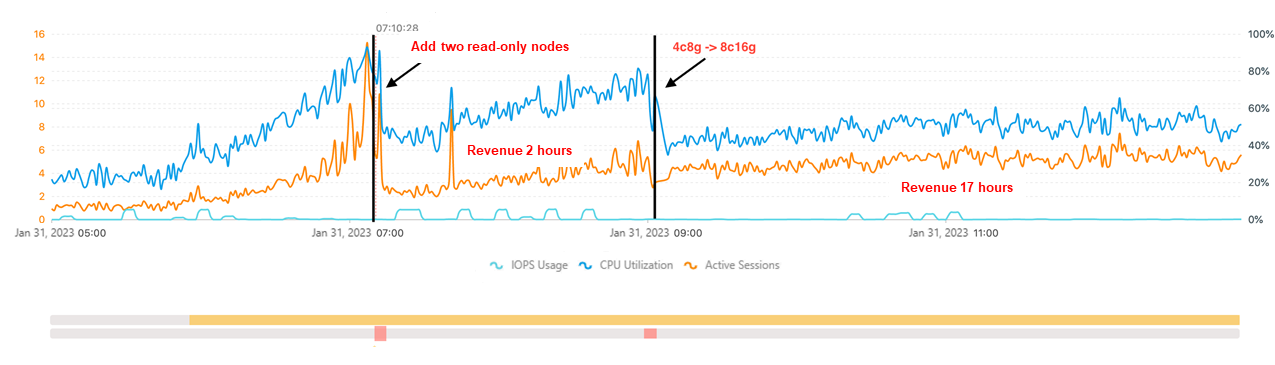
Contoh berikut menunjukkan cara menggunakan fitur Auto Scaling. Instance Apsara RDS for MySQL digunakan dalam contoh ini. Jendela observasi dengan durasi 15 menit dikonfigurasikan, dan ambang batas utilisasi CPU diatur ke 80%.
Pada gambar sebelumnya, utilisasi CPU dan jumlah sesi aktif melonjak akibat pengecualian lalu lintas pada pukul 07:10. Utilisasi CPU mencapai 80%, menunjukkan bahwa sumber daya relatif tidak cukup. Analisis terhadap lalu lintas baca dan tulis instance menunjukkan bahwa lalu lintas saat itu terutama digunakan untuk membaca data. Algoritma DAS Auto Scaling menentukan bahwa utilisasi CPU dapat dikurangi menjadi 60% dengan menambahkan dua node baca-saja. Setelah implementasi, masalah kekurangan sumber daya terselesaikan. Namun, utilisasi CPU melonjak lagi karena peningkatan bisnis pada pukul 09:00. Dalam hal ini, sumber daya kembali tidak cukup. Analisis menunjukkan bahwa lalu lintas saat itu terutama digunakan untuk menulis data. Algoritma DAS Auto Scaling menentukan bahwa utilisasi CPU dapat dikurangi menjadi 50% dengan meningkatkan spesifikasi sumber daya komputasi. Setelah implementasi, masalah kekurangan sumber daya terselesaikan kembali.
Contoh ini menunjukkan bahwa DAS Auto Scaling dapat secara proaktif memecahkan masalah kekurangan sumber daya dan secara efektif memastikan stabilitas bisnis database.