Topik ini menjelaskan cara menggunakan DataWorks untuk menyinkronkan data dari MaxCompute ke ApsaraDB for ClickHouse.
Informasi latar belakang
Anda dapat menggunakan fitur penyinkronan data batch DataWorks untuk menyinkronkan data dari berbagai sumber data ke ApsaraDB for ClickHouse. Untuk informasi lebih lanjut tentang sumber data yang didukung oleh penyinkronan data batch, lihat Tipe Sumber Data yang Didukung, Plugin Reader, dan Plugin Writer.
Prasyarat
Ruang kerja DataWorks telah dibuat dan MaxCompute dipilih sebagai mesin komputasi. Untuk informasi lebih lanjut, lihat Buat Ruang Kerja.
Grup sumber daya eksklusif untuk Data Integration telah dibuat dan dikonfigurasi. Untuk informasi lebih lanjut, lihat Buat dan Gunakan Grup Sumber Daya Eksklusif untuk Data Integration.
Kluster ApsaraDB for ClickHouse telah dibuat, serta nama pengguna dan kata sandi akun database telah ditetapkan. Untuk informasi lebih lanjut, lihat Buat Kluster ApsaraDB for ClickHouse dan Kelola Akun Database Kluster ApsaraDB for ClickHouse.
Anda memiliki izin untuk masuk ke database. Untuk informasi lebih lanjut, lihat Berikan Izin.
Jika pengguna RAM ingin menggunakan DataWorks, pemilik akun Alibaba Cloud harus menetapkan peran kepada pengguna RAM. Untuk informasi lebih lanjut, lihat Tambah Anggota Ruang Kerja dan Tetapkan Peran Kepada Mereka.
Catatan penggunaan
ApsaraDB for ClickHouse hanya mendukung grup sumber daya eksklusif untuk Data Integration.
Jika Anda ingin menyinkronkan tabel yang sebelumnya telah disinkronkan, jalankan pernyataan
TRUNCATE TABLE <Nama Tabel>;untuk menghapus data yang telah disinkronkan dalam tabel ApsaraDB for ClickHouse.
Prosedur
Tambahkan Sumber Data.
Anda perlu menambahkan sumber data untuk MaxCompute dan ApsaraDB for ClickHouse.
CatatanUntuk informasi lebih lanjut, lihat Tambahkan Sumber Data MaxCompute dan Tambahkan Sumber Data ClickHouse.
Buat Tabel MaxCompute.
Masuk ke Konsol DataWorks.
Di panel navigasi kiri, klik Workspace.
Di bilah navigasi atas, pilih wilayah tempat workspace yang diinginkan berada.
Pada halaman Workspaces, temukan workspace dan pilih di kolom Actions.
Pada halaman DataStudio, gerakkan pointer di atas ikon
 dan pilih .
dan pilih .Dalam kotak dialog Create Table, pilih jalur dari daftar drop-down Path dan konfigurasikan parameter Name. Dalam contoh ini, odptabletest1 digunakan sebagai nama tabel. Klik Create.
Dalam bagian General, konfigurasikan parameter.

Tabel berikut menjelaskan parameter.
Parameter
Deskripsi
Nama Tampilan
Nama tampilan tabel.
Tema
Folder yang digunakan untuk menyimpan dan mengelola tabel. Anda dapat menentukan folder level-1 dan level-2 untuk menyimpan tabel. Parameter Tema Level-1 dan Tema Level-2 dapat digunakan untuk mengkategorikan tabel berdasarkan kategori bisnis. Anda dapat menyimpan tabel dengan kategori bisnis yang sama di folder yang sama.
CatatanTema level-1 dan level-2 di panel Tabel Workspace halaman DataStudio membantu Anda mengelola tabel di folder dengan lebih baik. Anda dapat dengan cepat menemukan tabel saat ini di panel Tabel Workspace berdasarkan tema. Jika tidak ada tema yang tersedia, Anda dapat membuat satu. Untuk informasi tentang cara membuat tema, lihat bagian Buat atau kelola folder untuk tabel dari topik "Kelola pengaturan untuk tabel".
Klik DDL di toolbar.
Dalam kotak dialog DDL, masukkan pernyataan berikut dan klik Generate Table Schema:
CREATE TABLE IF NOT EXISTS odptabletest1 ( v1 TINYINT, v2 SMALLINT );Klik Commit to Development Environment dan kemudian Commit to Production Environment.
Tulis Data ke Tabel MaxCompute.
Pada halaman DataStudio, klik Ad Hoc Query di panel navigasi kiri.
Gerakkan pointer di atas ikon
 dan pilih .
dan pilih .Dalam kotak dialog Create Node, pilih jalur dari daftar drop-down Path dan konfigurasikan parameter Name.
Klik Confirm.
Pada halaman edit node, masukkan pernyataan berikut untuk menulis data ke tabel MaxCompute:
insert into odptabletest1 values (1,"a"),(2,"b"),(3,"c"),(4,"d");Klik ikon
 di toolbar.
di toolbar.Dalam kotak dialog Estimate MaxCompute Computing Cost, klik Run.
Buat ApsaraDB for ClickHouse tabel.
Masuk ke Konsol ApsaraDB for ClickHouse.
Di bilah navigasi atas, pilih wilayah tempat kluster yang diinginkan diterapkan.
Pada halaman Clusters, klik tab berdasarkan edisi kluster Anda dan klik ID kluster yang ingin Anda kelola.
Pada halaman Cluster Information, klik Log On to Database di pojok kanan atas.
Dalam kotak dialog Log on to Database Instance, masukkan nama pengguna dan kata sandi akun database Anda dan klik Login.
Masukkan pernyataan berikut dan klik Execute(F8). Contoh pernyataan:
create table default.dataworktest ON CLUSTER default ( v1 Int, v2 String ) ENGINE = MergeTree ORDER BY v1;CatatanTipe skema tabel ApsaraDB for ClickHouse harus memetakan tipe skema tabel MaxCompute.
Buat Alur Kerja.
Jika Anda sudah memiliki workflow, lewati langkah ini.
Pada halaman DataStudio, klik Scheduled Workflow di panel navigasi kiri.
Gerakkan pointer di atas ikon
dan pilih Create Workflow.Dalam kotak dialog Create Workflow, konfigurasikan parameter Workflow Name.
PentingNama tersebut harus memiliki panjang 1 hingga 128 karakter dan dapat berisi huruf, digit, garis bawah (_), dan titik (.).
Klik Create.
Buat Node Sinkronisasi Batch.
Klik alur kerja yang baru dibuat dan klik kanan Data Integration.
Pilih .
Dalam kotak dialog Create Node, konfigurasikan parameter Name, dan pilih jalur dari daftar drop-down Path.
PentingNama node harus memiliki panjang 1 hingga 128 karakter dan dapat berisi huruf, digit, garis bawah (_), dan titik (.).
Klik Confirm.
Konfigurasikan Sumber Data dan Tujuan.
Sumber: Pilih sumber data yang didukung. Dalam contoh ini, MaxCompute dipilih.
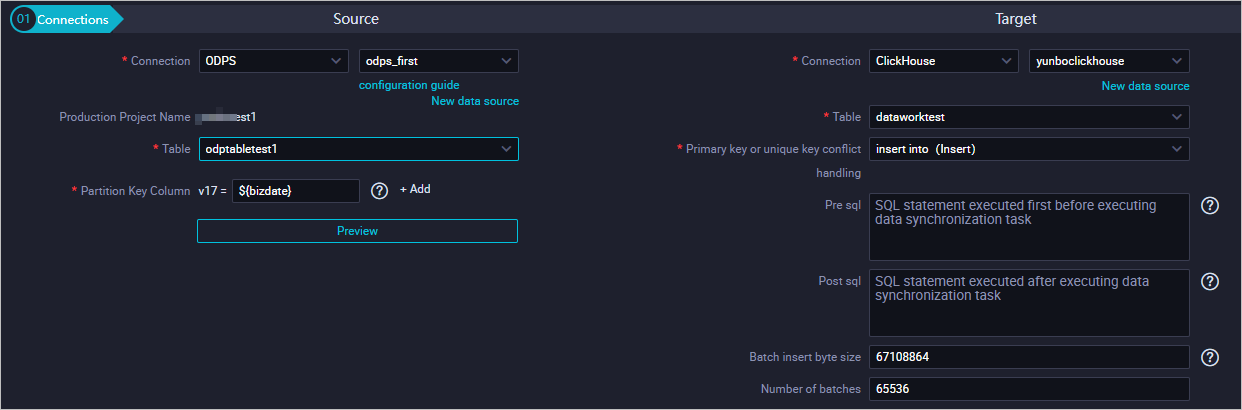
Tabel berikut menjelaskan parameter.
Parameter
Deskripsi
Connection
Tipe dan nama sumber data.
Production Project Name
Nama proyek dalam lingkungan produksi. Anda tidak dapat mengubah nilai ini.
Table
Tabel yang ingin Anda sinkronkan.
Partition Key Column
Jika data tambahan harian Anda disimpan dalam partisi tanggal tertentu, Anda dapat menentukan informasi partisi untuk menyinkronkan data tambahan harian. Misalnya, atur v17 menjadi ${bizdate}.
CatatanDataWorks tidak dapat memetakan bidang dalam tabel MaxCompute yang dipartisi. Jika Anda ingin membaca data dari tabel MaxCompute yang dipartisi, Anda harus menentukan setiap partisi yang diinginkan saat mengonfigurasi MaxCompute Reader.
CatatanUntuk informasi lebih lanjut tentang parameter, lihat MaxCompute Reader.
Tujuan: Pilih ClickHouse.
Tabel berikut menjelaskan parameter.
Parameter
Deskripsi
Connection
Tipe dan nama sumber data. Pilih ClickHouse.
Table
Tabel ke mana Anda ingin mengimpor data yang disinkronkan.
Primary key or unique key conflict handling
Atur nilai ini ke insert into (Insert).
Pre sql
Pernyataan SQL yang ingin Anda jalankan sebelum tugas sinkronisasi dijalankan.
Post sql
Pernyataan SQL yang ingin Anda jalankan setelah tugas sinkronisasi dijalankan.
Batch insert byte size
Jumlah maksimum byte yang akan dimasukkan.
Number of batches
Jumlah entri data yang akan dimasukkan dalam satu batch.
(Opsional) Mappings: Anda dapat memilih pemetaan bidang. Field di sisi kiri sesuai dengan Field di sisi kanan.
 Catatan
CatatanUntuk informasi tentang parameter, lihat bagian Langkah 4: Konfigurasikan Pemetaan antara Bidang Sumber dan Bidang Tujuan dari topik Konfigurasikan Tugas Sinkronisasi Batch Menggunakan Antarmuka Tanpa Kode.
(Opsional) Channel: Konfigurasikan laju transmisi maksimum dan aturan pemeriksaan data kotor.
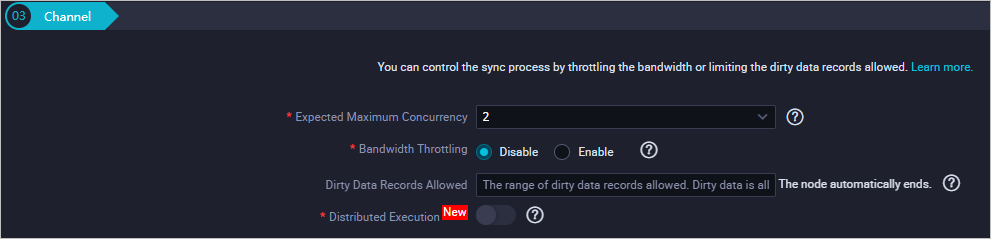 Catatan
CatatanUntuk informasi tentang parameter, lihat bagian Langkah 5: Konfigurasikan Kebijakan Kontrol Saluran dari topik Konfigurasikan Tugas Sinkronisasi Batch Menggunakan Antarmuka Tanpa Kode.
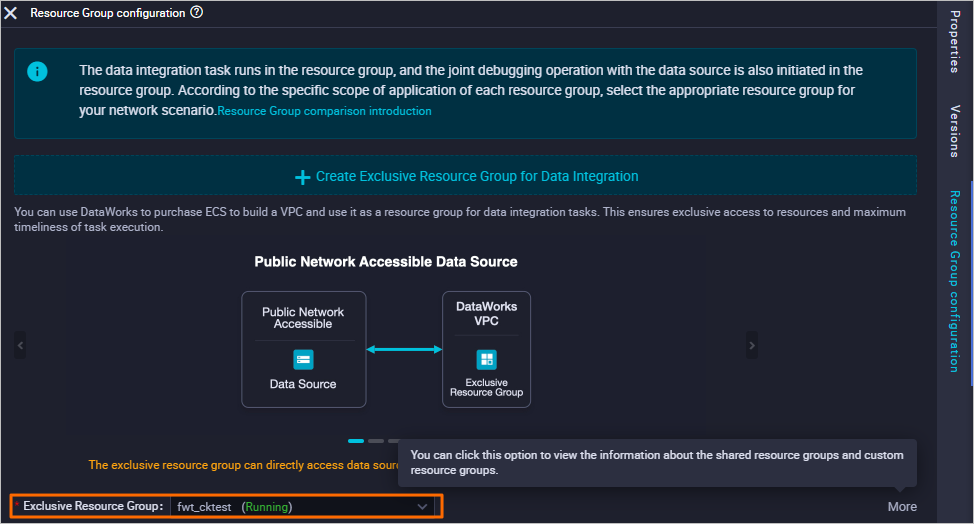
Konfigurasikan Grup Sumber Daya untuk Data Integration.
Klik Resource Group configuration di sebelah kanan dan pilih grup dari daftar drop-down Exclusive Resource Group.
Jalankan dan Simpan Tugas Sinkronisasi.
Klik ikon
 di toolbar untuk menyimpan tugas sinkronisasi.
di toolbar untuk menyimpan tugas sinkronisasi.Klik ikon
 di toolbar untuk menjalankan tugas sinkronisasi.
di toolbar untuk menjalankan tugas sinkronisasi.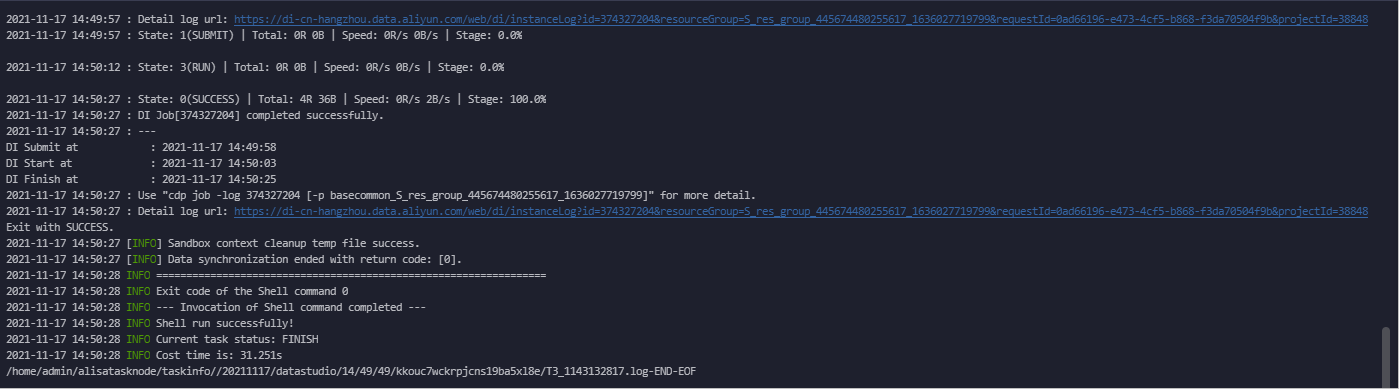
Verifikasi hasil sinkronisasi data
Masuk ke Konsol ApsaraDB for ClickHouse.
Di bilah navigasi atas, pilih wilayah tempat kluster yang diinginkan diterapkan.
Pada halaman Clusters, klik tab berdasarkan edisi kluster Anda dan klik ID kluster yang ingin Anda kelola.
Pada halaman Cluster Information, klik Log On to Database di pojok kanan atas.
Dalam kotak dialog Log on to Database Instance, masukkan nama pengguna dan kata sandi akun database Anda dan klik Login.
Masukkan pernyataan kueri berikut dan klik Eksekusi(F8) untuk memeriksa apakah data telah disinkronkan:
SELECT * FROM dataworktest;Hasil berikut dikembalikan.
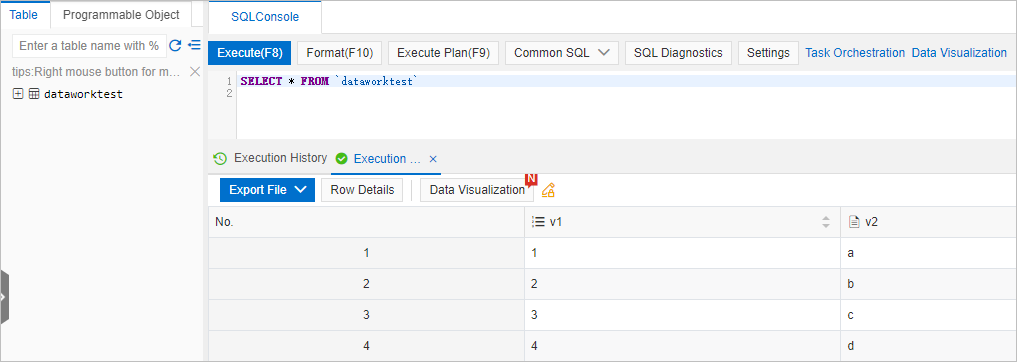 Catatan
CatatanJika hasil dikembalikan setelah Anda menjalankan pernyataan kueri, data telah disinkronkan dari MaxCompute ke ApsaraDB for ClickHouse.