Kluster ACS mendukung penjadwalan beberapa Pod GPU ke satu node GPU-HPN. Pod tersebut dapat menggunakan teknologi seperti NVLink untuk mentransfer data antar-GPU. Untuk memastikan komunikasi yang efisien dan adil antar perangkat GPU, ACS menjadwalkan perangkat berdasarkan batasan partisi dari berbagai tipe node. Topik ini menjelaskan mekanisme penjadwalan partisi untuk GPU ACS dan menyediakan skenario contoh.
Prasyarat
Hanya Pod dengan kelas komputasi gpu-hpn dan tipe node yang sesuai yang didukung.
Latar Belakang
Perangkat GPU pada suatu node menggunakan satu atau beberapa saluran untuk saling terhubung dan berkomunikasi. ACS mendukung penempatan Pod dengan kebutuhan GPU berbeda pada satu node GPU-HPN yang sama. Untuk memastikan komunikasi GPU yang efisien dan adil serta mencegah gangguan antar-Pod, ACS menjadwalkan Pod berdasarkan topologi GPU. Bergantung pada jumlah GPU yang diminta, ACS membagi GPU pada node menjadi beberapa partisi dan menetapkan set perangkat yang optimal.
Gambar berikut menunjukkan sebuah node dengan delapan GPU, yang dikelompokkan dalam dua kelompok masing-masing empat GPU. Di dalam setiap kelompok, GPU saling terhubung secara langsung, sedangkan kedua kelompok tersebut saling terhubung melalui PCIe.
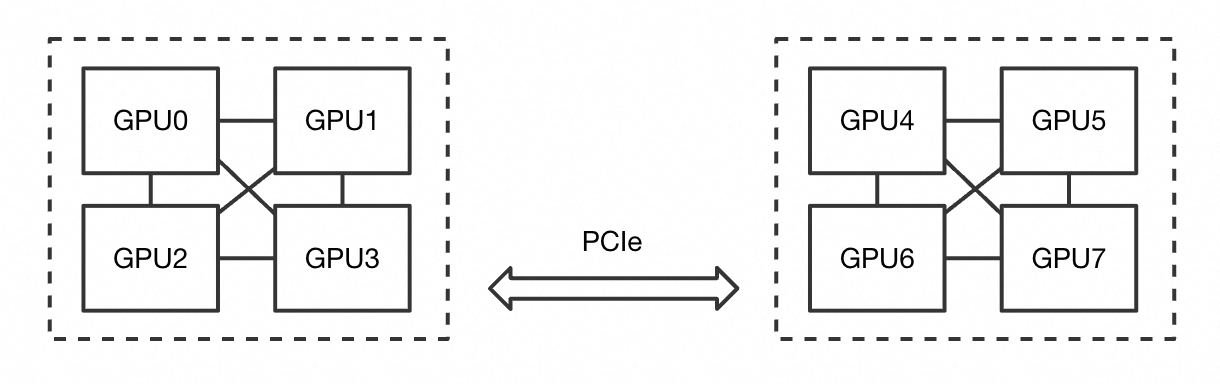
Partisi ACS dibagi sebagai berikut berdasarkan spesifikasi Pod.
Jumlah GPU yang diminta oleh Pod | Hasil penugasan perangkat yang mungkin |
8 | [0,1,2,3,4,5,6,7] |
4 | [0,1,2,3], [4,5,6,7] |
2 | [0,1], [2,3], [4,5], [6,7] |
1 | [0], [1], [2], [3], [4], [5], [6], [7] |
Saat Pod dibuat dan dihapus pada suatu node, perangkat GPU dapat terfragmentasi menjadi partisi yang tidak dapat digunakan. Fragmentasi ini dapat mencegah penjadwalan Pod baru, sehingga Pod tersebut tetap dalam status Pending. Untuk mengatasi hal ini, Anda dapat memeriksa penugasan perangkat pada Pod yang ada dan mengeluarkan (evict) beberapa di antaranya berdasarkan prioritas bisnis Anda. Tindakan ini membebaskan sumber daya bagi Pod yang tertunda.
Memeriksa partisi pada node GPU-HPN
Partisi dan tipe kartu GPU bervariasi pada berbagai model node GPU-HPN ACS.
gpu.p16en-16XL
Node ini memiliki 16 GPU tipe P16EN. Untuk Pod dengan kebutuhan GPU berbeda, partisi dibuat sebagai berikut.
Jumlah GPU yang diminta oleh Pod | Hasil alokasi perangkat (Opsional) |
16 | [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15] |
8 | [0,1,2,3,4,5,6,7], [8,9,10,11,12,13,14,15] |
4 | [0,1,2,3], [4,5,6,7], [8,9,10,11], [12,13,14,15] |
2 | [0,3], [1,2], [4,7], [5,6], [8,11], [9,10], [12,15], [13,14] |
1 | [0], [1], [2], [3], [4], [5], [6], [7], [8], [9], [10], [11], [12], [13], [14], [15] |
Kueri hasil penjadwalan Pod
Hasil penugasan perangkat
Untuk Pod GPU-HPN, Anda dapat menemukan hasil penugasan perangkat pada anotasi Pod. Formatnya adalah sebagai berikut.
apiVersion: v1
kind: Pod
metadata:
annotations:
alibabacloud.com/device-allocation: '{"gpus": {"minor": [0,1,2,3]}}'Pesan kegagalan penjadwalan akibat fragmentasi partisi
Jika sebuah Pod tidak dapat dijadwalkan, statusnya tetap Pending. Anda dapat menjalankan perintah kubectl describe pod untuk melihat alasannya. Pesan seperti 0/5 nodes are available: xxx yang mencakup Insufficient Partitioned GPU Devices menunjukkan bahwa penjadwalan gagal karena fragmentasi sumber daya GPU pada node. Berikut adalah contohnya.
kubectl describe pod pod-demoBerikut adalah contoh output. Bagian lainnya dihilangkan.
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 26m default-scheduler 0/5 nodes are available: 2 Node(s) Insufficient Partitioned GPU Devices, 1 Node(s) xxx, 2 Node(s) xxx.FAQ
Bagaimana cara merencanakan sumber daya node dan kebijakan untuk menghindari fragmentasi partisi?
Anda dapat menetapkan tag grup berbeda untuk node guna mengelola sumber daya berdasarkan jumlah GPU yang dibutuhkan oleh Pod aplikasi Anda. Misalnya, jadwalkan tugas besar yang memerlukan delapan GPU dan tugas kecil yang memerlukan satu GPU ke node yang berbeda.
Jika terdapat Pod yang tertunda di kluster akibat fragmentasi, Anda dapat menggunakan mekanisme seperti descheduling untuk mengeluarkan tugas berprioritas rendah. Hal ini membebaskan sumber daya bagi Pod yang tertunda.
Jika kluster Anda memiliki jumlah node yang sedikit, Anda tidak dapat menggunakan tag grup untuk perencanaan, dan aplikasi Anda memiliki kebutuhan GPU yang beragam, Anda dapat menggunakan GPU pod capacity reservation untuk memenuhi permintaan sumber daya.
Bagaimana memilih Pod mana yang harus dikeluarkan untuk mengatasi fragmentasi partisi?
Tentukan spesifikasi sumber daya Pod yang tertunda, misalnya delapan GPU.
Periksa anotasi Pod pada node target. Temukan hasil penugasan perangkat pada properti
alibabacloud.com/device-allocation.Berdasarkan hasil penugasan tersebut, identifikasi Pod yang akan dikeluarkan. Pastikan perangkat yang dibebaskan memenuhi kebutuhan sumber daya dan batasan partisi dari Pod yang tertunda. Misalnya, permintaan delapan GPU P16EN mengharuskan semua perangkat [0,1,2,3,4,5,6,7] atau [8,9,10,11,12,13,14,15] tidak ditugaskan.
Keluarkan Pod tersebut menggunakan perintah seperti
evictataudelete.
Apa yang perlu diketahui tentang partisi saat menggunakan penjadwal kustom?
Saat penjadwal kustom menetapkan Pod ke suatu node, ACS menangani alokasi perangkat untuk Pod tersebut pada node tersebut. Selama alokasi, ACS berusaha mengemas Pod secara rapat untuk mencegah fragmentasi.
Penjadwal kustom hanya perlu mempertimbangkan kapasitas GPU total suatu node. Untuk sumber daya GPU, prioritaskan kebijakan penjadwalan node MostAllocated. Hal ini membantu mengurangi fragmentasi partisi.
Bagaimana penjadwal berbeda menangani kesadaran topologi GPU HPN ACS?
Tipe penjadwal | Kondisi | Deskripsi |
Penjadwal default ACS | Semua kondisi berikut terpenuhi:
Salah satu kondisi berikut terpenuhi:
Untuk informasi selengkapnya, lihat kube-scheduler. | Penjadwal menyadari alokasi partisi saat ini pada node. Node yang tidak memenuhi persyaratan partisi tidak dipertimbangkan untuk penjadwalan. Event yang sesuai untuk kegagalan penjadwalan Pod mencakup pesan |
Penjadwal default ACK | Semua kondisi berikut terpenuhi:
Untuk informasi selengkapnya, lihat kube-scheduler. | |
Kasus yang tidak memenuhi tipe penjadwal, kondisi, atau konfigurasi di atas | Penjadwal tidak menyadari topologi partisi. Node GPU-HPN berusaha mengemas perangkat selama alokasi. Jika persyaratan partisi tidak terpenuhi, Pod tetap dalam status Pending pada node hingga persyaratan tersebut terpenuhi. Pesan yang sesuai mencakup | |